




 本文详细介绍了线性回归算法,重点讲述了算法思想、适用数据类型、二元和n元线性回归的数学表达式,以及损失函数和优化方法,包括最小二乘法和梯度下降。文中通过波士顿房价预测案例展示了线性回归在实际问题中的应用。
本文详细介绍了线性回归算法,重点讲述了算法思想、适用数据类型、二元和n元线性回归的数学表达式,以及损失函数和优化方法,包括最小二乘法和梯度下降。文中通过波士顿房价预测案例展示了线性回归在实际问题中的应用。
算法思想: 根据历史数据,找到最佳的一组权重 w,和偏置b,根据?_1 ?_1+?_2 ?_2+…+?_? ?_?+? 求出目标值,在计算loss损失,在梯度下降 ,调整w权重。
该算法针对于 连续型,非离散型数据
二元线性回归:(样本就2个特征)
目标值 = 权重1 * 特征值1 + 权重2 * 特征值2 +b
n元线性回归(样本选择n个特征)
目标值 = 权重1 * 特征值1 + 权重2 * 特征值2 +·········+ 权重n * 特征值n+b
公式
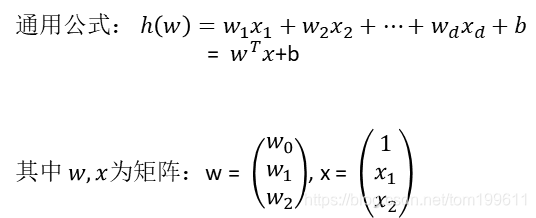
运算。
X = [[1,2,3], [4,5,6], [7,8,9], [6,6,1]]
行=样本数,列= 选取的特征数量
最终结果的形状是 二维 [4,1] 有4个样本,每个样本一个输出
w的形状 二维的[3,1]
w = [[w1],[w2],[w3]] 和特征数量一致
b = [[b1],[b2],[b3],[b4]] 每个样本都有一个偏置量
结果 = np.matmul(x,w) + b
loss损失函数??
使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 888
888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









