




目录
Scrapy框架
Scrapy是一个非常优秀的爬虫框架,通过Scrapy框架,可以非常轻松地实现非常强大的爬虫系统,程序员只要注意抓取规则和如何处理数据上,至于抓取页面、保存数据、任务调度、分布式等,直接交给Scrapy就可以了。
scrapy主要构成部分
1、Scrapy Engine(引擎):用来处理整个系统的数据流,出发各种事件
2、Scheduler(调度器):从URL队列中取出一个URL
3、Downloader(下载器):从Internet上下载Web数据
4、Spider(网络爬虫):接收下载器下载的原始数据,做进一步的处理,例如,使用XPath提取感兴趣的信息
5、Item Pipeline(项目管道):接收网络爬虫传过来的数据,以便作进一步的处理。例如,存入数据库,存入文本文件
6、中间件:整个Scrapy框架有很多中间件,如下载器中间件、网络爬虫中间件等,这些中间件相当于过滤器,夹在不同部分之间截获数据流,并进行特殊处理
Scrapy流程介绍
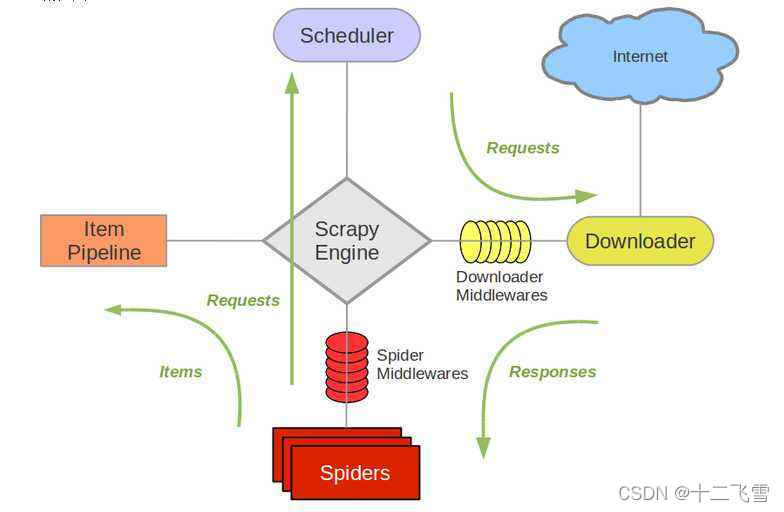
- 整体在Scrapy Engine的调度下,首先运行的是Scheduler,Scheduler从下载队列中去一个URL,将这个URL交给Downloader,Downloader下载整个URL对应的Web资源
- 然后将下载的原始数据交给Spiders,Spiders会从原始数据中提取出有用的信息
- 最后将提取出的数据交给Item Pipeline,这是一个数据管道,可以通过Item Pipeline将数据保存到数据库、文本文件或其他存储介质上。
实际上,Scrapy 提供一个Shell,相当于Python的REPL环境,可以用Scrapy Shell测试Scrapy代码
在终端输入scrapy shell就可以进去shell模式
创建一个Scrapy项目
- 首先使用pip在python环境中安装scrapy的库
pip install scrapy - 其次进入目录后,在终端输入scrapy startproject myscrapy命令,按回车创建scrapy项目
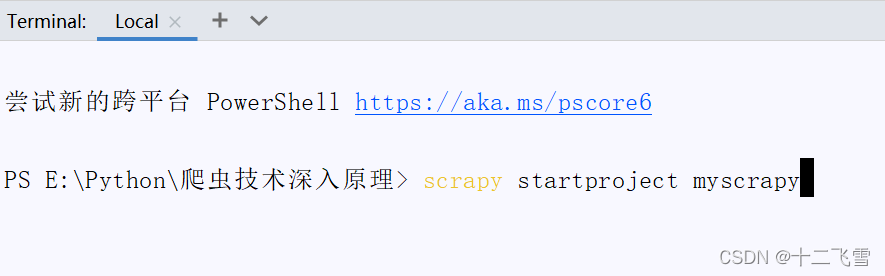
- 创建成功

17.1 通过Scrapy抓取数据
本例通过XPAth过滤出指定页面的博文列表,并利用Beautiful Soup对博文的相关信息进一步过滤,最后输出信息
import scrapy
from bs4 import *
class BlogSpider(scrapy.Spider):
name = 'BlogSpider'
start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori']
def parse(self, response):
# 过滤出指定页面所有的博文
sectionList = response.xpath('//*[@id="all"]/div[1]/section').extract()
# 对博文列表进行迭代
for section in sectionList:
# 利用BeautifulSoup对每一篇博文的相关信息进行过滤
bs = BeautifulSoup(section,'lxml')
articleDict = {}
a = bs.find('a')
# 获取博文的标题
articleDict['title'] = a.text
# 获取博文的URL
articleDict['href'] = 'https://geekori.com/' + a.get('href')
p = bs.find('p', class_='excerpt')
# 获取博文的摘要
articleDict['abstract'] = p.text
print(articleDict)
问题来了,如何执行这个框架?
在如下目录中新建一个exec_Blog.PY的文件,并输入
from scrapy import cmdline
cmdline.execute('scrapy crawl BlogSpider'.split())
即可进行抓取。
17.2 将Scrapy抓取的数据以多种形式保存
关于parse方法的内容:
- parse方法的返回值会被传给Item Pipeline,并由响应的Item Pipeline将数据保存成响应格式的文件。
- parse方法必须返回Item类型的数据。先定义一个Item类,在parse方法中返回Item类的实例
- 最后在运行网络爬虫是会通过“-o”命令行参数指定保存的文件类型,成功运行后,就会将抓取的数据保存在指定文件中
第一步 编写Item文件存储格式:
加入这一条关于博客信息的类:
class mycrapyItem(scrapy.Item):
# 每一个要保存的属性都必须是Field的实例
title = scrapy.Field()
href = scrapy.Field()
abstract = scrapy.Field()
第二步 编写爬虫文件:
import scrapy
from bs4 import *
from shitscrapy.items import ShitscrapyItem
class SaveBlogSpider(scrapy.Spider):
name = 'SaveBlogSpider'
start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori']
def parse(self, response):
# 创建MyscrapyItem类的实例
item = ShitscrapyItem()
sectionList = response.xpath('//*[@id="all"]/div[1]/section').extract()
for section in sectionList:
bs = BeautifulSoup(section,'lxml')
articleDict = {}
# 搜索a标签
a = bs.find('a')
# 下面的代码将a标签的属性值保存在字典中
articleDict['title'] = a.text
articleDict['href'] = 'https://geekori.com/' + a.get('href')
p = bs.find('p',class_='excerpt')
articleDict['abstract'] = p.text
# 为Item的三个属性赋值
item['title'] = articleDict['title']
item['href'] = articleDict['href']
item['abstract'] = articleDict['abstract']
# break
# 返回MyscrapyItem对象
return item
第三步 编写执行文件
from scrapy import cmdline
# 将抓取的数据保存为json格式的文件(blog.json)
cmdline.execute('scrapy crawl SaveBlogSpider -o blog.json'.split())
第四步 查看json文件
[
{"title": "Android\u7684init\u8fc7\u7a0b\u8be6\u89e3\uff08\u4e00\uff09",
"href": "https://geekori.com/blogDetails.php?blog_id=36",
"abstract": "\r\n \u672c\u6587\u53ca\u540e\u7eed\u51e0\u7bc7\u6587\u7ae0\u5c06\u5bf9Android\u7684\u521d\u59cb\u5316\uff08init\uff09\u8fc7\u7a0b\u8fdb\u884c\u8be6\u7ec6\u5730\u3001\u5265\u4e1d\u62bd\u8327\u5f0f\u5730\u5206\u6790\uff0c\u5e76\u4e14\u5728\u5176\u4e2d\u7a7f\u63d2\u4e86\u5927\u91cf\u7684\u77e5\u8bc6\uff0c\u5e0c\u671b\u5bf9\u8bfb\u8005\u4e86\u89e3Android\u7684\u542f\u52a8\u8fc7\u7a0b\u53c8\u6240\u5e2e\u52a9\u3002\u672c\u7ae0\u4e3b\u8981\u4ecb\u7ecd\u4e86\u4e0e\u786c\u4ef6\u76f8\u5173\u521d\u59cb\u5316\u6587\u4ef6\u540d\u7684\u786e\u5b9a\u4ee5\u53ca\u5c5e\u6027\u670d\u52a1\u7684\u539f\u7406\u548c\u5b9e\u73b0\u3002"}
]
17.3 使用ItemLoader保存单条数据
通过ItemLoader对象以及XPath截取文章列表的第一篇文章的标题、摘要以及URL,通过-o命令行参数指定保存的文件类型
class ItemLoaderSpider(scrapy.Spider):
name = 'ItemLoaderSpider'
# 定义要抓取的Web资源的URL
start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori']
def parse(self, response):
# 创建ItemLoader对象
itemloader = ItemLoader(item = ShitscrapyItem(),response=response)
# 通过XPath获取标题
itemloader.add_xpath('title','//*[@id="all"]/div[1]/section[1]/div[2]/h2/a/text()')
itemloader.add_xpath('href','//*[@id="all"]/div[1]/section[1]/div[2]/h2/a/@href',
MapCompose(lambda href:'https://geekori.com/' + href))
itemloader.add_xpath('abstract','//*[@id="all"]/div[1]/section[1]/div[2]/p/text()')
# 通过load_item方法获得SHitScrapy对象,并返回这个对象
return itemloader.load_item()
由于创建itemloader对象是已经指定了response,所以通过xpath获取特定内容就不需要再考虑response了,都被封装在类中
# 文件名称:execute_ItemLoaderSpider.PY
from scrapy import cmdline
# 通过代码运行基于Scrapy框架的网络爬虫
cmdline.execute('scrapy crawl ItemLoaderSpider -o item1.json'.split())
[
{"title": ["\u8de8\u5e73\u53f0\u5f00\u53d1\u7cfb\u7edfOriUnity\u53d1\u5e03"],
"href": ["https://geekori.com/blogDetails.php?blog_id=123"],
"abstract": ["\r\n \u8de8\u5e73\u53f0\u5f00\u53d1\u7cfb\u7edfOriUnity\u53d1\u5e03"]}
]
17.4 使用ItemLoader抓取多条数据
import scrapy
from scrapy.loader import *
from scrapy.loader.processors import *
from bs4 import *
from shitscrapy.items import ShitscrapyItem
class ItemLoaderSpider1(scrapy.Spider):
name = 'ItemLoaderSpider1'
start_urls = ['https://geekori.com/blogsCenter.php?uid=geekori']
def parse(self, response, **kwargs):
# 要返回的Items对象数组
items = []
# 获取博客页面的博客列表数据
sectionList = response.xpath('//*[@id="all"]/div[1]/section').extract()
# 通过循环迭代处理每一条博客列表数据
for section in sectionList:
bs = BeautifulSoup(section,'lxml')
articleDict = {}
a = bs.find('a')
# 获取博客标题
articleDict['title'] = a.text
# 获取博客URL
articleDict['href'] = 'https://geekori.com' + a.get('href')
# 获取博客摘要
p = bs.select('section > div.summary > p')
articleDict['abstract'] = p[0].text
# 创建ItemLoader对象
itemloader = ItemLoader(item = ShitscrapyItem(),response=response)
# 将标题、URL、摘要添加到ItemLoader对象中
itemloader.add_value('title',articleDict['title'])
itemloader.add_value('href',articleDict['href'])
itemloader.add_value('abstract',articleDict['abstract'])
# 获取封装当前博文数据的Item对象,并将其添加到items数组中
items.append(itemloader.load_item())
# 返回items数组
return items
from scrapy import cmdline
# 通过代码运行基于Scrapy框架的网络爬虫
cmdline.execute('scrapy crawl ItemLoaderSpider1 -o items.json'.split())
运行结果:保存的items.json文件内容
[
{"title": ["\u8de8\u5e73\u53f0\u5f00\u53d1\u7cfb\u7edfOriUnity\u53d1\u5e03"], "href": ["https://geekori.comblogDetails.php?blog_id=123"], "abstract": ["\r\n \u8de8\u5e73\u53f0\u5f00\u53d1\u7cfb\u7edfOriUnity\u53d1\u5e03"]},
{"title": ["Python\u4ece\u83dc\u9e1f\u5230\u9ad8\u624b\uff081\uff09\uff1a\u521d\u8bc6Python"], "href": ["https://geekori.comblogDetails.php?blog_id=118"], "abstract": ["\r\n Python\u662f\u4e00\u79cd\u9762\u5411\u5bf9\u8c61\u7684\u89e3\u91ca\u578b\u8ba1\u7b97\u673a\u7a0b\u5e8f\u8bbe\u8ba1\u8bed\u8a00\uff0c\u7531\u8377\u5170\u4eba\u5409\u591a\u00b7\u8303\u7f57\u82cf\u59c6\uff08Guido van Rossum\uff09\u4e8e1989\u5e74\u53d1\u660e\uff0c\u7b2c\u4e00\u4e2a\u516c\u5f00\u53d1\u884c\u7248\u53d1\u884c\u4e8e1991\u5e74\u3002\u76ee\u524dPython\u7684\u6700\u65b0\u53d1\u884c\u7248\u662fPython3.6\u3002\r\n\r\n"]},
{"title": ["Python\u4ece\u83dc\u9e1f\u5230\u9ad8\u624b\uff081\uff09\uff1a\u6570\u5b57\u7684\u5965\u79d8"], "href": ["https://geekori.comblogDetails.php?blog_id=98"], "abstract": ["\r\n \u6570\u5b57\u662fPython\u7a0b\u5e8f\u4e2d\u6700\u5e38\u89c1\u7684\u5143\u7d20\u3002\u5728Python\u63a7\u5236\u53f0\u4e2d\u53ef\u4ee5\u76f4\u63a5\u8f93\u5165\u7528\u4e8e\u8ba1\u7b97\u7684\u8868\u8fbe\u5f0f\uff08\u59821+2 * 3\uff09\uff0c\u6309\u56de\u8f66\u952e\u5c31\u4f1a\u8f93\u51fa\u8868\u8fbe\u5f0f\u7684\u8ba1\u7b97\u7ed3\u679c\uff0c\u56e0\u6b64\uff0cPython\u63a7\u5236\u53f0\u53ef\u4ee5\u4f5c\u4e3a\u4e00\u4e2a\u80fd\u8ba1\u7b97\u8868\u8fbe\u5f0f\u7684\u8ba1\u7b97\u5668\u4f7f\u7528\u3002\r\n\u5728Python\u8bed\u8a00\u4e2d\uff0c\u6570\u5b57\u5206\u4e3a\u6574\u6570\u548c\u6d6e\u70b9\u6570\u3002\u652f\u6301\u57fa\u672c\u7684\u56db\u5219\u8fd0\u7b97\u548c\u4e00\u4e9b\u5176\u4ed6\u7684\u8fd0\u7b97\u64cd\u4f5c\uff0c\u5e76\u4e14\u53ef..."]},
{"title": ["\u7528Android\u6a21\u62df\u5668\u4e5f\u53ef\u4ee5\u5f00\u53d1\u548c\u6d4b\u8bd5NFC\u5e94\u7528"], "href": ["https://geekori.comblogDetails.php?blog_id=94"], "abstract": ["\r\n \u4eceAndroid2.3\u5f00\u59cb\u652f\u6301NFC\u3002\u4e0d\u8fc7NFC\u5e94\u7528\u53ea\u80fd\u5728Android\u624b\u673a\uff08\u6216\u5e73\u677f\u7535\u8111\uff09\u4e0a\u6d4b\u8bd5\u548c\u5f00\u53d1\uff0c\u800c\u4e14Android\u624b\u673a\u8fd8\u5fc5\u987b\u6709NFC\u82af\u7247\u3002\u800c\u4e14\u5982\u679c\u6d4b\u8bd5NFC\u4f20\u8f93\u6587\u4ef6\u65f6\u81f3\u5c11\u9700\u8981\u4e24\u90e8\u652f\u6301NFC\u7684\u624b\u673a\u3002\u5f53\u7136\uff0c\u5982\u679c\u6d4b\u8bd5\u8bfb\u5199NFC\u6807\u7b7e\uff0c\u8fd8\u9700\u8981\u4e00\u4e9bNFC\u6807\u7b7e\u6216\u5e16\u5b50\u3002\u800c\u4e14NFC\u5728\u6a21\u62df\u5668\u4e0a\u65f6\u4e0d\u80fd\u8fd0\u884c\u7684\u3002\u6240..."]},
{"title": ["\u642d\u5efa\u53cc\u7f51\u5361CentOS 7 Linux\u5b9e\u9a8c\u73af\u5883"], "href": ["https://geekori.comblogDetails.php?blog_id=83"], "abstract": ["\r\n \u672c\u6587\u4ecb\u7ecd\u4e86\u5982\u4f55\u901a\u8fc7VirtualBox\u865a\u62df\u673a\u5b89\u88c5\u4e0a\u7f51\u5361CentOS7 Linux\u5b9e\u9a8c\u73af\u5883\u3002VirtualBox\u548cCentOS7 Linux\u5982\u4f55\u4e0b\u8f7d\uff0c\u8fd9\u91cc\u5c31\u4e0d\u8bf4\u4e86\uff0c\u81ea\u5df1baidu\u6216google\u3002\u4f46\u8981\u8bf4\u7684\u662f\uff0c\u672c\u6587\u8bb2\u7684CentOS7 Linux\u5b89\u88c5\u73af\u5883\u53ea\u662f\u6700\u57fa\u7840\u7684\u5b9e\u9a8c\u73af\u5883\uff0c\u53ea\u5305\u542bLinux\u7684\u6700\u57fa\u7840\u7ec4\u4ef6\uff0c\u5e76..."]},
{"title": ["\u300aKotlin\u7a0b\u5e8f\u5f00\u53d1\u5165\u95e8\u7cbe\u8981 \u300b\u7b2c2\u7ae0 Kotlin\u57fa\u7840\u77e5\u8bc6"], "href": ["https://geekori.comblogDetails.php?blog_id=81"], "abstract": ["\r\n \u5728\u5f00\u59cb\u6df1\u5165\u8bb2\u89e3Kotlin\u8bed\u8a00\u4e4b\u524d\uff0c\u8ba9\u6211\u4eec\u5148\u6765\u719f\u6089\u4e00\u4e0bKotlin\u7684\u57fa\u672c\u8bed\u6cd5\u3002Kotlin\u7684\u8bed\u6cd5\u5f88\u590d\u6742\uff0c\u6211\u4eec\u4e00\u5f00\u59cb\u4e5f\u4e0d\u9700\u8981\u4e86\u89e3\u592a\u591a\uff0c\u53ea\u9700\u8981\u6ee1\u8db3\u672c\u7ae0\u7684\u5b66\u4e60\u9700\u8981\u5373\u53ef\u3002\u5bf9\u4e8e\u4e00\u79cd\u8bed\u8a00\u6765\u8bf4\uff0c\u53d8\u91cf\u548c\u51fd\u6570\uff08\u65b9\u6cd5\uff09\u662f\u6700\u91cd\u8981\u7684\u4e24\u7c7b\u8bed\u6cd5\u3002\u7531\u4e8eKotlin\u8bed\u6cd5\u7cd6\u7684\u5b58\u5728\uff0c\u8ba9\u672c\u4e0d\u652f\u6301\u51fd\u6570\u8bed\u6cd5\u7684JVM\u652f\u6301\u5c06\u51fd\u6570\u653e\u5230\u4ee3\u7801\u7684\u6700\u9876\u5c42..."]},
{"title": ["\u300aKotlin\u7a0b\u5e8f\u5f00\u53d1\u5165\u95e8\u7cbe\u8981 \u300b\u7b2c1\u7ae0 Kotlin\u5f00\u53d1\u73af\u5883\u642d\u5efa "], "href": ["https://geekori.comblogDetails.php?blog_id=80"], "abstract": ["\r\n \u5c3d\u7ba1Kotlin\u4e0d\u662f\u521a\u521a\u9762\u4e16\u7684\u7f16\u7a0b\u8bed\u8a00\uff0c\u4f46\u4ee5\u524d\u4e00\u76f4\u672a\u53d7\u5230\u8db3\u591f\u7684\u91cd\u89c6\uff0c\u76f4\u5230Google\u516c\u53f8\u57282017\u5e74\u7684I/O\u5927\u4f1a\u4e0a\u5ba3\u5e03Kotlin\u6210\u4e3a\u5f00\u53d1Android App\u7684\u4e00\u7ea7\u8bed\u8a00\u540e\uff0cKotlin\u624d\u8fc5\u901f\u201c\u8d70\u7ea2\u201d\u3002\u90a3\u4e48Kotlin\u5230\u5e95\u6709\u4ec0\u4e48\u4f18\u4e8eJava\u7684\u5730\u65b9\u5462\uff1f\u4ee5\u81f3\u4e8e\u8ba9\u4e92\u8054\u7f51\u5de8\u5934Goog..."]},
{"title": ["\u300aKotlin\u7a0b\u5e8f\u5f00\u53d1\u5165\u95e8\u7cbe\u8981 \u300b\u5982\u4f55\u514d\u8d39\u83b7\u53d6\u89c6\u9891\u8bfe\u7a0b"], "href": ["https://geekori.comblogDetails.php?blog_id=79"], "abstract": ["\r\n \u968f\u672c\u4e66\u8d60\u9001\u7ed9\u8bfb\u8005\u6709\u5927\u91cf\u76f8\u5173\u9886\u57df\u7684\u514d\u8d39\u89c6\u9891\u8bfe\u7a0b\u3002\u8fd9\u4e9b\u89c6\u9891\u8bfe\u7a0b\u662f\u79bb\u7ebf\u89c2\u770b\u7684\uff0c\u4f7f\u7528\u4e13\u95e8\u7684\u64ad\u653e\u5668\uff0c\u53ef\u5728Mac OS X\u3001Windows\u3001Android\u548ciOS\u5e73\u53f0\u4e0a\u64ad\u653e\u3002\u8bfb\u8005\u5728\u8d2d\u4e70\u672c\u4e66\u540e\uff0c\u9700\u8981\u8ba4\u8bc1\u8bfb\u8005\u624d\u53ef\u4ee5\u89c2\u770b\u3002\u8ba4\u8bc1\u8bfb\u8005\u7684\u6b65\u9aa4\u5982\u4e0b\u3002\r\n\r\n\uff081\uff09\u626b\u63cf\u672c\u4e66\u5c01\u9762\u53f3\u4e0a\u89d2\u7684\u4e8c\u7ef4\u7801\uff0c\u5173\u6ce8\u6b27\u745e\u5b66\u9662\u516c\u4f17\u53f7\u3002\r\n\r\n\uff082\uff09..."]},
{"title": ["Android\u7f51\u7edc\u5b89\u5168\u6027\u914d\u7f6e"], "href": ["https://geekori.comblogDetails.php?blog_id=69"], "abstract": ["\r\n \u7f51\u7edc\u5b89\u5168\u6027\u914d\u7f6e\u7279\u6027\u8ba9\u5e94\u7528\u53ef\u4ee5\u5728\u4e00\u4e2a\u5b89\u5168\u7684\u58f0\u660e\u6027\u914d\u7f6e\u6587\u4ef6\u4e2d\u81ea\u5b9a\u4e49\u5176\u7f51\u7edc\u5b89\u5168\u8bbe\u7f6e\uff0c\u800c\u65e0\u9700\u4fee\u6539\u5e94\u7528\u4ee3\u7801\u3002\u53ef\u4ee5\u9488\u5bf9\u7279\u5b9a\u57df\u548c\u7279\u5b9a\u5e94\u7528\u914d\u7f6e\u8fd9\u4e9b\u8bbe\u7f6e\u3002\u6b64\u7279\u6027\u7684\u4e3b\u8981\u529f\u80fd\u5982\u4e0b\u6240\u793a\uff1a"]},
{"title": ["Electron\u73af\u5883\u642d\u5efa\u4e0e\u53d1\u5e03"], "href": ["https://geekori.comblogDetails.php?blog_id=63"], "abstract": ["\r\n \u5728Electron\u7bc7\u7684\u7cfb\u5217\u6587\u7ae0\u4e2d\uff0c\u5c06\u4f1a\u4ecb\u7ecd\u5173\u4e8e\u7528Electron\u5f00\u53d1\u684c\u9762\u5e94\u7528\u7684\u6838\u5fc3\u6280\u672f\u3002\u672c\u6587\u4e3b\u8981\u4ecb\u7ecd\u4e86Electron\u7684\u5f00\u53d1\u73af\u5883\u642d\u5efa\u4ee5\u53ca\u5982\u4f55\u5206\u53d1Electron\u5e94\u7528\u3002\u53ef\u80fd\u6709\u5f88\u591a\u540c\u5b66\u8fd8\u4e0d\u4e86\u89e3Electron\u5230\u5e95\u662f\u4ec0\u4e48\uff1f\u8fd9\u4e2a\u4e1c\u4e1c\u5c31\u662f\u7528JavaScript+HTML5+CSS3\u5f00\u53d1\u684c\u9762\u5e94\u7528\uff08Window..."]},
{"title": ["Linux\u4efb\u52a1\u8c03\u5ea6\u670d\u52a1\uff1acrond"], "href": ["https://geekori.comblogDetails.php?blog_id=58"], "abstract": ["\r\n \u5728Linux\u4e0b\uff0c\u5b9a\u65f6\u5b8c\u6210\u67d0\u4e9b\u64cd\u4f5c\u7684\u529f\u80fd\u5f80\u5f80\u662f\u5fc5\u987b\u7684\u3002\u5b9e\u9645\u4e0a\uff0c\u5728Linux\u7cfb\u7edf\u672c\u8eab\u4e5f\u6709\u5f88\u591a\u5b9a\u65f6\u64cd\u4f5c\uff0c\u5982\u7f13\u5b58\u6570\u636e\u5230\u786c\u76d8\u3001\u65e5\u5fd7\u6e05\u7406\u7b49\u3002\u8fd9\u7c7b\u7cfb\u7edf\u672c\u8eab\u8981\u5b9a\u65f6\u6267\u884c\u7684\u64cd\u4f5c\u79f0\u4e3a\u7cfb\u7edf\u4efb\u52a1\u8c03\u5ea6\u3002\u7cfb\u7edf\u8c03\u5ea6\u914d\u7f6e\u6587\u4ef6\u5728\u4e3a/etc/crontab\uff0c\u4f7f\u7528vi /etc/crontab\u547d\u4ee4\u53ef\u4ee5\u7f16\u8f91\u8be5\u6587\u4ef6\uff0c\u4e0d\u8fc7\u7cfb\u7edf\u8c03\u5ea6\u5e76\u4e0d\u5728\u672c\u6587..."]},
{"title": ["\u8c37\u6b4c\u9ed1\u677f\u62a5\uff1aAlphaGo\u7684\u4e0b\u4e00\u6b65"], "href": ["https://geekori.comblogDetails.php?blog_id=57"], "abstract": ["\r\n \u3000\u4e2d\u56fd\u56f4\u68cb\u5927\u5e08\uff0c\u4e16\u754c\u6392\u540d\u7b2c\u4e00\u7684\u67ef\u6d01\u4e5d\u6bb5\u4e00\u6539\u4ee5\u5f80\u98ce\u683c\uff0c\u4ee5\u4e09\u00b73 \u4f5c\u4e3a\u5f00\u5c40\u3002\u8fd9\u79cd\u5f00\u5c40\u65b9\u5f0f\u5341\u5206\u7f55\u89c1\uff0c\u5176\u76ee\u7684\u662f\u8981\u5728\u5f00\u5c40\u9636\u6bb5\u5feb\u901f\u62a2\u5360\u89d2\u90e8\u5b9e\u5730\u3002\u8fd9\u79cd\u4e0b\u6cd5\u4ee5\u5f80\u5f88\u5c11\u88ab\u56f4\u68cb\u9009\u624b\u6240\u91c7\u7528\uff0c\u4f46\u5374\u662f AlphaGo \u6700\u559c\u7231\u7684\u5f00\u5c40\u3002\u67ef\u6d01\u4e5f\u5c06\u5176\u4f7f\u7528\u5728\u4e86\u81ea\u5df1\u7684\u5bf9\u5c40\u5f53\u4e2d\u3002 "]},
{"title": ["\u4f7f\u7528Android NDK\u548cJava\u6d4b\u8bd5Linux\u9a71\u52a8"], "href": ["https://geekori.comblogDetails.php?blog_id=38"], "abstract": ["\r\n \u5728 Android\u7cfb\u7edf\u4e2dLinux\u9a71\u52a8\u4e3b\u8981\u7684\u4f7f\u7528\u8005\u662fAPK\u7a0b\u5e8f\u3002\u56e0\u6b64\uff0cLinux\u9a71\u52a8\u505a\u5b8c\u540e\u5fc5\u987b\u8981\u7528APK\u7a0b\u5e8f\u8fdb\u884c\u6d4b\u8bd5\u624d\u80fd\u8bf4\u660eLinux\u9a71\u52a8\u53ef\u4ee5\u6b63\u5e38\u4f7f \u7528\u3002\u7531\u4e8e\u4e0a\u4e00\u8282\u5728Android\u865a\u62df\u673a\u4e0a\u4f7f\u7528C\u8bed\u8a00\u7f16\u5199\u7684\u53ef\u6267\u884c\u7a0b\u5e8f\u6d4b\u8bd5\u4e86Linux\u9a71\u52a8\uff0c\u56e0\u6b64\u5f88\u5bb9\u6613\u60f3\u5230\u53ef\u4ee5\u5229\u7528Android NDK\u6765\u6d4b\u8bd5Linux\u9a71..."]},
{"title": ["Android\u7684init\u8fc7\u7a0b\uff08\u4e8c\uff09\uff1a\u521d\u59cb\u5316\u8bed\u8a00\uff08init.rc\uff09\u89e3\u6790"], "href": ["https://geekori.comblogDetails.php?blog_id=37"], "abstract": ["\r\n \u5728\u4e0a\u4e00\u7bc7\u6587\u7ae0\u4e2d\u4ecb\u7ecd\u4e86init\u7684\u521d\u59cb\u5316\u7b2c\u4e00\u9636\u6bb5\uff0c\u4e5f\u5c31\u662f\u5904\u7406\u5404\u79cd\u5c5e\u6027\u3002\u5728\u672c\u6587\u5c06\u4f1a\u8be6\u7ec6\u5206\u6790init\u6700\u91cd\u8981\u7684\u4e00\u73af\uff1a\u89e3\u6790init.rc\u6587\u4ef6\u3002init.rc\u6587\u4ef6\u5e76\u4e0d\u662f\u666e\u901a\u7684\u914d\u7f6e\u6587\u4ef6\uff0c\u800c\u662f\u7531\u4e00\u79cd\u88ab\u79f0\u4e3a\u201cAndroid\u521d\u59cb\u5316\u8bed\u8a00\u201d\uff08Android Init Language\uff0c\u8fd9\u91cc\u7b80\u79f0\u4e3aAI..."]},
{"title": ["Android\u7684init\u8fc7\u7a0b\u8be6\u89e3\uff08\u4e00\uff09"], "href": ["https://geekori.comblogDetails.php?blog_id=36"], "abstract": ["\r\n \u672c\u6587\u53ca\u540e\u7eed\u51e0\u7bc7\u6587\u7ae0\u5c06\u5bf9Android\u7684\u521d\u59cb\u5316\uff08init\uff09\u8fc7\u7a0b\u8fdb\u884c\u8be6\u7ec6\u5730\u3001\u5265\u4e1d\u62bd\u8327\u5f0f\u5730\u5206\u6790\uff0c\u5e76\u4e14\u5728\u5176\u4e2d\u7a7f\u63d2\u4e86\u5927\u91cf\u7684\u77e5\u8bc6\uff0c\u5e0c\u671b\u5bf9\u8bfb\u8005\u4e86\u89e3Android\u7684\u542f\u52a8\u8fc7\u7a0b\u53c8\u6240\u5e2e\u52a9\u3002\u672c\u7ae0\u4e3b\u8981\u4ecb\u7ecd\u4e86\u4e0e\u786c\u4ef6\u76f8\u5173\u521d\u59cb\u5316\u6587\u4ef6\u540d\u7684\u786e\u5b9a\u4ee5\u53ca\u5c5e\u6027\u670d\u52a1\u7684\u539f\u7406\u548c\u5b9e\u73b0\u3002"]}
]
17.5 抓取多个url地址的数据
通过一个文本文件urls.txt提供多个URL进行批量抓取
urls.txt文件内容
https://geekori.com/blogsCenter.php?uid=geekori
https://geekori.com/blogsCenter.php?uid=geekori&page=2
爬虫MultiUrlSpider.PY
主要是通过scrapy中start_urls(不可改名字)来进行多个url的抓取
import scrapy
class MultiUrlSpider(scrapy.Spider):
name = 'MultiUrlSpider'
start_urls = [
url.strip() for url in open('../shitscrapy/urls.txt').readlines()
]
# 从urls.txt读取所有的URL,并保存到start_url中
def parse(self, response, **kwargs):
# 使用Xpath分析页面
sectionList = response.xpath('//*[@id="all"]/div[1]/section').extract()
# 输出当前页面的博文数
print('共有{}条博文'.format(len(sectionList)))
执行文件exec:
from scrapy import cmdline
cmdline.execute('scrapy crawl MultiUrlSpider'.split())
17.6 下载器中间件介绍
Scrapy允许使用中间件干预数据的抓取过程,以及完成其他数据处理工作。
(1)指定Web资源的URL,并向服务端发送请求。需要依赖爬虫类的start_urls变量或start_requests方法
(2)当服务端响应Scrapy爬虫的请求后,就会返回响应数据,这是系统会将响应数据再交由Scrapy爬虫处理,也就是调用爬虫类的请求回调方法parse
1、核心方法,下载器中间件可以对这两步进行拦截。当爬虫想服务端发送请求之前,会通过下载器中间件类的process_request方法进行拦截,
当爬虫处理服务端响应数据之前,会通过下载器中间件类的process_response方法进行拦截
process_request(request,spider)
当爬虫想服务端发送请求之前该方法就会被调用,通常在该方法中设置请求头信息,或修改需要提交给服务端的数据。
返回值必须为None、Response对象或Request对象之一
方法参数有两个:
1、request:包含请求信息的Request对象
2、spider:Request对应的Spider对象
返回值类型效果:
1、None:Scrapy会继续处理该Request,然后接着执行其他下载中间器的process_request方法,知道下载器想服务器发送请求后,得到响应结果才结束
2、Response对象:优先级更低的下载器中间件的process_request方法不会再继续调用,转而开始调用每个下载器中间件的process_response方法
3、Request对象:优先级更低的下载器中间件的process_request方法不会再继续调用,并将这Request对象放到调度对立中,等待调度。
4、IgnoreRequest异常:如果IgnoreRequest异常抛出,则所有的Downloader Middleware的process_exception方法会一次执行。
如果没有方法处理异常,那么Request的errorback方法就会回调
process_response(request,response,spider)
下载器执行Request下载数据之后,会得到对应的Response。Scrapy引擎便会将Response发送给Spider进行解析。在发送之前可以用process_response
方法对Response进行处理。方法的返回值必须是Request对象或Response对象,或抛出IgnoreRequest异常
方法参数有三个:
1、request:与Response对应的Request对象
2、response:被处理的Response对象
3、spider:与Response对应的Spider对象
返回值同process_request
process_exception(request,exception,spider)
当下载器或process_request抛出异常时,该方法就会被调用
方法参数有三个:
1、request:…
2、exception:抛出的异常对象
3、spider:…
返回值同process_request
17.7 爬虫中间件介绍
爬虫中间件(Spider Middleware)是Spider处理机制的构造框架,首先来看一下爬虫中间件的架构
当爬虫向服务端发送请求之前,会经过爬虫中间件处理。下载(DownLoader)生成Response之后,Response会被发送给Spider,在发送给Spider之前
Response会首先经过爬虫中间件处理,当Spider处理生成Item之后,会也会经过爬虫中间件处理。所以爬虫中间件会在3个位置起作用。
(1)向服务端发送Request之前,即在Request发送给调度器(Scheduler)之前对Request进行处理
(2)在Downloader生成Response,并发送给Spider之前,也就是在Response发送给Spider之前对Response进行处理
(3)在Spider生成Item,并发送给Item管道(Item Pipeline)之前,也就是在处理Response的对象返回Item对象之后对Item进行处理
1、内建爬虫中间件
爬虫提供内置中间件,和下载器中间件类似,settings.py文件中,如下:
SPIDER_MIDDLEWARES = {
‘downloader.middlewares.SpiderMiddleware’: 665,
}
和下载器中间件一样有优先数,数字越小,优先级越高
2、爬虫中间件的核心方法
(1)process_spider_input(response,spider)
在Response被提交给爬虫处理之前,该方法会被调用
(2)process_spider_output(response,result,spider)
在爬虫处理Response返回结果,并返回Item后,process_spider_output方法被调用
(3)process_spider_exception(response,exception,spider)
在爬虫中间件的process_spider_input方法抛出异常时,process_spider_exception方法会被调用
(4)process_start_request(start_requests,spider)
在爬虫向服务端发送请求之前调用
事实上,下载中间件的功能足够了,爬虫中间件使用的频率并不高
使用爬虫中间件是注意两点:
1、爬虫中间件和下载器中间件的优先级数没有联系
2、如果同时使用两者中间件,这两类的中间件会被交替调用
17.8 Item管道介绍
Item管道即Item Pipeline
在爬虫产生Item之后调用Item管道。当爬虫解析完Response之后,Item就会传递到Item管道中,被定义的Item管道组件会按顺序调用,完成数据处理工作
Item管道的主要功能有如下几点:
1、数据清理,主要清理HTML数据
2、校验抓取的数据,检查抓取的字段数据
3、查重并丢弃重复的内容
4、数据存储,也就是将抓取的数据保存在数据库中
Item管道是一个普通的Python类,需要在pipelines.py文件中定义。与中间件一样,也需要实现一些方法,但必须实现process_item(item,spider)
process_item(item,spider)
必须实现的方法,Item会默认调用这个方法对Item进行处理
其余可选方法:
1、open_spider(spider)
在Spider开启时自动调用,在这个方法中可以做一些初始化操作,如打开数据库连接、初始化变量等。其中spider就是被开启的Spider对象
2、close_spider(spider)
在Spider关闭时自动调用,在这个方法中可以做一些收尾工作,如关闭数据库、删除临时文件等。spider就是被关闭的Spider对象
3、from_crawler(cls,crawler)
from_crawler是一个类方法,用@classmethod表示,是一种赖以注入的方式。
参数cls的类型是Class,最后会返回一个Class实例。通过参数crawler可以拿到Scrapy的所有核心组件,如全局配置的每一个信息,然后创建一个Pipeline实例
17.9 实操案例:抓取新闻
此处简单介绍一下两种通用爬虫类,不需要可以跳过
17.9.1 通用爬虫类CrawlSpider
CrawlSpider是Scrapy提供的一个通用爬虫类。从Spider类继承,还包两个特性。
1、rules属性:用于指定抓取规则,列表类型
2、parse_start_url方法:这是一个可重写的方法。当start_urls里对应的Request得到Response是,该方法被调用,通常在此方法中分析Response
class Rule(object):
def init(self, link_extractor=None, callback=None, cb_kwargs=None, follow=None, process_links=None,
process_request=None, errback=None,):
…
(1)link_extractor:是LinkExtractor对象。通过该对象,爬虫可以知道需要抓取页面中的哪些URL,以及在那个区域提取这些URL。提取的URL会
自动生成Request对象。
class LxmlLinkExtractor(FilteringLinkExtractor):
def init(self,allow=(),deny=(),allow_domains=(),deny_domains=(),restrict_xpaths=(),tags=(‘a’, ‘area’),
attrs=(‘href’,),canonicalize=False,unique=True,process_value=None,deny_extensions=None,restrict_css=(),
strip=True,restrict_text=None,):
…
①allow:一个正则式或者正则表达式列表,定义了符合条件的URL才会被提取
②deny:指定哪些URL不会被提取
③allow_domains:定义了符合要求的域名
④deny_domains:定义了域名黑名单
⑤restrict_xpaths:定义了提取URL的区域,爬虫只会提取该属性指定区域内符合条件的URL
⑥restrict_css:与restrict_xpaths属性的功能类似,只是需要通过CSS选择器指定提取URL的区域
(2)callback:回调函数
(3)cd_kwargs:字典类型,包含传递给回调函数的参数值
(4)follow:布尔类型,根据规则从Response提取出来的URl是否需要跟进
(5)process_links:指定处理函数,根据规则提取URL时会被调用,通常在该函数中过滤提取的URL
(6)process_request:处理函数,根据规则提取URL后自动创建
17.9.2 通用爬虫类ItemLoader
ItemLoader提供一种便捷的机制帮助创建Item。提供一系列API可以分析原始数据,并对Item的响应属性进行赋值。ItemLoader提供填充容器的机制。
ItemLoader中每个字段都包含一个输入处理器(Input Processor)和一个输出处理器(Out Processor)
输入处理器收到数据后会立即提取数据,处理结果会被收集起来,并保存到ItemLoader中,但不分配给item。
收集完所有的数据后,load_item方法被调用来用这些数据填充Item对象。
内置处理器:
1、Identity:最简单的Processor,不进行任何处理,直接返回原数据
2、TakeFirst:返回列表的第一个非空值,作为OutProcessor
3、Join:将列表中每一个元素首尾相接合成一个字符串,默认分隔符是空格
4、Compose:将多个处理器或函数组合在一起使用,类似Linux的管道
5、MapCompose:可以迭代处理一个列表的输入值
6、SelectJmes:可以通过key获得JSON对象的value
中hua网新闻案例
- 创建爬虫项目
- 编写NewsItem类
编写需要的数据信息
from scrapy import Field,Item
class NewsItem(Item):
title = Field() # 新闻标题
text = Field() # 新闻内容
datetime = Field() # 新闻发布日期
source = Field() # 新闻来源
url = Field() # 新闻在中hua网的URL
website = Field() # 网站名,本例是“中hua网”
- 编写NewsLoader类(ItemLoader)
# 文件名称:loaders.PY
from scrapy.loader import ItemLoader
from scrapy.loader.processors import TakeFirst, Join, Compose
class NewsLoader(ItemLoader):
# 默认的输出处理器,取所有未指定输出处理器的列表类型字段值的第1个非空值
default_output_processor = TakeFirst()
# 将text列表字段的每一个元素值连接起来,然后去掉首位两端的空格
text_out = Compose(Join(), lambda s: s.strip())
# 将source列表字段的每一个元素值连接起来,然后去掉首位两端的空格
source_out = Compose(Join(), lambda s: s.strip())
- 编写NewsSpider爬虫类
# 文件名称:NewsSpider.PY
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapynews.items import *
from scrapynews.spiders.loaders import *
class NewSpider(CrawlSpider):
name = 'news'
# 只抓取域名是tech.china.com的URL
allowed_domains = ['tech.china.com']
# 定义入口URL
start_urls = ['https://tech.china.com/internet/']
# 定义提取URL的规则,第1个Rule对象定义了如何提取页面中的URL,第2个URL定义了如何提取“下一页”的URL
rules = (
Rule(LinkExtractor(allow='article/\.*\.html',restrict_xpaths='//div[@id="left_side"]//div[@class="con_item"]'),
callback='parse_item'),
Rule(LinkExtractor(restrict_xpaths='//div[@id="pageStyle"]//a[contains(.,"下一页")]'))
)
# 提取每一条新闻的相关数据
def parse_item(self, response):
loader = NewsLoader(item=NewsItem(), response=response)
loader.add_xpath('title', '//h1[@id="chan_newsTitle"]/text()')
loader.add_value('url', response.url)
loader.add_xpath('text', '//div[@id="chan_newsDetail"]//text()')
loader.add_xpath('datetime', '//div[@id="chan_newsInfo"]/text()', re='(\d+-\d+-\d+\s\d+:\d+:\d+)')
loader.add_xpath('source', '//div[@id="chan_newsInfo"]/text()', re='来源:(.*)')
loader.add_value('website', '中hua网')
# 用产生器返回NewsItem对象
yield loader.load_item()
- 编写执行exec文件
# 文件名称:execute_news.PY
from scrapy import cmdline
cmdline.execute('scrapy crawl news'.split())
最后的结束语
至此,所有的爬虫内容已经结束,可以定义为中级爬虫学习的结束。但实际上,爬虫还有很多路要走,反爬虫和结合机器学习过图片文字识别的方法都属于高级爬虫的方法,目前的内容全部搞懂已经足够了。


















 555
555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









