




 本文详细介绍了如何通过Charles抓取手机App数据,包括配置安装、证书设置、手机代理及实战使用爱吾游戏宝盒数据的教程。重点演示了如何设置代理、编辑请求和利用Python爬虫获取并解析数据。
本文详细介绍了如何通过Charles抓取手机App数据,包括配置安装、证书设置、手机代理及实战使用爱吾游戏宝盒数据的教程。重点演示了如何设置代理、编辑请求和利用Python爬虫获取并解析数据。
写在前面
移动App多使用异步的方式从服务端获取数据,抓取数据之前,要先分析移动App用于获取数据的URL,然后才可以使用requests等网络库去抓取
本章的主要内容:
1、抓取App数据的原理
2、Charles和mitmproxy
3、在PC上安装整数,以及移动端安装和信任整数
4、在手机端设置代理
5、监听HTTP/HTTPS数据
6、编辑请求信息
7、mitmweb的基本使用方法
8、如何结合mitmdump与mitmweb编写实时Python爬虫
配置安装Charles
安装Charles
链接: Charles官方下载网址.
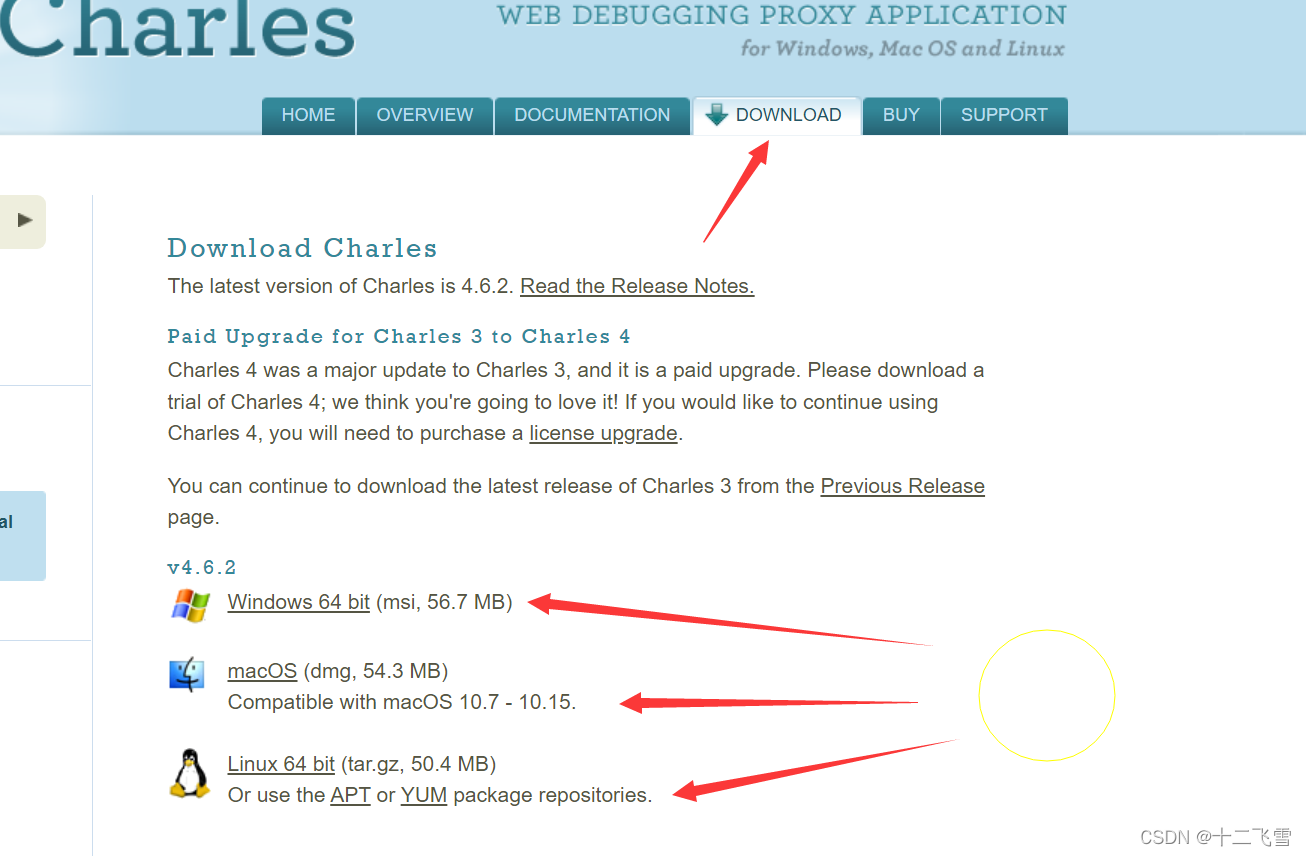
博主安装的是Windows版本
下载相关证书
电脑证书:
安装Charles后,进行如下操作
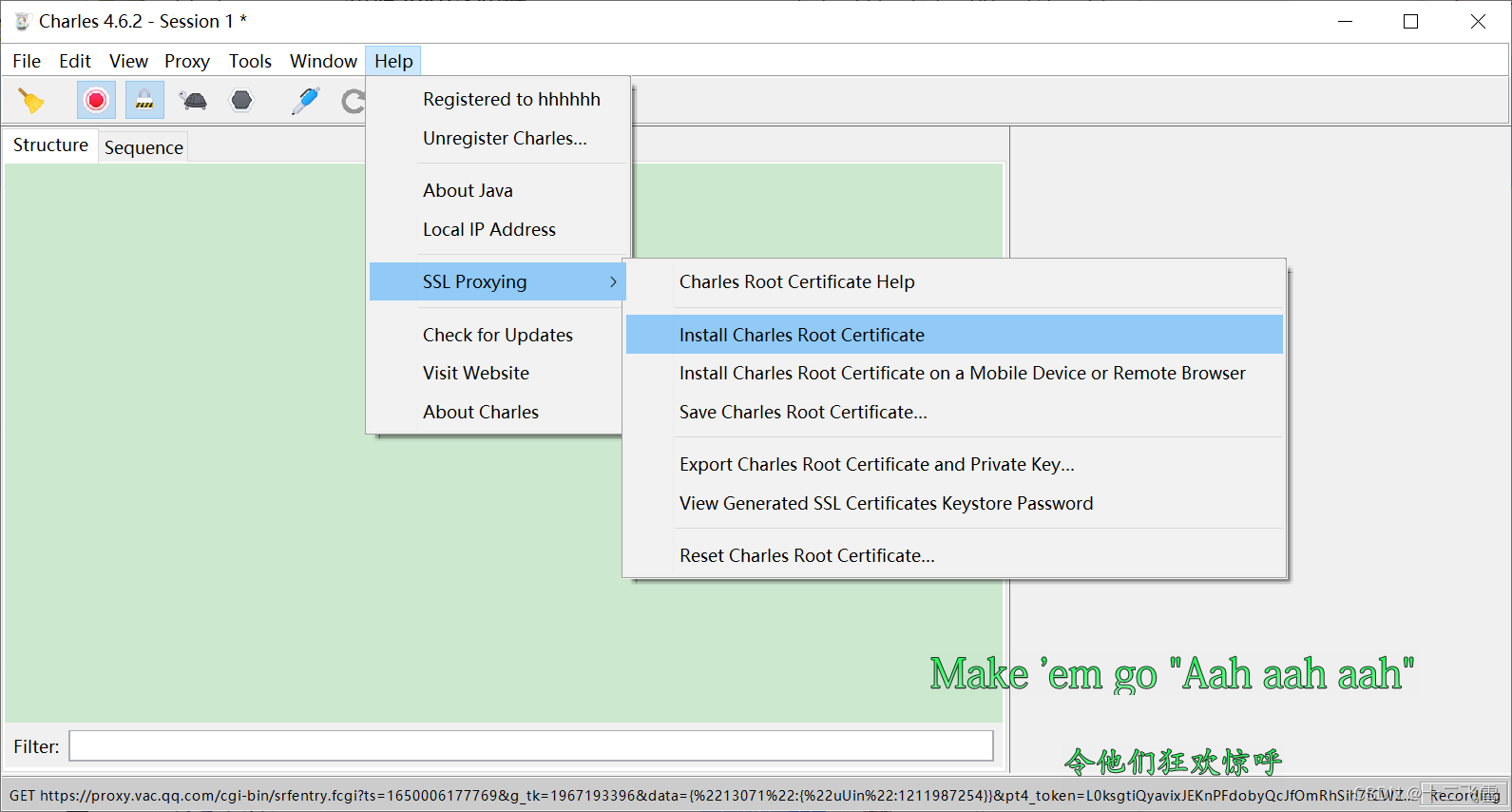
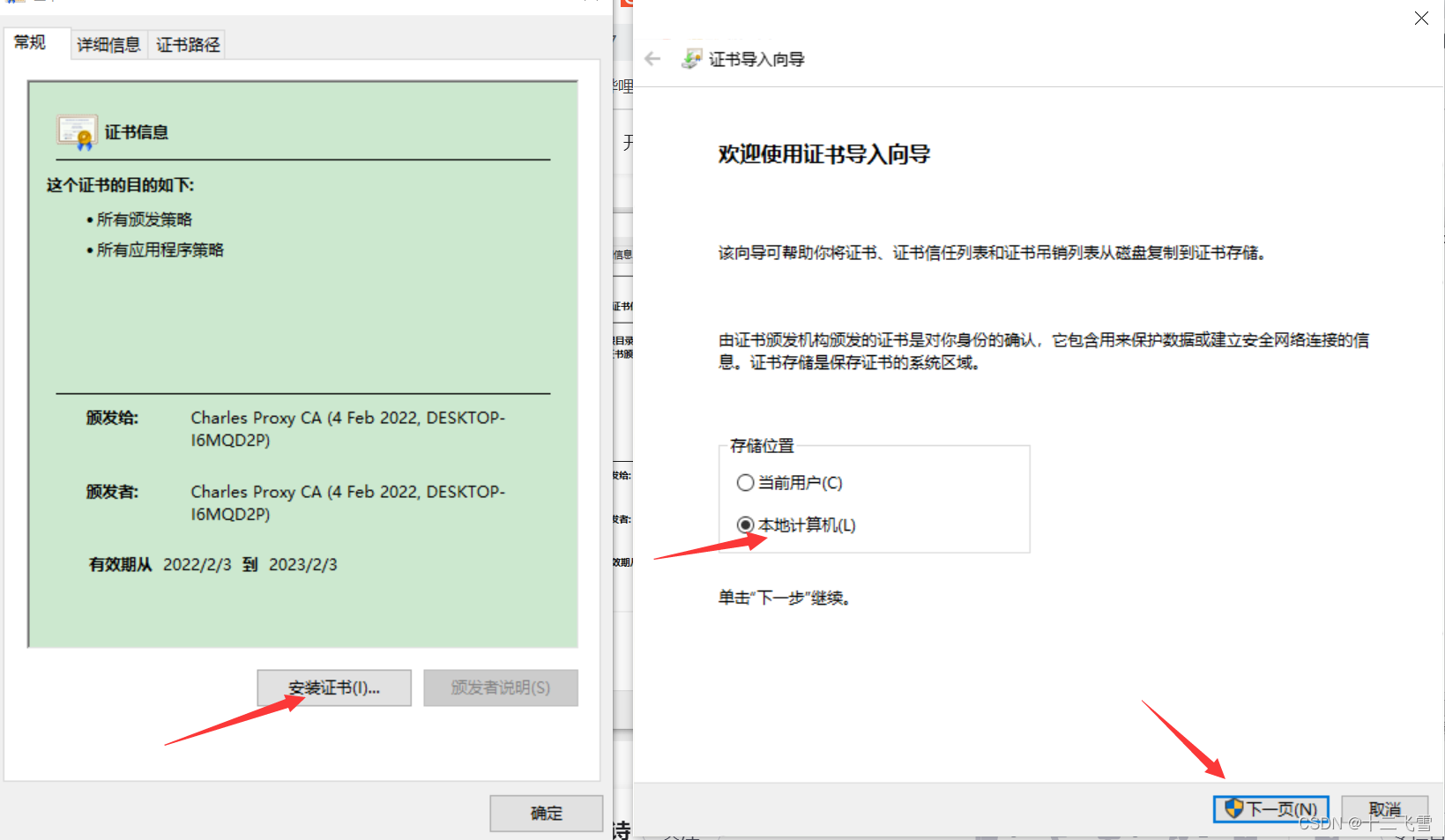
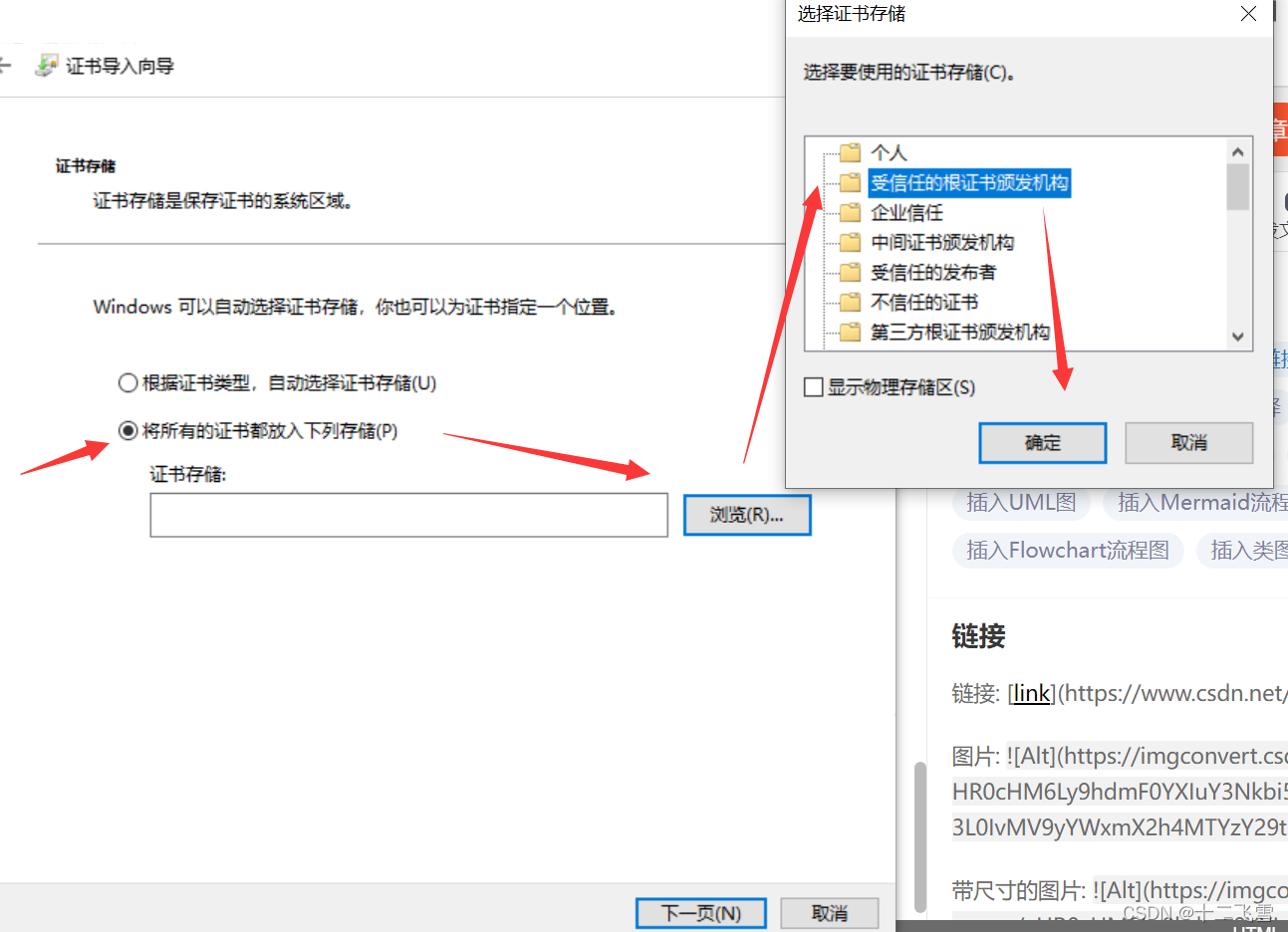
手机证书:
设置代理
- 设置SSL代理设置
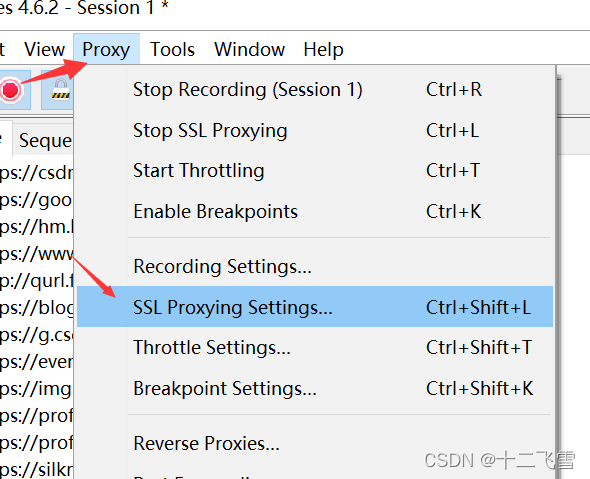
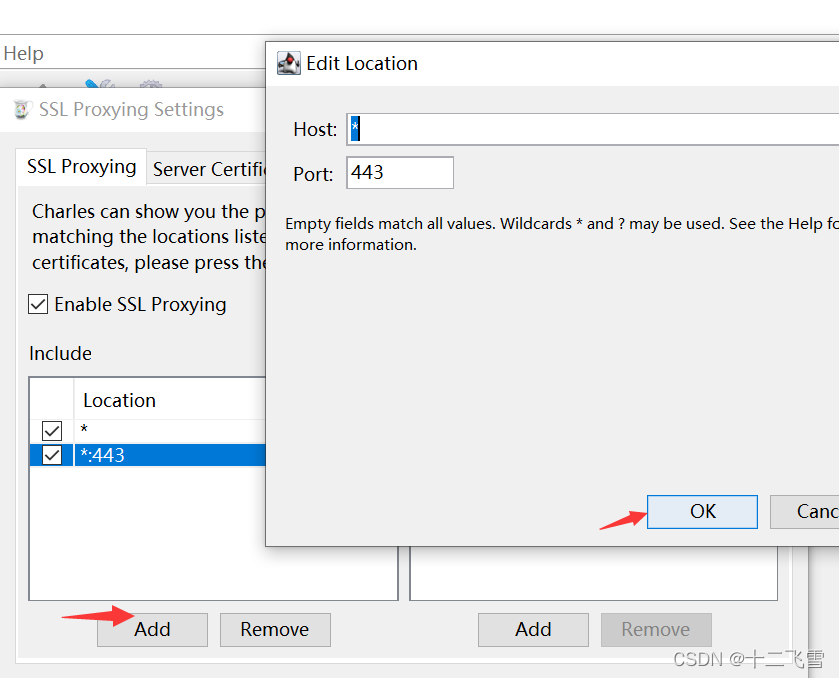
- 设置与手机的代理
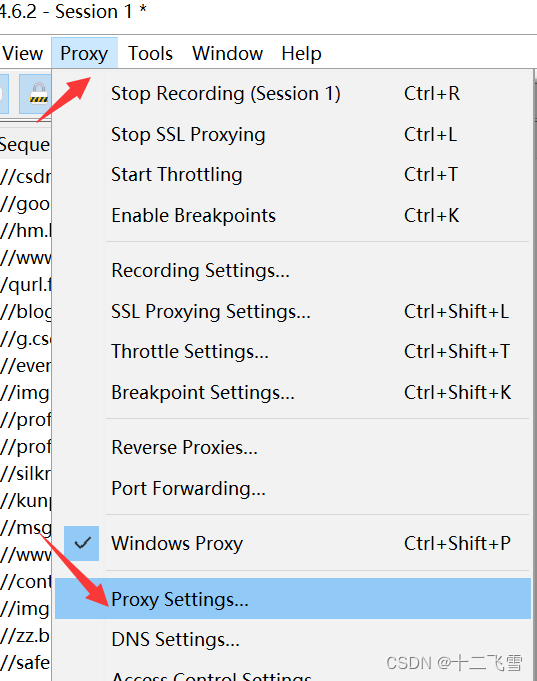
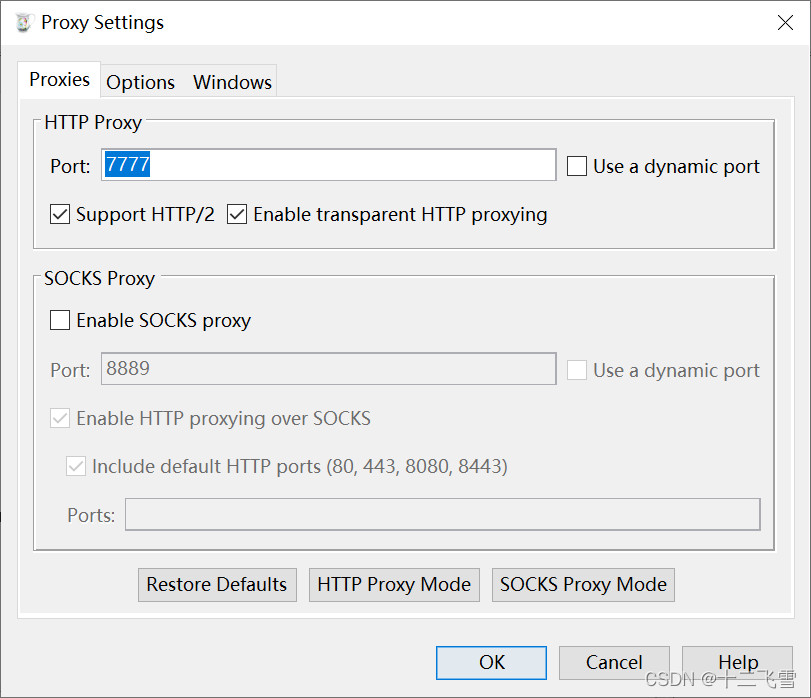
下面为OPPO手机设置代理方式:
1. 手机连上电脑的wifi
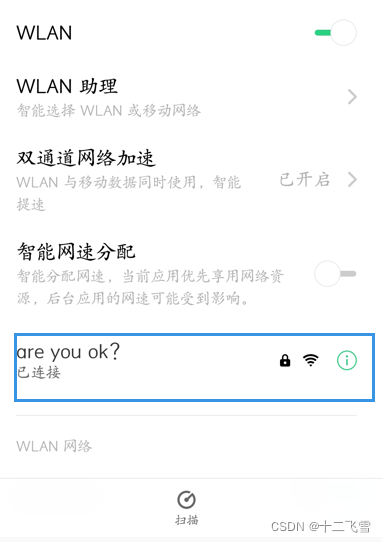
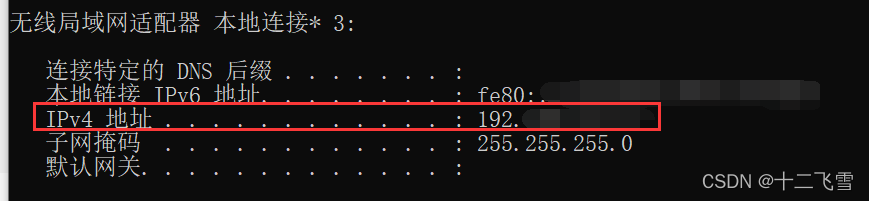
2. 使用cmd->ipconfig获取电脑的ip地址
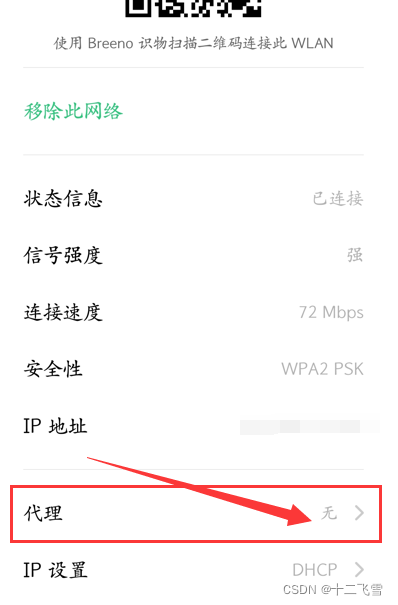
3.设置手机的代理

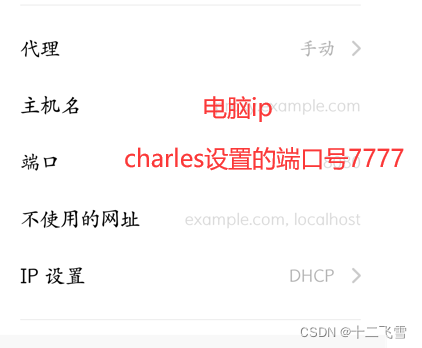
设置成功后,进入浏览器等待一下,会出现如下的选项对话框,点击Allow即可
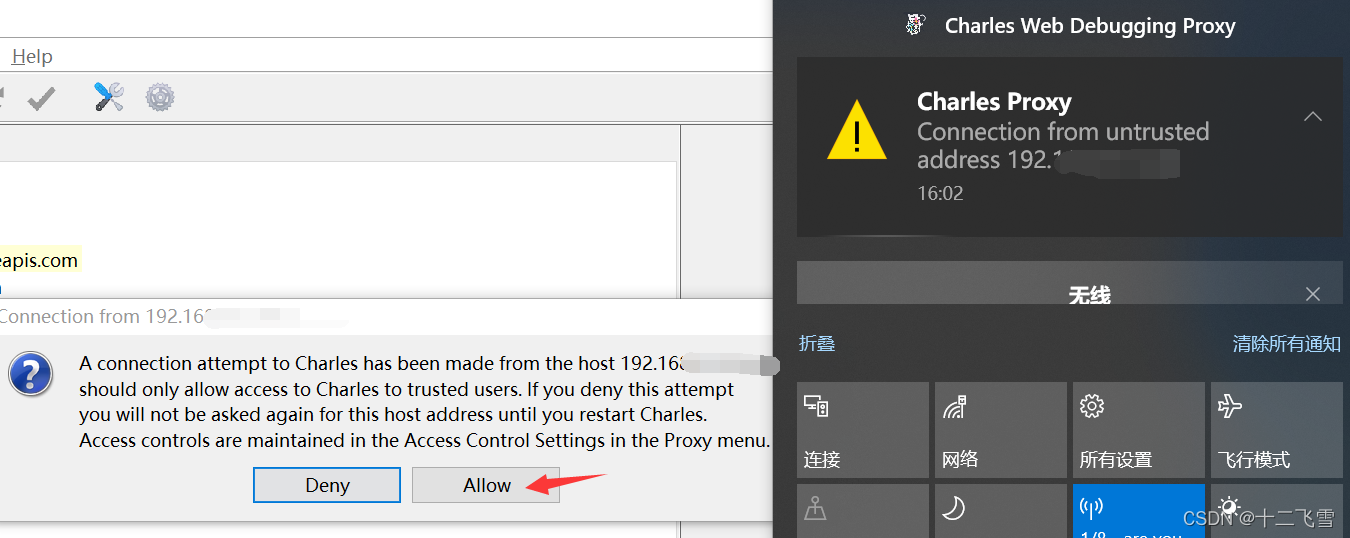
此时代理设置成功,但是主要任务还没有做,前面都是必要的手续
在浏览器输入chls.pro/ssl
即可下载Charles所需的证书
设置为信任即可
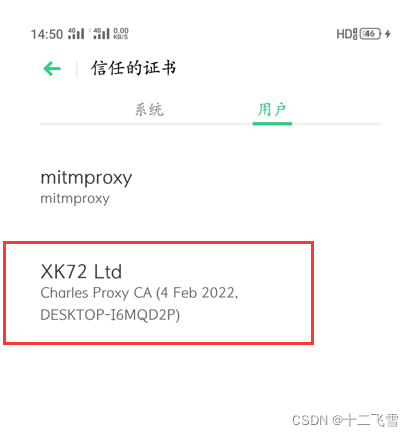
到此为止,电脑、手机证书和代理都完毕。
实操案例:抓取手机APP爱吾游戏宝盒数据
首先,清空其中的条目,因为Charles不仅再抓取手机的包,还在抓取电脑的包,电脑暂时不要访问页面或者打开应用,否则会弹出别的条目干扰。
此时我的手机打开了爱吾游戏宝盒,就弹出了好多条目,只需要找到哪一个条目中的数据是你需要的,保存url调用requests库请求url即可,接下来就是解析的工作等等。
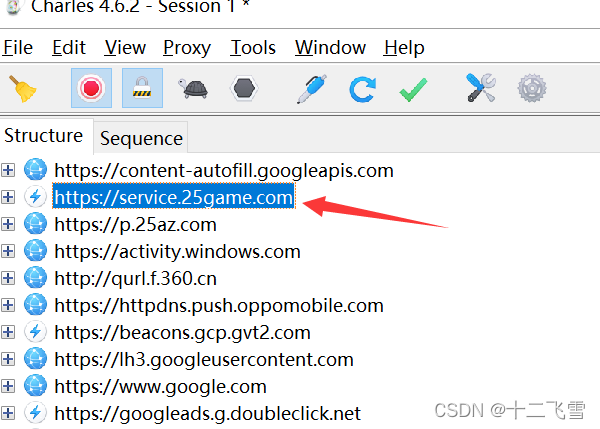
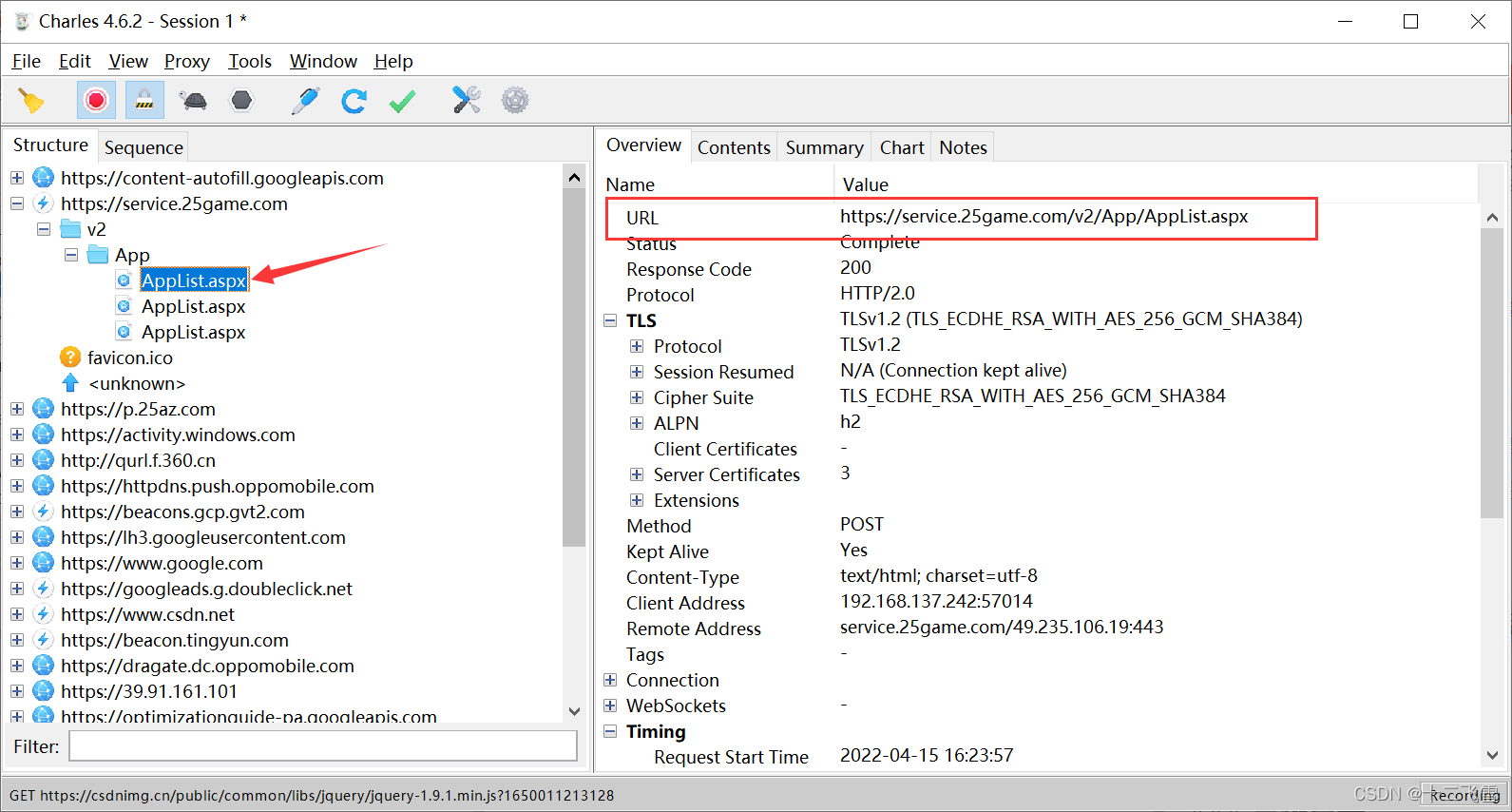
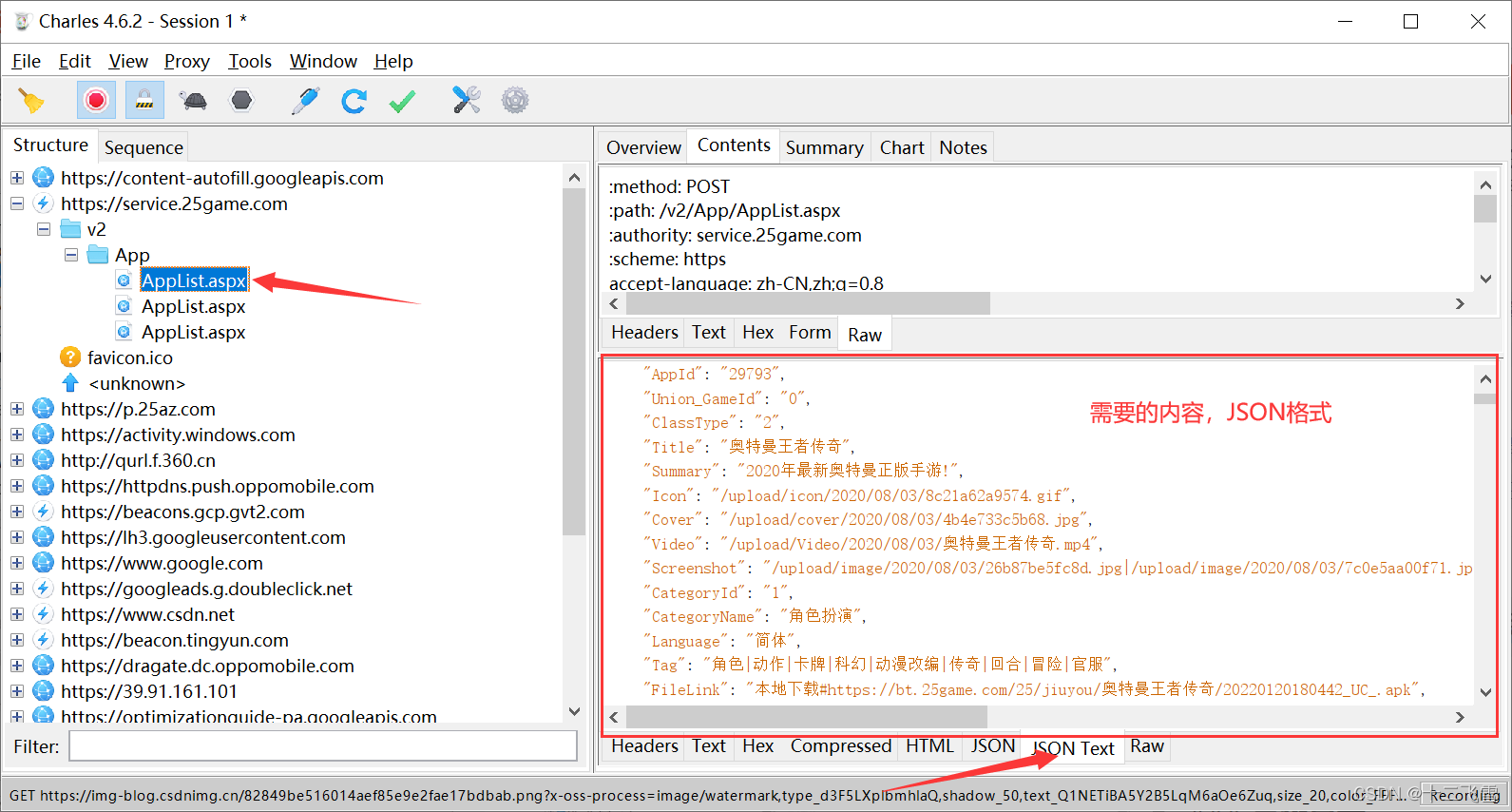
确定了内容是需要抓取的后,开始编写python爬虫
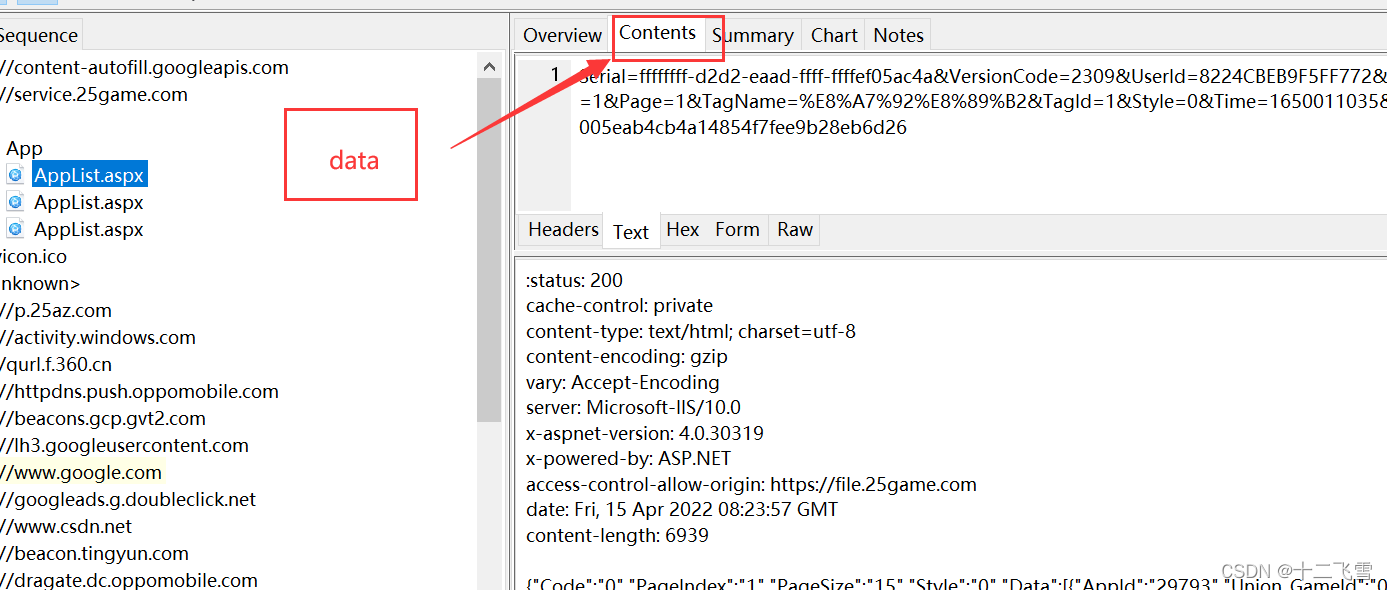
需要把上面response返回的Contents作为data加入编码中
import requests
# data从request的Text中获取
data = '''Serial=ffffffff-d2d2-eaad-ffff-ffffef05ac4a&VersionCode=2309&UserId=8224CBEB9F5FF772&isLogin=1&Page=1&TagName=
%E8%A7%92%E8%89%B2&TagId=1&Style=0&Time=1644220741&Sign=3b94ec9cd4b81ff5d76c2acb00c649e8'''
headers = {
'accept-language':'zh-CN,zh;q=0.8',
'user-agent':'okhttp-okgo/jeasonlzy',
'content-type':'application/x-www-form-urlencoded',
'Host':'service.25game.com'
}
# 抓取角色游戏信息--失败
# 无法解析:实时获取的数据
response = requests.post('https://service.25game.com/v2/App/AppList.aspx',headers=headers,data=data)
print(response.text)
# 抓取用户信息(成功)
data = '''Serial=ffffffff-d2d2-eaad-ffff-ffffef05ac4a&VersionCode=2309&UserId=8224CBEB9F5FF772&isLogin=1&Time=1644220737&Sign=127929932b6de290fe6ac0585bcfd054'''
response = requests.post('https://service.25game.com/v2/User/UserInfo.aspx',headers=headers,data=data)
print(response.text)
# 抓取移植游戏列表(成功)
data = '''Serial=ffffffff-d2d2-eaad-ffff-ffffef05ac4a&VersionCode=2309&UserId=8224CBEB9F5FF772&isLogin=1&Page=1&Time=1644221449&Sign=c960123b24a715860970f0263f0d6ec3'''
response = requests.post('https://service.25game.com/v2/DiyPage/EmuGame.aspx',headers=headers,data=data)
print(response.text)
注意:像某东JD这种应用大多还需要手机APP登录后的Cookie,同样,Charles可以获取cookie,别忘了在python爬虫中加入到请求头中。


















 1227
1227

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









