




 本文详细介绍了Requests库的功能,包括发送HTTP请求、处理响应、上传文件、设置Cookie等,并提供了丰富的示例代码。
本文详细介绍了Requests库的功能,包括发送HTTP请求、处理响应、上传文件、设置Cookie等,并提供了丰富的示例代码。
这里写目录标题
Request网络库介绍
在处理页面验证和Cookies时,urllib需要使用Opener和Handler来处理,这里有一个更方便的Python网络库——requests
功能:
1、发送HTTP请求
2、设置HTTP请求头
3、抓取二进制数据
4、POST请求
5、相应数据
6、上传文件
7、处理Cookie
8、维持会话
9、SSL证书验证
10、使用代理
11、超市处理
12、身份验证
13、打包请求
5.1 request使用案例1
使用get方法访问淘宝首页(https://www.taobao.com)并获取get方法返回值类型、状态码、响应体、Cookie等信息
import requests
# 访问淘宝首页
r = requests.get('https://www.taobao.com')
# 输出get方法返回值类型
print(type(r))
# 输出状态码
print(type(r.status_code))
# 输出响应体类型
print(type(r.text))
# 输出Cookie
print(r.cookies)
# 输出响应体
print(r.text)
5.2 get方法
使用get方法访问http://httpbin.org/get,并且使用URL和params参数的方式设置GET请求参数,并输出返回结果
import requests
# 用字典定义GET请求参数
data = {
'name':'Bill',
'country':'中国',
'age':20
}
# 发送HTTP GET请求
r = requests.get('http://httpbin.org/get?name=Mike&country=美国&age=40',params=data)
# 输出响应体
print(r.text)
# 将返回对象转换为json对象
print(r.json())
# 输出json对象中的country属性值,会输出一个列表,因为有2个GET请求参数的名字都是country
print(r.json()['args']['country'])
注:! 虽然该URL返回JSON格式的值,但原本是字符串类型的值,这里方便获取某个属性的值,使用json方法将其转换为Json对象。
5.3 设置请求头headers
使用get方法发送请求,并设置了一些请求头,包括User-Agent和一个自定义请求头name,其中name请求头的值是中文
import requests
from urllib.parse import quote,unquote
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
'name':quote('李青')
}
# 发送HTTP GET请求
r = requests.get('http://httpbin.org/get',headers=headers)
# 输出响应体
print(r.text)
# 输出name请求头的值,(需要解码)
print('Name:',unquote(r.json()['headers']['Name']))
5.4 get_binary方法
- get方法指定的URl不仅可以是网页,还可以是任何二进制文件,如png图像、pdf文档等。
- 对于二进制文件,尽管可以使用Response.text属性获取其内容,但显示的都是乱码。一般获取二进制数据,需要将数据保存到本地文件中。
- 所以需要调用Response.content属性获得bytes形式的数据,然后在使用相应的API将其保存在文件中。
import requests
# 抓取图像文件,其中http://t.cn/EfgN7gz是图像文件的短连接
r = requests.get('http://t.cn/EfgN7gz')
# 输出文件的内容,乱码
print(r.text)
# 将图像保存为本地文件(python从菜鸟到高手)
with open('Python从菜鸟到高手.png','wb') as f:
f.write(r.content)
5.5 使用post方法发送post请求
- 通过post方法可以向服务端发送POST请求,在发送POST请求时需要是定data参数,
- 该参数是一个字典类型的值,每一对key-value是一对POST请求参数(表单字段)
# 使用post方法想http://httpbin.org/post发送一个POST请求,并输出返回响应数据
import requests
data = {
'name':'Bill',
'country':'中国',
'age':20
}
# 向服务端发送POST请求
r = requests.post('http://httpbin.org/post',data=data)
# 输出响应体内容
print(r.text)
# 将返回对象转换为JSON对象
print(r.json())
# 输出表单中的country字段值
print(r.json()['form']['country'])
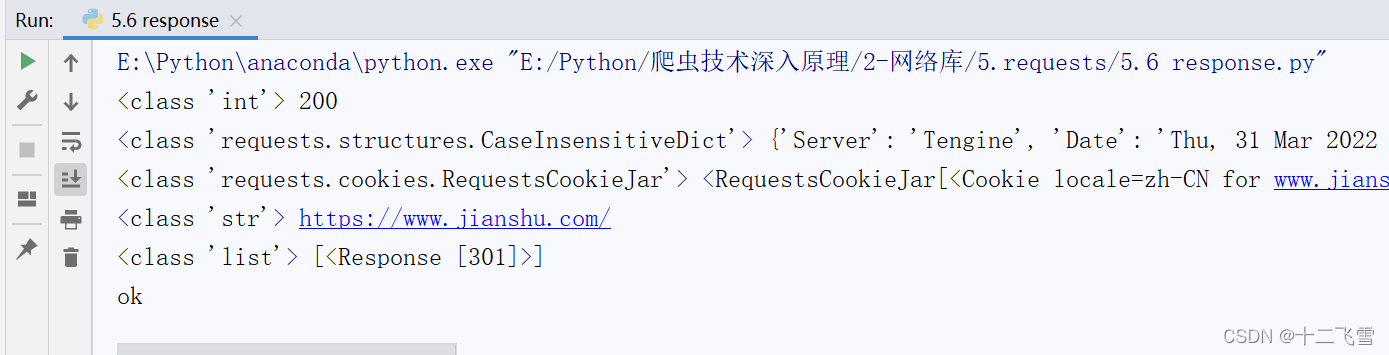
5.6 response请求响应结果
使用get方法向简书(https://www.jianshu.com)发送一个请求,然后获得并输出相应的响应结果
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36',
}
# 向简书发送GET请求
r = requests.get('http://www.jianshu.com',headers=headers)
# 输出状态码
print(type(r.status_code),r.status_code)
# 输出响应头
print(type(r.headers),r.headers)
# 输出Cookie
print(type(r.cookies),r.cookies)
# 输出请求的URL
print(type(r.url),r.url)
# 输出请求历史
print(type(r.history),r.history)
# 根据codes中的值判断状态码
if not r.status_code == requests.codes.okay:
print("failed")
else:
print("ok")
运行结果:
5.7 uploadfile上传文件
- 编写服务器端,并启动
ps = '''实现了将文件上传到服务端的程序,可以通过输入本地文件名来上传任何类型的文件'''
import os
from flask import Flask,request
# 定义服务端保存上传文件的位置
UPLOAD_FOLDER = 'uploads'
app = Flask(__name__)
# 用于接收上传文件的路由需要使用POST方法
@app.route('/',methods=['POST'])
def upload_file():
# 获取上传文件的内容
file = request.files['files']
if file:
# 将上传的文件保存到upload子目录中
file.save(os.path.join(UPLOAD_FOLDER, os.path.basename(file.filename)))
return "文件上传成功"
if __name__ == '__main__':
app.run()
- uploadfile.py编写并运行
import requests
print(type(open('Python从菜鸟到高手.png','rb')))
# 定义要上传的文件,字典中必须有一个key为file的值,值的类型是BufferReader,可以用open函数返回
files1 = {'files':open('Python从菜鸟到高手.png','rb')}
# 将本地图像文件上传到upload_server.py
rl = requests.post('http://127.0.0.1:5000',files=files1)
# 输出响应结果
print(rl.text)
files2 = {'files':open('Python从菜鸟到高手.png','rb')}
r2 = requests.post('http://127.0.0.1:5000',files=files2)
print(r2.text)
5.8 设置Cookie
两种方法设置Cookie
1、headers参数
2、cookies参数
先在网页上登录,通过Chrome浏览器的开发者工具获得登录后的Cookie,然后复制放到文件或程序中,当客户端请求网站是,
再将这些Cookie发送给服务端,尽管我们不知道用户名和密码,由于登录标识保存在Cookie中,所以给服务端发送Cookie,相当于登录
在前面4.3 request_header请求头中讲解了如何获取自己的cookie链接如下: 如何获取cookie.
import requests
from requests import cookies
r1 = requests.get('https://www.baidu.com')
# 输出所有Cookie
print(r1.cookies)
print(type(r1.cookies))
# 获取每一个Cookie
for key,value in r1.cookies.items():
print(key,'=',value)
# 获取简书首页内容定义了Host、User-Agent和Cookie请求头字段
headers = {
'Host':'www.jianshu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36',
'Cookie':'放入自己的cookie'
}
# 请求简书首页,并通过headers参数发送Cookie
r2 = requests.get('https://www.jianshu.com',headers=headers)
print(r2.text)
# 另一种设置Cookie的方式
headers = {
'Host':'www.jianshu.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
cookies = '放入自己的Cookie'
jar = requests.cookies.RequestsCookieJar()
# 将多个Cookie拆开,多个Cookie之间用分号;隔开
for cookie in cookies.split(';'):
# 得到Cookie的key和value,每一个Cookie的key和value之间用等号(=)分割
key,value= cookie.split('=',1)
# 将Cookie添加到RequestsCookieJar中
jar.set(key,value)
# 请求简书首页,并通过cookies参数发送cookie
r3 = requests.get('http://www.jianshu.com',cookies = jar,headers=headers)
print(r3.text)
5.9 使用Session对象
使用传统方式和Session对象向服务端发送请求,并通过URL设置Cookie。如果使用Session对象,多次发送的请求是在同一个Session中
import requests
# 不使用Session对象发送请求,其中set/name/Bill相当于想读无端编写一个名为name的cookie
# 值为Bill
requests.get('http://httpbin.org/cookies/set/name/Bill')
# 第2次发送请求,这2次请求不在同一个Session中,第1次请求发送的Cookie在第2次请求中是无法获得的
r1 = requests.get('http://httpbin.org/cookies')
print(r1.text)
# 使用Session
# 创建Session对象
session = requests.Session()
# 第1次发送请求
session.get('http://httpbin.org/cookies/set/name/Bill')
# 第2次发送请求
r2 = session.get('http://httpbin.org/cookies')
print(r2.text)
5.10 SSL签名证书
签名证书通常使用x509证书链,三类文件
1、key:私用秘钥(私钥),openssl格式,通常使用的是RSA算法
2、csr:证书请求文件,用于申请证书。在制作csr文件时,必须使用私钥来签署申请,还需要设置一个私钥
3、crt:是CA认证后的整数文件,这里的事CA是指证书颁发机构(Certificate Authority)也就是颁发数字证书的机构
生成证书文件需要使用openssl工具,https://www.openssl.org/source
也可以到下面的网站下载编译好的Windows版本的openssl
http://gnuwin32.sourceforge.net/packages/openssl.html
此处只做一点了解,不过多深入
5.11 proxy设置HTTP/HTTPS的代理
设置了HTTP和HTTPS的代理,并通过代理访问天猫首页,最后输出响应内容
import requests
proxies = {
'http':'http://144.123.68.152:25653',
'https':'http://144.123.68.152:25653'
}
# 通过代理请求天猫首页
r = requests.get('https://www.jd.com',proxies=proxies)
print(r.text)
5.12 Timeout超时
ps = '''本例设置了超时总时间,并分别设置了连接超时和读取超时,用于演示抛出的不同异常'''
import requests,requests.exceptions
try:
# 会抛出超时异常
r = requests.get('https://www.jd.com',timeout=0.01)
print(r.text)
except requests.exceptions.Timeout as e:
print(e)
# 抛出连接超时异常
requests.get('https://www.jd.com',timeout=(0.001,0.01))
# 永久等待不会抛出超时异常
requests.get('https://www.jd.com',timeout=None)
5.13 BasicAuth(HTTP Auth)
- Basic Auth是开放平台的两种认证方式,简单点说明就是每次请求API时都提供用户的username和password。
- 向服务端发送支持Basic验证的请求,如果验证成功,服务端会返回success
- 使用urllib库进行身份验证,需要用到HTTPPasswordMgrWithDefaultRealm、HTTPBasicAuthHandler类
- 使用requests只需设置auth参数即可,auth参数的值是一个HTTPBasicAuth对象,封装了对用户名和密码
# 需要启动一个端口号为5000的服务器
import requests
from requests.auth import HTTPBasicAuth
# 进行基础验证
r = requests.get('http:localhost:5000',auth=HTTPBasicAuth('bill','1234'))
print(r.status_code)
print(r.text)
5.14 Request对象封装打包
使用Request对象封装请求(打包),通过Session.send方法发送请求,然后输出响应结果
from requests import Request,Session
url = 'http://httpbin.org/post'
data = {
'name':'Bill',
'age':30
}
headers = {
'country':'China'
}
session = Session()
# 封装请求数据
req = Request('post',url,data=data,headers=headers)
# 返回requests.models.Response对象
prepared = session.prepare_request(req)
# 发送请求
r = session.send(prepared)
print(type(r))
print(r.text)
返回的requests.models.Response对象中可以看到设置的请求头headers和数据data
拓展:Twisted异步模型
Twisted是用Python实现的基于事件驱动的网络引擎框架。
常用编程模型:
1、同步编程模型
线程中的任务都是顺序执行
2、线程编程模型(效率最高)
将任务分解启动多线程执行
3、异步编程模型
一个任务切换到另一个任务,要么是这个任务被阻塞,要么是这个任务被执行,调度由程序员来做
Q:为什么选择使用异步模型,而不选择高效率的线程模型?
A:1、线程模型使用复杂,且不可控制调度
2、如果有一两个任务需要与用户交互,使用异步模型可以立即切换,过程可以控制
3、任务之间相互独立,任务内部交互很少。
Reactor(反应堆)模式(一种设计模式)
使用异步编程模型需要在循环中执行所有的非阻塞Socket任务,并利用select模块中的select方法见识所有的Socket是否有数据需要接收
Twisted要点:
1、Twisted的Reactor模式必须通过run函数启动
2、Reactor循环是在开始的进程中运行的,也就是运行在主进程中
3、一旦启动Reactor,就会一直运行下去。Reactor会在程序的控制之下
4、Reactor循环并不会消耗任何CPU资源
5、并不需要显式创建Reactor循环,只要导入reactor模块就可以了。Reactor是单例模式,一个程序只有一个Reactor
案例hello
ps = '''
关于Hello world中的函数回调:
1、reactor模式是单线程的
2、Twisted实现了reactor循环,无需手动
3、仍需框架来调用自己的代码来完成业务逻辑
4、用为单线程中运行,想要运行自己的代码,必须在reactor循环中调用他们
5、reactor实现并不知道调用代码中的哪个函数
'''
def hello():
print('Hello,How are you?')
from twisted.internet import reactor
# 执行回调函数
reactor.callWhenRunning(hello)
print('Starting the reactor.')
reactor.run()
client和server案例
- 利用Twisted框架实现一个时间戳服务端程序,启动可以等待时间戳客户端程序连接
from twisted.internet import protocol,reactor
from time import ctime
port = 9876
class MyProticol(protocol.Protocol):
# 当客户端连接到服务端后,调用该方法
def connectionMade(self):
# 获取客户端的IP
client = self.transport.getPeer().host
print('客户端',client,'已经连接')
def dataReceived(self, data):
# 接收到客户端发送过来的数据后,想客户端返回服务器的数据
self.transport.write(ctime().encode(encoding='utf-8') + b' ' + data)
# 创建Factory对象
factory = protocol.Factory()
factory.protocol = MyProticol
print('正在等待客户端连接')
# 监听端口号,等待客户端的请求
reactor.listenTCP(port,factory)
reactor.run()
- 利用Twisted框架实现一个时间戳客户端程序,在Console中输入字符串
- 然后按回车键将字符串发送给时间戳服务端,最后时间戳服务端会返回服务器时间和发送给服务器的字符串
# 导入protocol模块和reactor模块
from twisted.internet import protocol,reactor
host = 'localhost'
port = 9876
# 定义回调类
class Myprotocol(protocol.Protocol):
# 从Console中采集要发送给服务器的数据,按回车键后,会将数据发送给服务器
def sendData(self):
data = input('>')
if data:
print('...正在发送 %s' % data)
# 将数据发送给服务器
self.transport.write(data.encode(encoding='utf-8'))
else:
# 发送异常后,断开连接
self.transport.loseConnection()
# 发送数据
def connectionMade(self):
self.sendData()
def dataReceived(self,data):
# 输出接收到的数据
print(data.encode('utf-8'))
# 调用sendData函数,从Console采集要发送的数据
self.sendData()
# 工厂类
class MyFactory(protocol.ClientFactory):
protocol = Myprotocol
clientConnectionLost = clientConnectionFailed = lambda self,connector,reason:reactor.stop()
# 连接host和port,以及MyFactory类的实例
reactor.connectTCP(host,port,MyFactory())
reactor.run()


















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









