2025-07-06 23:19:30 [scrapy.extensions.telnet] INFO: Telnet Password: d45adb2d404b9cba
2025-07-06 23:19:30 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats',
'scrapy.extensions.throttle.AutoThrottle']
2025-07-06 23:19:30 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2025-07-06 23:19:30 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2025-07-06 23:19:30 [scrapy.middleware] INFO: Enabled item pipelines:
['nepu_spider.pipelines.ContentCleanPipeline',
'nepu_spider.pipelines.DeduplicatePipeline',
'nepu_spider.pipelines.SQLServerPipeline']
2025-07-06 23:19:30 [scrapy.core.engine] INFO: Spider opened
2025-07-06 23:19:30 [info] INFO: ✅ 成功连接到 SQL Server 数据库
2025-07-06 23:19:30 [info] INFO: ✅ 数据库连接测试通过
2025-07-06 23:19:30 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2025-07-06 23:19:30 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2025-07-06 23:19:30 [info] INFO: 🚀 开始爬取东北石油大学官网...
2025-07-06 23:19:30 [info] INFO: 初始URL数量: 14
2025-07-06 23:19:30 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/tzgg.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:33 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/xxgk/xxjj.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:36 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/jgsz/dzglbm.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:38 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <404 https://www.nepu.edu.cn/jgsz/xysz.htm>: HTTP status code is not handled or not allowed
2025-07-06 23:19:39 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/rcpy1.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:40 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/kxyj/kygk1.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:40 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/szdw/szgk.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:41 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/zsjy1.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:42 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/xtgz1.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:42 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/gjjl/xjjl.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:43 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <404 https://www.nepu.edu.cn/xyfg.htm>: HTTP status code is not handled or not allowed
2025-07-06 23:19:44 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <404 https://www.nepu.edu.cn/xsc/xsgz.htm>: HTTP status code is not handled or not allowed
2025-07-06 23:19:44 [scrapy.core.scraper] ERROR: Spider error processing <GET https://www.nepu.edu.cn/xxgk/xrld.htm> (referer: None)
Traceback (most recent call last):
File "D:\annaCONDA\Lib\site-packages\twisted\internet\defer.py", line 892, in _runCallbacks
current.result = callback( # type: ignore[misc]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "D:\annaCONDA\Lib\site-packages\scrapy\spiders\__init__.py", line 76, in parse
raise NotImplementedError(
NotImplementedError: InfoSpider.parse callback is not defined
2025-07-06 23:19:45 [scrapy.spidermiddlewares.httperror] INFO: Ignoring response <404 https://www.nepu.edu.cn/jxky/jwtz.htm>: HTTP status code is not handled or not allowed
2025-07-06 23:19:45 [scrapy.core.engine] INFO: Closing spider (finished)
2025-07-06 23:19:45 [info] INFO: ✅ 数据库连接已关闭
2025-07-06 23:19:45 [info] INFO: 🛑 爬虫结束,原因: finished
2025-07-06 23:19:45 [info] INFO: 总计爬取页面: 0
2025-07-06 23:19:45 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 3312,
'downloader/request_count': 14,
'downloader/request_method_count/GET': 14,
'downloader/response_bytes': 74925,
'downloader/response_count': 14,
'downloader/response_status_count/200': 10,
'downloader/response_status_count/404': 4,
'elapsed_time_seconds': 14.564797,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2025, 7, 6, 15, 19, 45, 288206),
'httpcompression/response_bytes': 188892,
'httpcompression/response_count': 10,
'httperror/response_ignored_count': 4,
'httperror/response_ignored_status_count/404': 4,
'log_count/ERROR': 10,
'log_count/INFO': 21,
'log_count/WARNING': 1,
'response_received_count': 14,
'scheduler/dequeued': 14,
'scheduler/dequeued/memory': 14,
'scheduler/enqueued': 14,
'scheduler/enqueued/memory': 14,
'spider_exceptions/NotImplementedError': 10,
'start_time': datetime.datetime(2025, 7, 6, 15, 19, 30, 723409)}
2025-07-06 23:19:45 [scrapy.core.engine] INFO: Spider closed (finished)





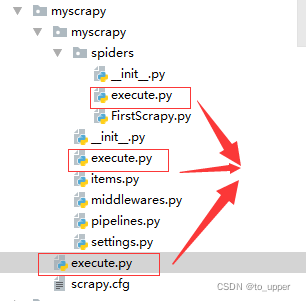
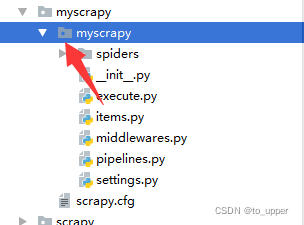
 本文介绍了在使用Scrapy框架过程中遇到的一种常见异常及其解决方法。通过调整execute.py文件的位置及确保爬虫类正确继承CrawlSpider基类,可以有效避免异常发生。同时,文章还强调了响应处理函数应命名为parse。
本文介绍了在使用Scrapy框架过程中遇到的一种常见异常及其解决方法。通过调整execute.py文件的位置及确保爬虫类正确继承CrawlSpider基类,可以有效避免异常发生。同时,文章还强调了响应处理函数应命名为parse。

















 8721
8721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









