




 本文介绍了如何在PyTorch中使用BCELoss进行损失计算,包括基本用法和带权重的测试。通过示例代码展示了reduce参数对平均损失的影响,并给出了BCELoss的计算公式。
本文介绍了如何在PyTorch中使用BCELoss进行损失计算,包括基本用法和带权重的测试。通过示例代码展示了reduce参数对平均损失的影响,并给出了BCELoss的计算公式。
测试代码:
import torch import torch.nn as nn import math m = nn.Sigmoid() loss = nn.BCELoss(size_average=False, reduce=False) input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) lossinput = m(input) output = loss(lossinput, target) print("输入值:") print(lossinput) print("输出的目标值:") print(target) print("计算loss的结果:") print(output) print("自己计算的第一个loss:") print(-(target[0]*math.log(lossinput[0])+(1-target[0])*math.log(1-lossinput[0])))
输出为:输入值:tensor([ 0.6682, 0.6042, 0.7042])
输出的目标值:
tensor([ 0., 1., 1.])
计算loss的结果:
tensor([ 1.1032, 0.5038, 0.3506])
自己计算的第一个loss:
tensor(1.1032)
带权重的测试(输入的weight必须和target值的数目一致,默认为none):
测试代码:
import torch import torch.nn as nn import math m = nn.Sigmoid() weights=torch.randn(3) loss = nn.BCELoss(weight=weights,size_average=False, reduce=False) input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) lossinput = m(input) output = loss(lossinput, target) print("输入值:") print(lossinput) print("输出的目标值:") print(target) print("权重值") print(weights) print("计算loss的结果:") print(output) print("自己计算的第一个loss:") print(-weights[0]*(target[0]*math.log(lossinput[0])+(1-target[0])*math.log(1-lossinput[0])))
输出为:输入值:tensor([ 0.6637, 0.1873, 0.8684])
输出的目标值:
tensor([ 1., 1., 1.])
权重值
tensor([ 1.9695, 0.2139, -0.4034])
计算loss的结果:
tensor([ 0.8073, 0.3584, -0.0569])
自己计算的第一个loss:
tensor(0.8073)
size_average 和reduce 作用测试(默认都为True):官网上给出说明为:如果reduce为True,则

如果reduce为False,则size_average 不起作用。
测试代码:
import torch import torch.nn as nn import math m = nn.Sigmoid() weights=torch.randn(3) loss = nn.BCELoss(weight=weights,size_average=False, reduce=True) input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) lossinput = m(input) output = loss(lossinput, target) print("输入值:") print(lossinput) print("输出的目标值:") print(target) print("权重值") print(weights) print("计算loss的结果:") print(output) print("自己计算的第一个loss:") perres = [0,0,0] res = 0 for i in range(3): perres[i] = -weights[i]*(target[i]*math.log(lossinput[i])+(1-target[i])*math.log(1-lossinput[i])) res += perres[i] print(res)
输出为:输入值:tensor([ 0.2902, 0.6208, 0.2917])
输出的目标值:
tensor([ 1., 0., 0.])
权重值
tensor([ 0.6165, -1.3114, 0.4537])
计算loss的结果:
tensor(-0.3525)
自己计算的第一个loss:
tensor(-0.3525)
import torch import torch.nn as nn import math m = nn.Sigmoid() weights=torch.randn(3) loss = nn.BCELoss(weight=weights,size_average=True, reduce=True) input = torch.randn(3, requires_grad=True) target = torch.empty(3).random_(2) lossinput = m(input) output = loss(lossinput, target) print("输入值:") print(lossinput) print("输出的目标值:") print(target) print("权重值") print(weights) print("计算loss的结果:") print(output) print("自己计算的第一个loss:") perres = [0,0,0] res = 0 for i in range(3): perres[i] = -weights[i]*(target[i]*math.log(lossinput[i])+(1-target[i])*math.log(1-lossinput[i])) res += perres[i] print(res/3)输入值:
tensor([ 0.5891, 0.6687, 0.2319])
输出的目标值:
tensor([ 1., 1., 1.])
权重值
tensor([-0.1225, 1.8304, 0.4226])
计算loss的结果:
tensor(0.4298)
自己计算的第一个loss:
tensor(0.4298)
结论:
BCELoss的计算公式为:
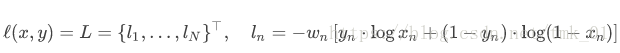


















 3054
3054





 到【灌水乐园】发言
到【灌水乐园】发言







