



第三周学习:ResNet+ResNeXt
Part 1:视频学习及论文阅读
1、ResNet
(1)ResNet网络的亮点:
①超深的网络结构(有突破1000层的网络)
解决了简单卷积层、池化层堆叠带来的梯度消失(假设每一层的误差梯度是小于1的数,在BP过程中,每向前传播一次,都要乘小于一的误差梯度,随着网络深度增加,越趋近于0)和梯度爆炸(相反假设每一层的误差梯度是大于1的数,在BP过程中,每向前传播一次,都要乘大于一的误差梯度,随着网络深度增加,梯度越来越大)现象(通常通过对数据进行标准化处理、权重初始化以及batch normalization解决)以及退化问题
②提出残差(residual)模块
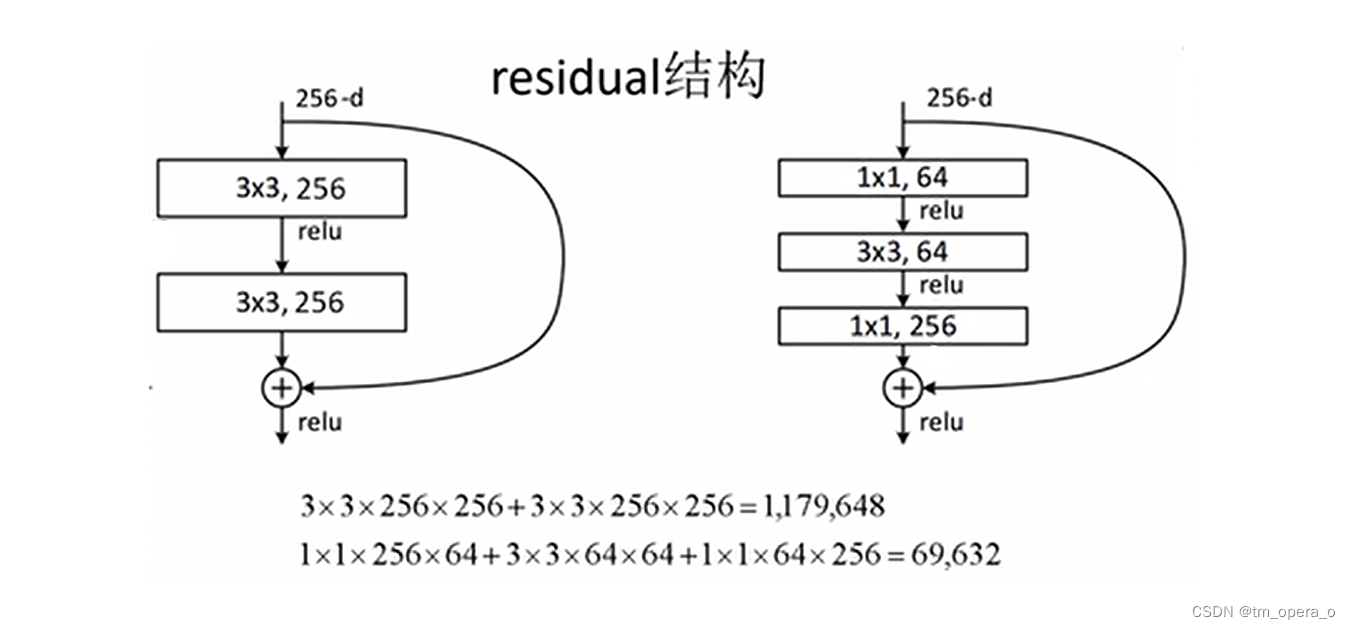
上图为两个常用的残差模块,左边是先3*3*256的卷积经过激活函数之后再进行3*3*256的卷积,然后将输入相加;右边是先经过1*1*64的卷积和激活函数,再3*3*256的卷积+激活函数,再进行1*1*256的卷积与输入相加。
左图的残差模块主要应用于层数较少的网络,而右边主要应用于层数较多的网络。主要是左边的残差模块所使用的参数较多,而右边较少导致。
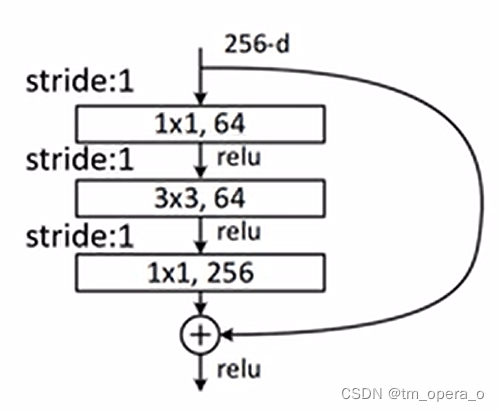
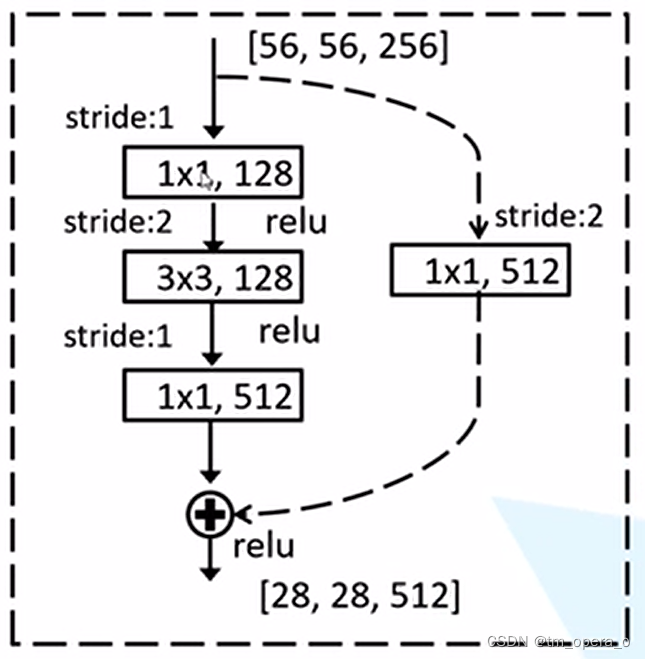
在进行skip connection之前,要求主分支与short cut的feature map一样,因此,有两种skip connection(如下两图),一种是第一张图片的实线残差结构,其主分支和输入的特征图一样,直接相加即可;另一种是第二张图片的虚线残差结构,输入因为步长为2的卷积而变得长和宽都缩短一半,且通道数由最后的1*1*512的卷积而变化,为保证主分支与short cut的feature map一样,在short cut上添加了一个1*1*512步长为2的卷积,从而保证特征图一致。(同时short cut有A、B、C三种,B效果最好)
③使用Batch normalization加速训练(从而放弃drop out方法)
Batch normalization的目的是使一批(Batch)的feature map满足均值为0,方差为1的分布规律,以此来加速网络训练速度,提高准确率。
(随着网络深度加深,模型收敛速度变慢,主要是由于 Internal covariate shift (ICS)现象以及梯度消失所导致。 ICS是网络中间层输入数据分布的不断变化,这样就导致网络后面层被迫去追随这种变化。在BN之前,有两种方法解决上述问题,一是使用较小的学习率,二是对参数初始化进行精心设计)
原理:
一般我们会对输入数据进行feature scaling,原因主要由于下图,如不进行feature scaling则在BP中就会变得比较慢,出现zip-zap现象。而进行feature scaling之后,就能很直接地用梯度下降法找到最优值。

在对一组图像进行预处理后,feature map会满足一定的分布规律,但是,在经过一层网络之后,便不一定会满足一定的分布规律了,同时,ICS现象也会对网络训练产生影响。因此我们进行BN,计算公式如下:
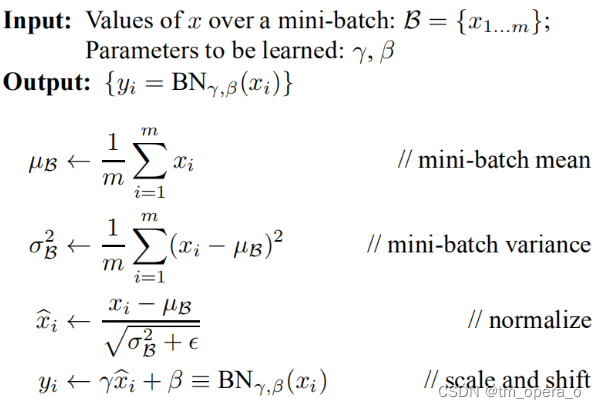
需要注意的是,这里的μ和σ都是n维向量。其中μ和σ是在正向传播过程中计算得到,β和γ在反向传播中得到,初始值分别为0和1,ε是一较小正数。
使用注意事项:
Ⅰ、训练时要将traning参数设置为True,在验证时将trainning参数设置为False。在pytorch中可通过创建模型的model.train()和model.eval()方法控制。
Ⅱ、batch size尽可能设置大点,设置小后表现可能很糟糕,设置的越大求的均值和方差越接近整个训练集的均值和方差。
Ⅲ、建议将bn层放在卷积层(Conv)和激活层(例如Relu)之间,且卷积层不要使用偏置bias(即参数b,以后面的参数β来替代其作用),因为没有用原因如下图。
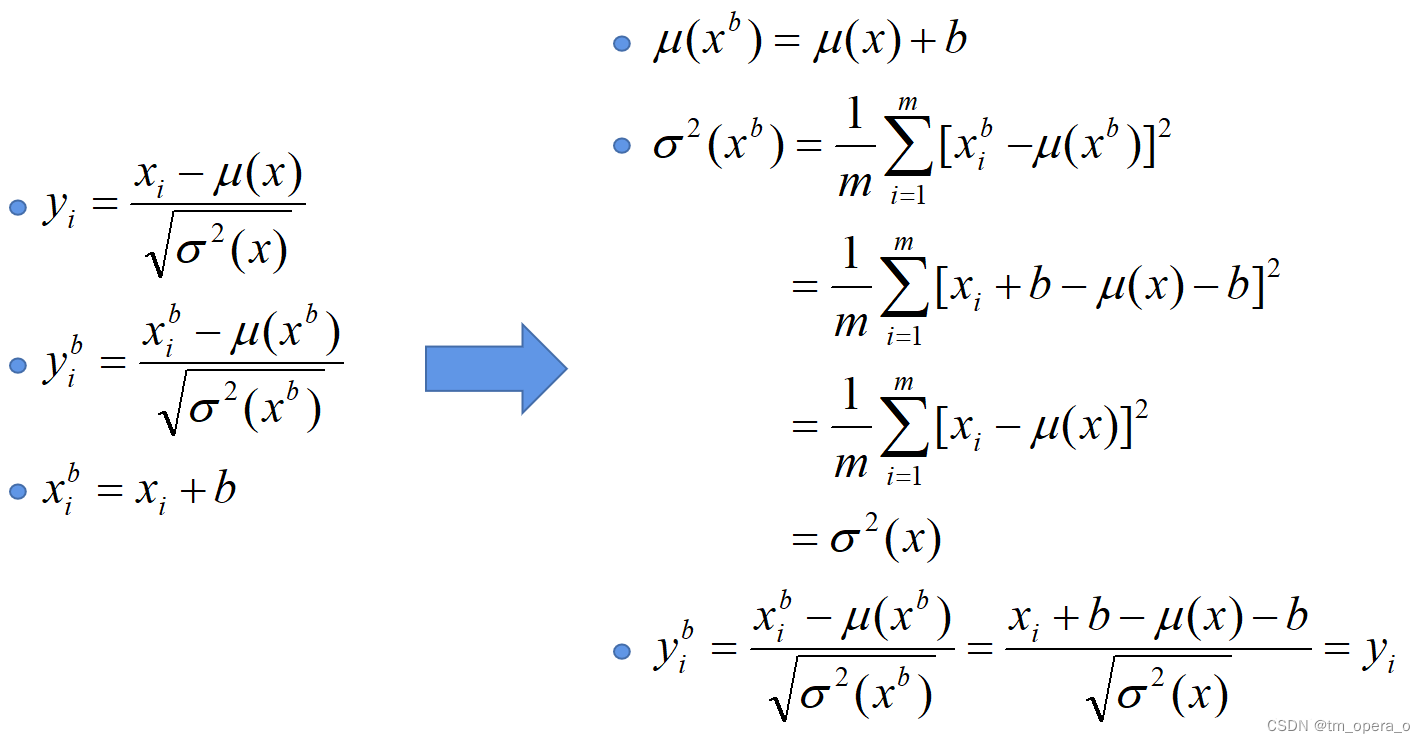
(2)迁移学习
优势:①能够快速训练出一个理想结果
②即使数据较小也能训练出理想的效果
注意:使用别人预训练模型参数时,要注意别人预处理方式
常见迁移学习方式:
①载入权重后训练所有参数
②载入权重后只训练最后几层参数
③载入权重后在原网络基础上再添加一层全连接层,进训练最后一个全连接层
3、ResNeXt
ResNext时ResNet的升级版,其继承了VGG的堆叠相同结构的构建块的思想,提出的原因主要在于传统的要提高模型的准确率,都是加深或加宽网络,但是随着超参数数量的增加(比如channels数,filter size等等),网络设计的难度和计算开销也会增加。ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量(得益于子模块的拓扑结构)。
(1)主要亮点:
①提出简洁、高度模块化的网络
②主要特色是聚合变换
③block都一致,超参数很少
④cardinality 来衡量模型复杂度
⑤ImageNet上发现,增加cardinality可提高网络性能且比增加深度和宽度更高效
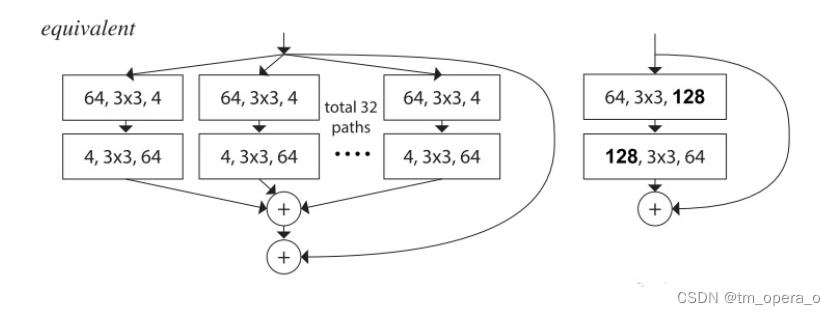
(2)最大的特点就是分组卷积的block:
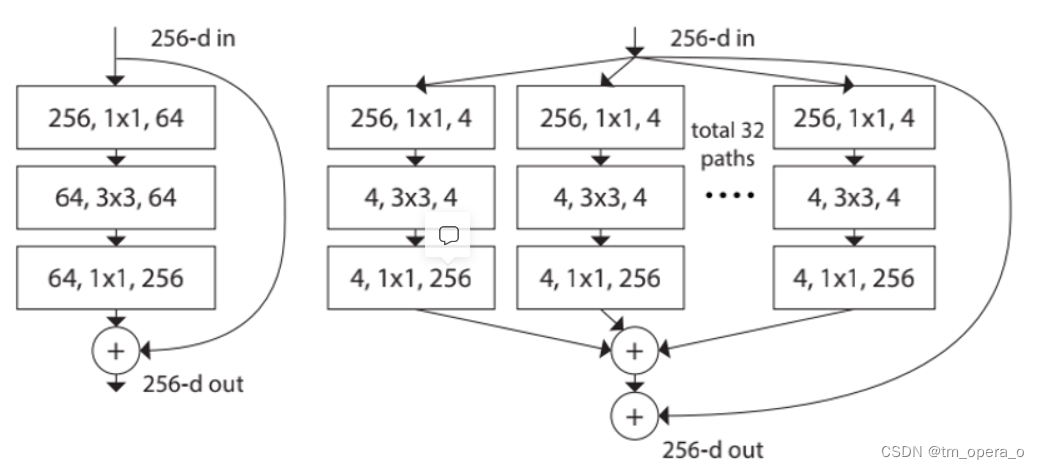
将左边的残差block更新到右边的block
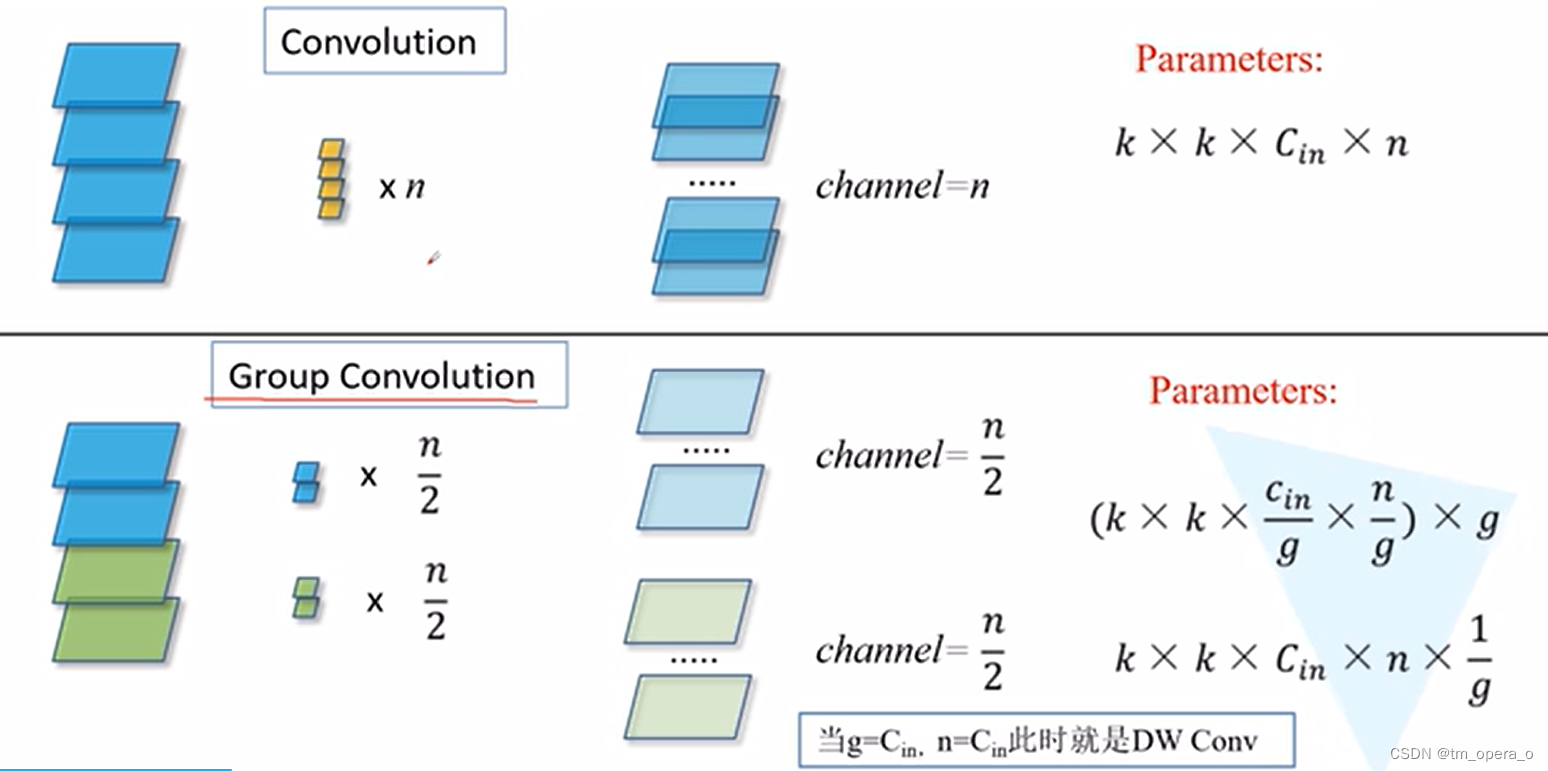
如上所示,组卷积即可减少超参数(宽度、卷积核大小、步幅等)。
以下三种block在数学计算上完全等价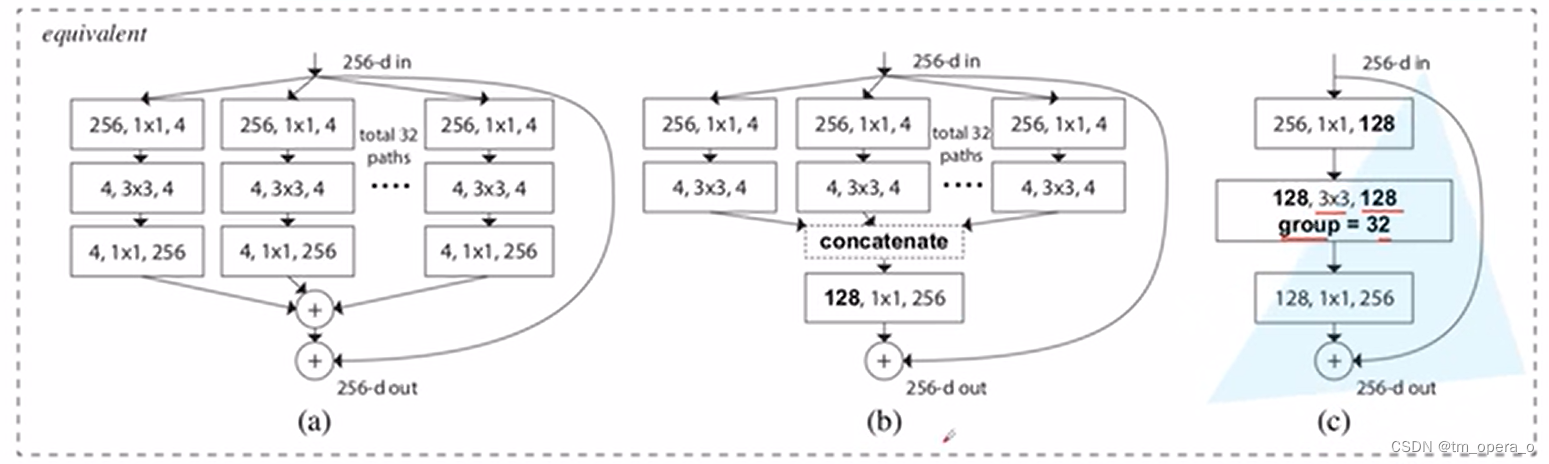
ResNet与ResNext网络结构对比:
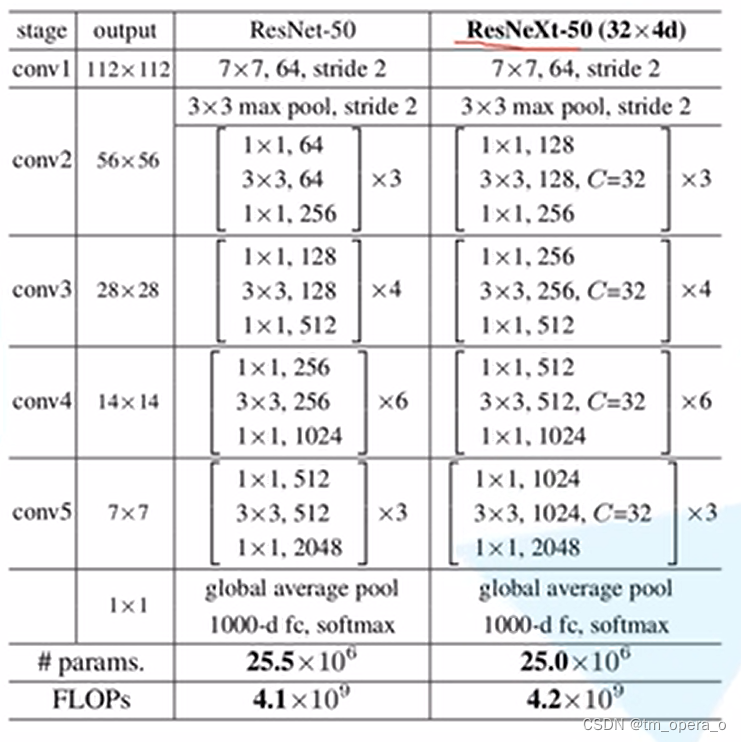
仅在块的深度大于三时,将resnet的block改为resnext的才会产生非凡的拓扑,而在深度为2时(如下图),重新构造将导致一个小而密集的模块。(左右两种等效,而右边的宽度小的多)
Part 2:代码练习
1、LeNet实现猫狗大战:
#首先引入相关的库
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import os接下来进行数据集的下载
#通过网站上的连接将数据集下载到googledrive上,并解压
from google.colab import drive
drive.mount('/content/drive')#搭载Google硬盘
! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip -P "/content/drive/My Drive/deepleaning"
#下载训练集和验证集(子文件夹内已经分好cat、dog)
! wget http://gaopursuit.oss-cn-beijing.aliyuncs.com/202007/dogs_cats_test.zip -P "/content/drive/My Drive/deepleaning"
#下载测试集
! unzip '/content/drive/My Drive/deepleaning/dogscats.zip' -d '/content/drive/My Drive/deepleaning'
! unzip '/content/drive/My Drive/deepleaning/dogs_cats_test.zip' -d '/content/drive/My Drive/deepleaning/dogscats'
#将训练集、验证集和测试集解压到同一目录下完成数据集的载入和预处理
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
#本次实验是基于上次的实验二进行的,所以归一化的参数直接用的实验二的
#同时,这次的图片尺寸不一,将所有图片统一剪裁成224*224
from torchvision import models,transforms,datasets
import shutil
data_dir = '/content/drive/My Drive/deepleaning/dogscats'
test_dir = os.path.join(data_dir, 'test')
test_raw_dir = os.path.join(test_dir, 'raw')
list_dir = os.listdir(test_dir)
os.mkdir(test_raw_dir)
for i in list_dir:
filename = ''.join(i.zfill(8))
shutil.copyfile(os.path.join(test_dir, i), os.path.join(test_raw_dir, filename))
#在test文件夹下构建raw子文件夹,便于之后的读取
train_dir = '/content/drive/My Drive/deepleaning/dogscats/train'
val_dir = '/content/drive/My Drive/deepleaning/dogscats/valid'
test_dir = '/content/drive/My Drive/deepleaning/dogscats/test'
dsets = {'train': datasets.ImageFolder(train_dir, transform_res),
'valid': datasets.ImageFolder(val_dir, transform_res),
'test': datasets.ImageFolder(test_dir, transform_res)}
dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid' , 'test']} #文件数目
dset_classes = dsets['train'].classes #数据集种类
loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size= 100,
shuffle=True, num_workers=6)
loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size = 10,
shuffle=False, num_workers=6)
loader_test = torch.utils.data.DataLoader(dsets['test'], batch_size = 100,
shuffle=False, num_workers=6)
#搭载数据集
接下来进行LeNet的定义,这次对网络的定义借用了上次的实验二,只是改了一下卷积核的参数,因为我们输入的图片尺寸大小为224*224*3,经过LeNet的卷积和下采样,最终输出是53*53*32
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, 5) #RGB三通道,所以是3
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.fc1 = nn.Linear(32 * 53 * 53, 120) #经过上面的卷积、池化最后输出是32*53*53
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32 * 53 * 53)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
# 网络放到GPU上
net = Net().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001) #Adam优化接下来定义训练函数,基本跟上次实验一样
def train_model(model,dataloader,size,epochs=1,optimizer=None):
model.train()
for epoch in range(epochs):
running_loss = 0.0
running_corrects = 0
count = 0
for inputs,classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs,classes)
optimizer.zero_grad()
loss.backward() #梯度是否回传
optimizer.step()
_,preds = torch.max(outputs.data,1)
# statistics
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
count += len(inputs)
#print('Training: No. ', count, ' process ... total: ', size)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(
epoch_loss, epoch_acc))进行模型的训练:
net_new = net;
net_new = net_new.to(device)
optimizer_net = optim.Adam(net.parameters(), lr=0.001)
train_model(net_new,loader_train,size=dset_sizes['train'], epochs=10, optimizer = optimizer_net)十轮后的训练结果:
接下来定义验证函数,用来测试模型并且保存模型的参数
#基本和训练函数差不太多,就是没有反向传播更新参数之类的过程了
def val_model(device, model, dataloader, size, criterion):
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, classes in dataloader:
inputs = inputs.to(device)
classes = classes.to(device)
outputs = model(inputs)
loss = criterion(outputs, classes)
_, preds = torch.max(outputs.data, 1)
running_loss += loss.data.item()
running_corrects += torch.sum(preds == classes.data)
epoch_loss = running_loss / size
epoch_acc = running_corrects.data.item() / size
print('Loss: {:.4f} Acc: {:.4f}'.format(epoch_loss, epoch_acc))
print('Finish validate')
torch.save(model, 'model1.pth')#保存模型进行模型的验证:
val_model(device, net_new, loader_valid, dset_sizes['valid'], criterion)结果并不大好: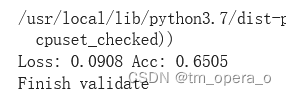
接下来定义测试函数:
def test_model(device, path, dataloader):
model = torch.load(path)
model.eval()
total_preds = []
for inputs, classes in dataloader:
inputs = inputs.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs.data, 1)
total_preds.extend(preds)
with open("result.csv", 'w+') as f:
for i in range(2000):
f.write("{},{}\n".format(i, total_preds[i]))
#最后输出csv结果文件,第一个是编号,第二个就是预测的标签进行测试,并将输出的结果文件从colab上下载下来:
test_model(device, 'model2.pth', loader_test)
from google.colab import files
files.download('result.csv')#下载结果文件把结果文件上传到AI研习社上

跟验证集的其实差不多,不是很好。
2、ResNet实现猫狗大战
有了上面的数据处理以及训练、验证和测试函数之后,其实再换ResNet来实现就变得很简单了,主要就是网络的构造,然后其他函数改一改就好了。巧的是,torchvision中提供ResNet网络结构,直接拿来用就行了,还可以用迁移学习,改变最后的fc层就行
ResNet网络结构:
model = torchvision.models.resnet34(pretrained = True)
model_new = model
model_new.fc = nn.Linear(512, 2, bias = True) #用ResNet32好像这里必须是512,不然会报错,反正我一开始一直报错,改了就好了,不知道是不是这个原因
model_new = model_new.to(device)训练函数还是一样的,把model改一下就行
train_model(model_new,loader_train,size=dset_sizes['train'], epochs=10, optimizer = optimizer)
10轮下训练结果: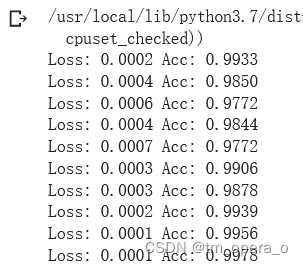
验证函数和测试函数也基本没变,把保存的模型和结果文件重命名下就行:
val_model(device, model_new, loader_valid, dset_sizes['valid'], criterion)
#验证resnet,这里我命名的是model2.pth
test_model(device, 'model2.pth', loader_test)
#测试resnet,最后保留的结果文件命名为了result_res.csv ResNet的验证函数输出:
明显好很多,将获得的结果文件上传到研习社上:

比LeNet好不少,但是我第一次epoch选的是5,怕不好改成的10,结果可能有点过拟合了,没有其他同学的效果那么好。
Part 3:问题回答
1、Residual learning
VGG提供了将同样的block堆叠增加网络深度的思路,但随着网络深度增加,退化现象显著出现,即随着网路层数的增加,模型的准确性开始饱和,然后迅速退化。然而令人意外的是这些退化并不是来源于“过拟合”,而且向一个适度的神经网络中增加更多的层还会导致更高的训练误差。为解决上述问题,即提出了残差结构,也即x+f(x)(通过short connection实现)
解决退化问题的思路:如果所添加的层可以被构造成恒等映射,那么更深的网路的学习误差应该会不高于浅层网络的训练误差。在残差网路的框架下,如果恒等映射是最优的结果,那么网络应该可以简单的去驱动新增加的非线性层的权重都变为0,从而达到拟合恒等映射的目的。
2、Batch Normailization 的原理
上面已经有过解释,主要就是只进行feature scaling的话,经过一层网络之后就不符合分布规律了,而不符合分布规律将会导致网络模型收敛变慢,出现zip-zap现象,而在后面网络中对整体进行归一化不现实,因此使用BN。
3、为什么分组卷积可以提升准确率?即然分组卷积可以提升准确率,同时还能降低计算量,分数数量尽量多不行吗?
分组卷积最早在AlexNet中出现,为了把feature maps分给多个GPU分别进行处理而进行分组卷积。ResNext里面提到没有发现分组卷积可以提升准确率。但是他确实通过分组降低了超参数,从而降低了计算量,但是分组尽量多还是不行的,极端情况下,每一个都是一组,则会退化成DW卷积
Part 4:其他
1、遇到的问题:
(1)数据集问题:这周学习占用最多的时间的一部分就是解决数据集的问题。这次的数据集一开始想从研习社下载之后解压再上传到colab上,结果上传要10+小时,而且vpn网络不稳定,上传着上传着就掉了,只能从头上传。后面找了篇博客,提供了一个下载链接,里面的数据还已经分好cat和dog了,解决很多麻烦,不过只有训练集。但是一开始解压了还是在虚拟机中,后面测试的时候因为他这个提前划分就变得比较麻烦了,参照了使用VGG迁移学习开启《猫狗大战挑战赛》_雷恩Layne的博客-优快云博客这篇博客,挂载谷歌硬盘解压后就好办多了。
(2)在用ResNet的时候,本来直接copy的LeNet的test函数,但是一直报错,到最后也没整明白咋回事,直接换到LeNet文件里面,改了下名字解决。
2、Res2Net
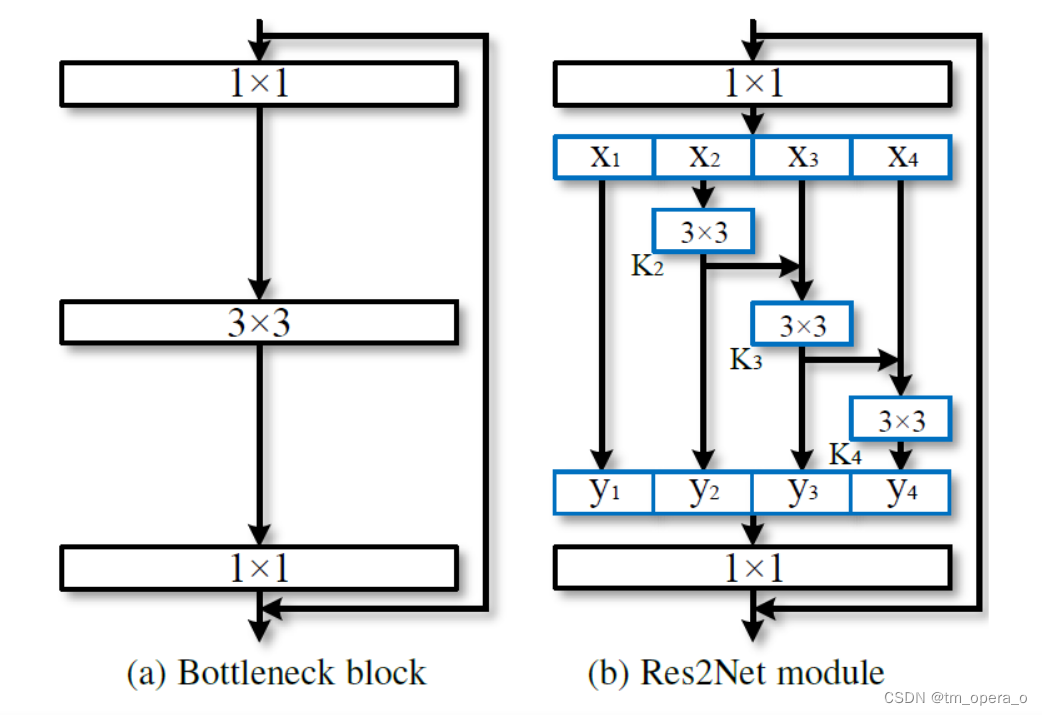
Res2Net的结构如上图(b)所示,主要就是另一种的残差网络与分组卷积的结合,能起到提高感受野的效果,假设左图的输入通道数是64,则对应右图的x的每一输入通道数是16,直接到
,
经过一次3*3的卷积后加到
上,以次类推。最后对y做concat还原。
Res2Net的更好的性能解释的不是很清楚,主要是扩大感受野对整体特征能更好的把握,便于过滤掉噪声梯度。

参数量方面,其实结构类似分组卷积,比分组卷积还要少一些。
3、multi-attention
多头注意力在《attention is all you need》中被提及,论文将模型分为多个头,形成多个子空间,每个头关注不同方面的信息。

没大看明白,贴下多头的流程吧:
流程
1通过不同的head得到多个特征表达,比如self-attention中的矩阵Q*K的内积然后得出的特征
2将所有的特征拼接到一起
比如self-attention中的Z=A/(A+B+C)*V1+B/(A+B+C)*V2+C/(A+B+C)*V3
3再通过一层全连接层实现降维(softmax,relu)
————————————————
版权声明:本文为优快云博主「丰。。」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.youkuaiyun.com/优快云XXCQ/article/details/113361805
















 2409
2409




 到【灌水乐园】发言
到【灌水乐园】发言







