




 本文深入解析了CountBinarySubstrings问题,介绍了如何遍历字符串,记录相同数字的连续出现次数,以此来找出具有相同数量0和1的连续子串数量。文章强调了正确理解题目的重要性。
本文深入解析了CountBinarySubstrings问题,介绍了如何遍历字符串,记录相同数字的连续出现次数,以此来找出具有相同数量0和1的连续子串数量。文章强调了正确理解题目的重要性。
Count Binary Substrings(Easy)
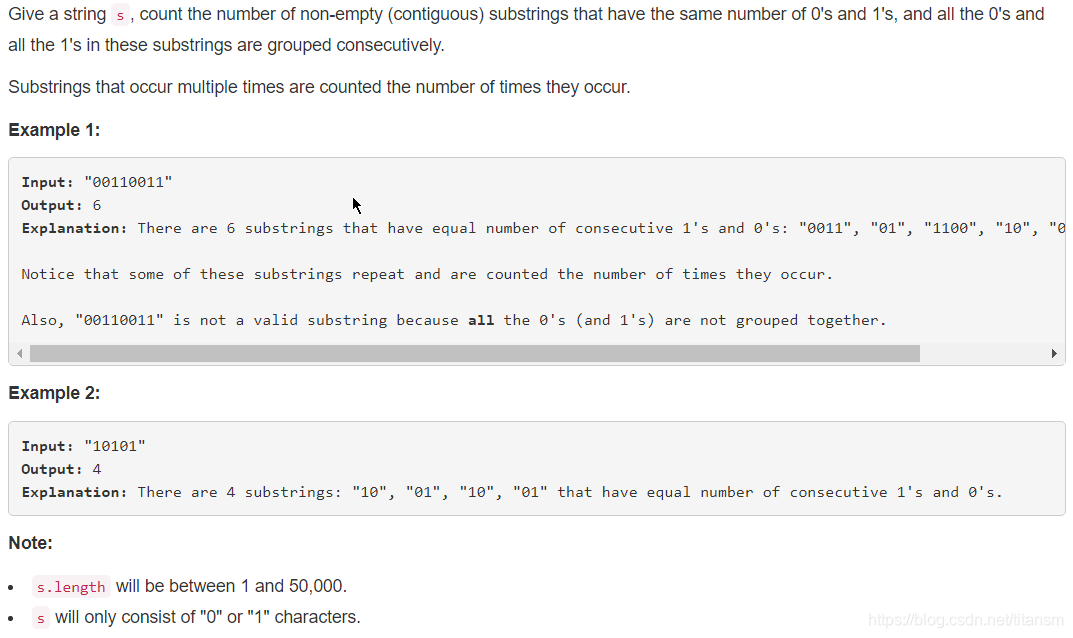
题目解析
该题在一开始给了我们一串由0和1组成的字符串,让我们判断字符串中的具有相同个数数字的连续子串的数量,并且所有的0和1都是连续分组的。
思路
这道题目相对比较复杂,我们需要判断所给数组中具有相同个数数字的子串的个数,就需要遍历整个数组,一遇到他们前后相等的情况,就做一次记录,直到他们前后不相等,在将记录的数量传给判断用的变量,该变量用于记录到当前为止同一个数字连续出现了多少此,例如:11100 中1出现了三次,就将这三次放在记录记录中,后面再记录0出现的次数,每出现一次我们的记录子串的总变量就+1,直到0出现的次数超过了1的次数。
结果
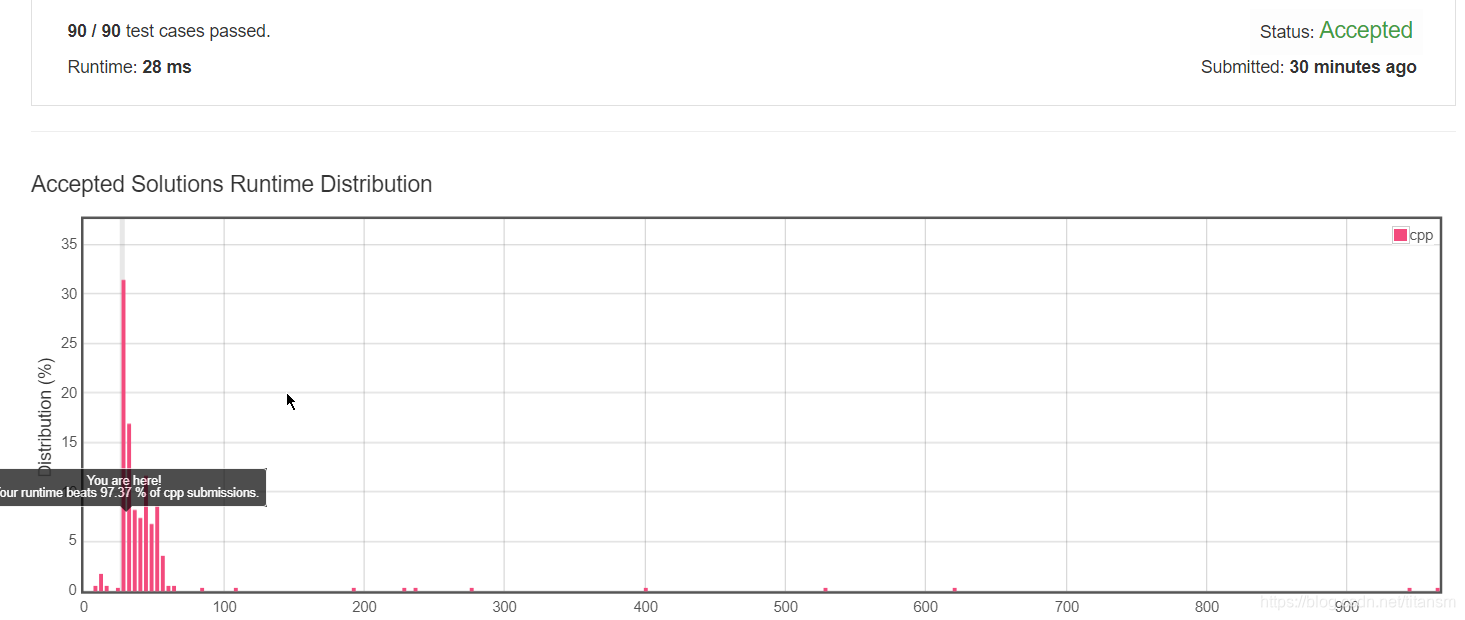
小结
题目多少回有点难度,没能太清晰的整理好思路,主要还是题意理解模糊,只有看懂了题目,才能往正确的方向想解决方法。

















 379
379

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









