




 泰迪智能科技推出的数据挖掘实战专栏通过Python和决策树算法,详细介绍了如何构建水质评价分类模型。首先,数据被划分为训练集和测试集,然后利用决策树进行训练。最终,模型在测试集上的准确率达到70.73%,表明模型对水质类型的分类效果良好,适用于实际的水质自动评价系统。
泰迪智能科技推出的数据挖掘实战专栏通过Python和决策树算法,详细介绍了如何构建水质评价分类模型。首先,数据被划分为训练集和测试集,然后利用决策树进行训练。最终,模型在测试集上的准确率达到70.73%,表明模型对水质类型的分类效果良好,适用于实际的水质自动评价系统。
泰迪智能科技(数据挖掘平台:TipDM数据挖掘平台)最新推出的数据挖掘实战专栏
专栏将数据挖掘理论与项目案例实践相结合,可以让大家获得真实的数据挖掘学习与实践环境,更快、更好的学习数据挖掘知识与积累职业经验
专栏中每四篇文章为一个完整的数据挖掘案例。案例介绍顺序为:先由数据案例背景提出挖掘目标,再阐述分析方法与过程,最后完成模型构建,在介绍建模过程中同时穿插操作训练,把相关的知识点嵌入相应的操作过程中。
为方便读者轻松地获取一个真实的实验环境,本专栏使用大家熟知的Python语言对样本数据进行处理以进行挖掘建模。
————————————————
模型构建
本案例采用决策树作为水质评价分类模型,模型的输入包括两部分,一部分是训练样本的输入,另一部分是建模参数的输入。各参数说明如表1所示。
表1 预测模型输入变量
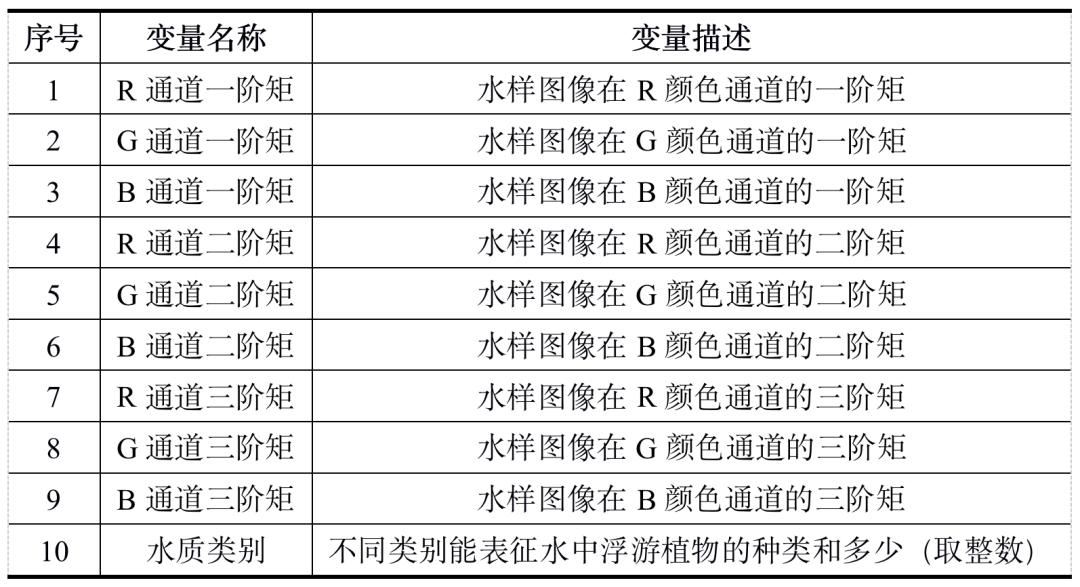
其中1~9均为输入的特征,对标准化后的样本进行抽样,抽取80%作为训练样本,剩下的20%作为测试样本,用于水质评价检验,使用决策树算法构建水质评价模型,如代码清单1所示。
代码清单1 数据划分及模型构建
from sklearn.model_selection import train_test_split# 数据拆分,训练集、测试集data_tr,data_te,label_tr,label_te = train_test_split(data,labels,test_size=0.2,random_state=10)from sklearn.tree import DecisionTreeClassifier# 模型训练
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7772
7772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









