







【前言】 结构体在日常代码创作过程中可以说是常客了,所以本章就要围绕结构体来讲解说明
首先先回顾一下结构体的基础知识

1.结构体基础知识
struct tag
{
member-list;
}variable-list;例如我们在定机票的时候我们都要了解乘客的基本信息:、
struct pass
{
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//身份证号
char flnu[10];//航班号
char seat[10];//座位号
};//注意分号不能丢2.特殊声明
特殊声明就是在声明结构体的时候,可以不完全声明
struct
{
int a;
char b;
float c;
}m;
struct
{
int a;
char b;
float c;
}a[20], * p;我们发现这两个结构体在声明的时候没有结构体标签,但一般不会这样省略
例如:让上述代码中的 p = &m;时,我们在编译的时候,编译器是会报错的,因为编译器会把这两个声明当作完全不同的两个类型。所以一般不要省略结构体标签
一般我们省略标签可能是感觉以后在引用的时候过于麻烦,那此时我们就可以对结构体进行重命名,让在以后的引用中简便一点
typedef struct node
{
int a;
char b;
float c;
}Node;这样用typedef进行重命名之后,在之后的引用时就直接用Node来表示。
3.结构体的自引用
我们在学习函数的时候见过了函数中的递归,那么在结构体中也有类似的定义.
struct Node
{
int data;
struct Node* next;
};
//我们发现在Node中引用Node的时候是用指针的类型。所以也就是说在结构体自引用时是用指针的方式来引用的。
4.结构体变量的定义和初始化
有了结构体的声明,类型,那么对结构体进行初始化就显得很简单了,直接上代码
struct Point
{
int x;
int y;
}p1; //声明类型的同时定义变量p1
struct Point p2; //定义结构体变量p2
//初始化:定义变量的同时赋初值。
struct Point p3 = { x, y };
struct Stu //类型声明
{
char name[15];//名字
int age; //年龄
};
struct Stu s = { "zhangsan", 20 };//初始化
struct Node
{
int data;
struct Point p;
struct Node* next;
}n1 = { 10, {4,5}, NULL }; //结构体嵌套初始化
struct Node n2 = { 20, {5, 6}, NULL };//结构体嵌套初始化5.结构体的内存对齐 (重点)
结构体的内存对齐是在结构体中关于结构体内存大小的计算.
#include<stdio.h>
struct s1
{
char c1;//1
int i;//4
char c2;//1
};
struct s2
{
char c3;//1
char c4;//1
int a;//4
};
int main()
{
struct s1 s;
struct s2 ss;
printf("%d\n",sizeof(s));//12
printf("%d\n",sizeof(ss));//8
return 0;
}按照我们平时的理解在s1中c1是char类型占1个字节,i是int类型占4个字节,c2也是char类型,相应的s2也是,那么s1和s2都应该是6个字节的大小,但实际上我们看代码却发现一个是12,一个是6,这是为什么呢? 这我们就要说说1结构体中的内存对齐了
直接上规律
1. 第一个成员在与结构体变量偏移量为0的地址处。
2. 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小的较小值。
VS中默认的值为8
3. 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整
体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
(1).
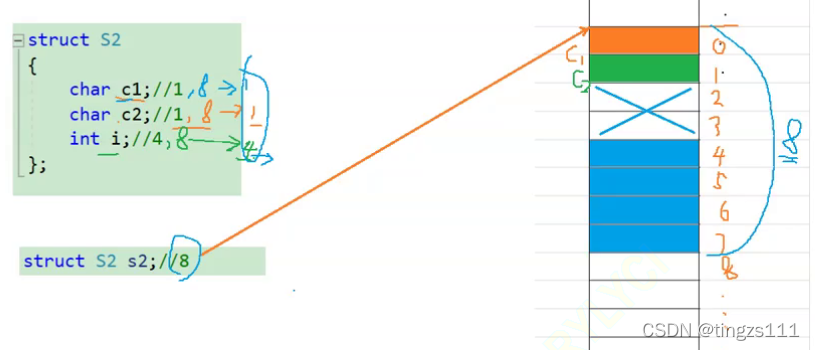
对于s2来说首先根据规律1.(第一个成员永远放在0的地址处)
然后在根据规律2(也就是c2所占字节要跟编译器中默认的对齐数的大小进行比较,并取其最小值)
也就是1和8进行大小比较,取其最小值,也就是1.
i也是相同的规律(i占了四个字节比8小,也就是取4的整数倍,因为c1和c2占据了0和1,后面的2,3都不是4的整数倍,所以到了4的位置,4是4的整数倍,所以就从4的位置向后占据4个字节)
然后在根据规3,结构体的大小要是结构体变量中最大数的整数倍(s2中也就是4的整数倍),因为我们c1,c2,i一共占据了(0~7)一共8个字节,也就是4的整数倍,所以s2一共就占用了8个字节
其中2,3号位置是浪费的。
(2).
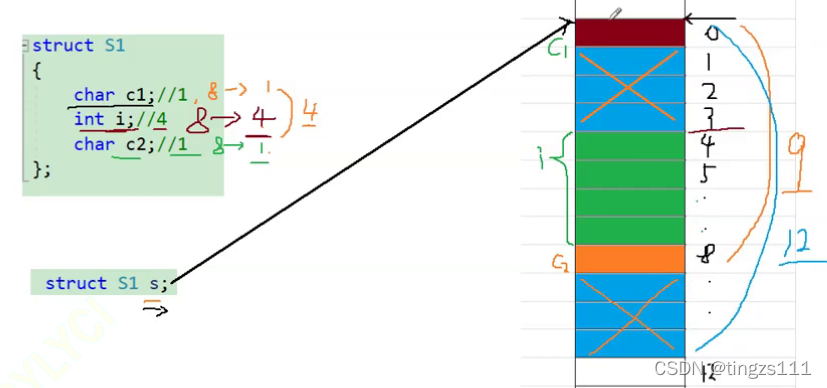
然后我们看s1为什么占用的是12个字节,同样的运用结构体内存对齐规律
首先第一个成员默认从0开始,因为第一个元素c1是char类型占据1个字节(也就是0的位置)
然后i是整形占据4个字节,i和对齐数8进行大小比较(也就是4和8比较,取较小值也就是4,并且要是其倍数)也就是从4开始占取4个位置(4~7)
然后同理c2和对齐数比较取1,也就占据了8的位置
然后一共占据了9个位置(0~8),然后根据规律3进行比较,我们会发现9不是4的倍数,然后就要接着向下取,一直取到与4的倍数最近的位置(12),所以s1一共就占用了12个字节
那么如果是嵌套式结构体呢?
下列s4的大小是多少呢?那么这个时候我们就要用到规律中的第四条了
4. 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整
体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
我们拿下面的例子来演示一下(说明一下s3的大小是16个字节,这里就不再为大家演示了哈,就当作一个练习,大家下来自己练习一下)
在s4中char c1占的是0的位置,然后进入s3;
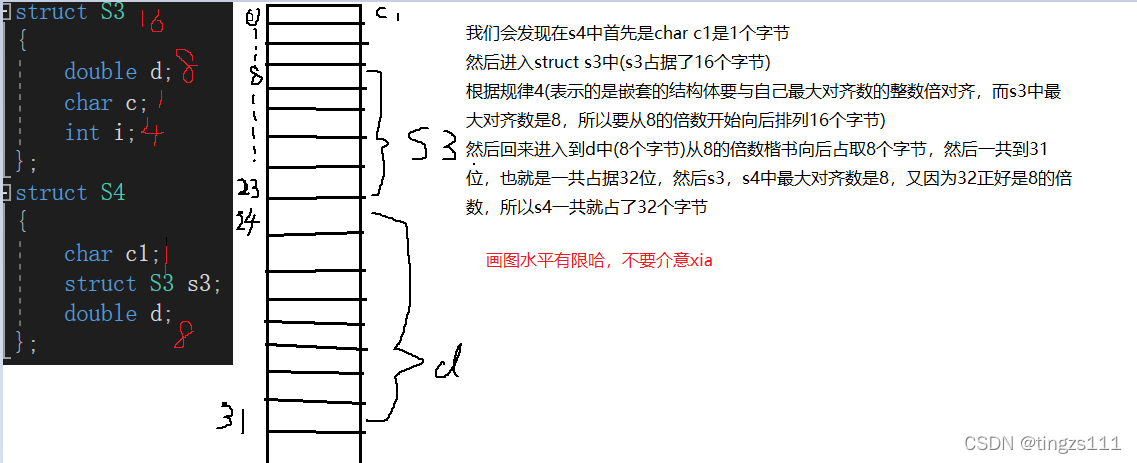
看了上边这几个关于结构体内存对齐的例子,这个时候我们就会产生思考,我们能不能让在结构体读取内存的时候少浪费一些不必要的空间呢?我们上上述代码中也发现了同一个结构体,相同的变量,只是变量的先后顺序发生了改变,相应占据的内存也随之发生改变。

就像结构体s1和结构体s2中的变量是一样的,但s1占了12个字节,而s2却只占用了8个字节
6.修改默认对齐数
(#pragma pack(X))//就是修改默认对齐数的定义。
接下来介绍一下怎么去修改编译器中的默认对齐数
(vs下默认对齐数是8,在Linux下没有默认对齐数,所以设定默认对齐数就是本身)
#pragma pcak(x)//X就表示修改的对齐数
#pragma pack(4)//修改默认对齐数为4
struct S1
{
char c1;
int i;
char c2;
};
#pragma pack()//取消设置的默认对齐数,还原为默认所以我们在认为结构体对齐不合适的时候,我们可以自己修改默认的对齐数,但是我还是简易不要轻易的修改编译环境的默认对齐数,因为每个编译环境下的默认对齐数的设定都有人家设定的道理和理由,但是如果我们要想让结构体在对齐的时候不浪费那么多的空间,那么简易大家在定义结构体内容时尽量把占用空间小的变量集中在一起.
【结语】其实接下来还有一个结构体的传参,但我相信大家肯定是知道结构体是真没传参的,所以我在这里就不为大家举例介绍了,也算是偷了个懒吧。
这是博主第一次正式的写文章,所以肯定有很多不足的地方,还请大家多多包涵和理解,我也相信自己会在以后的学习中多多改善。感谢大家,感谢支持


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









