







目录
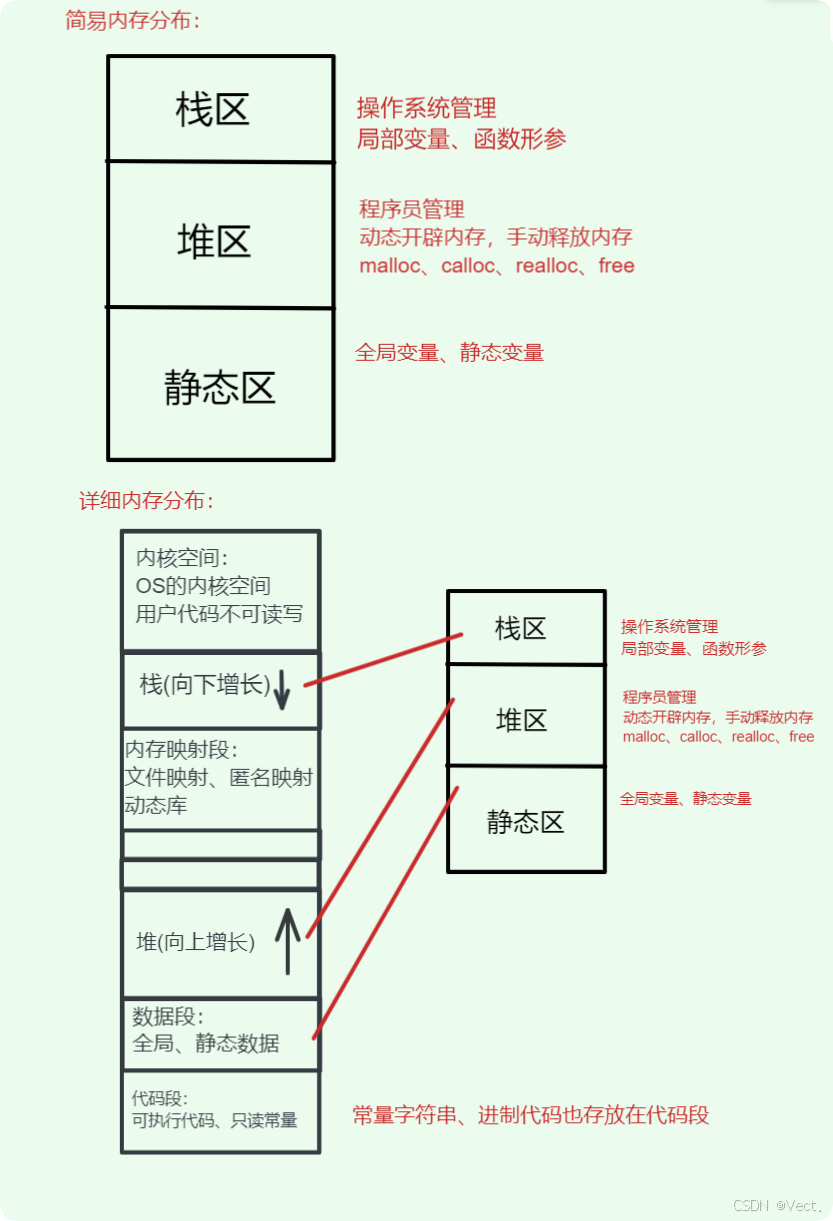
1.内存划分
栈区(Stack)
由编译器自动管理,采用LIFO(last in first out)结构存储函数调用信息:
- 存储局部变量、函数参数、返回地址
- 分配/回收通过移动栈指针实现
- 典型大小1-8MB,超过会导致栈溢出(如递归过深时)
- 特点:存取效率高,空间固定不可扩展
堆区(Heap)
动态内存管理区域:
- 通过malloc/new手动申请,free/delete释放
- 空间仅受物理内存限制(理论上可达数GB)
- 容易产生内存泄漏(未释放)和碎片问题
全局/静态存储区
包含两个子区域:
- .data段:已初始化的全局/静态变量
- .bss段:未初始化的全局/静态变量(程序加载时清零)
- 生命周期与程序周期相同
常量存储区
存放不可修改数据:
- 字符串常量(如"hello")
- const修饰的全局常量
- 试图修改会触发段错误(如char* ptr = "abc"; ptr[0]='d')
代码区(Text Segment)
存储可执行指令:
- 包含编译后的机器码
- 具有只读属性,防止意外修改
- 可能包含编译器优化的内联代码
内存映射区(Memory Mapping)
操作系统级管理区域:
- 用于加载动态链接库
- 实现文件映射I/O(mmap系统调用)
- 用户可创建匿名映射区
2.namespace的引入
看段代码:
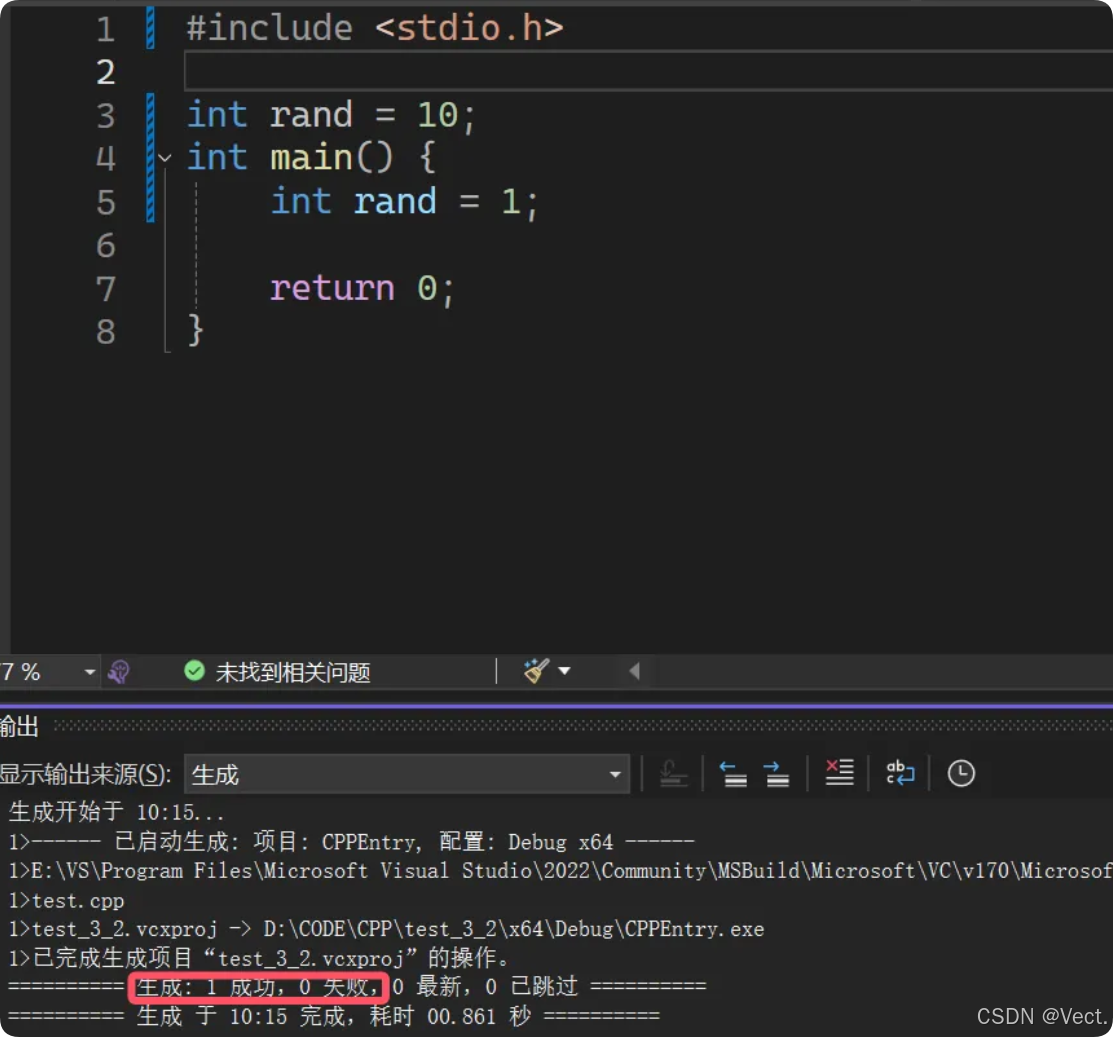
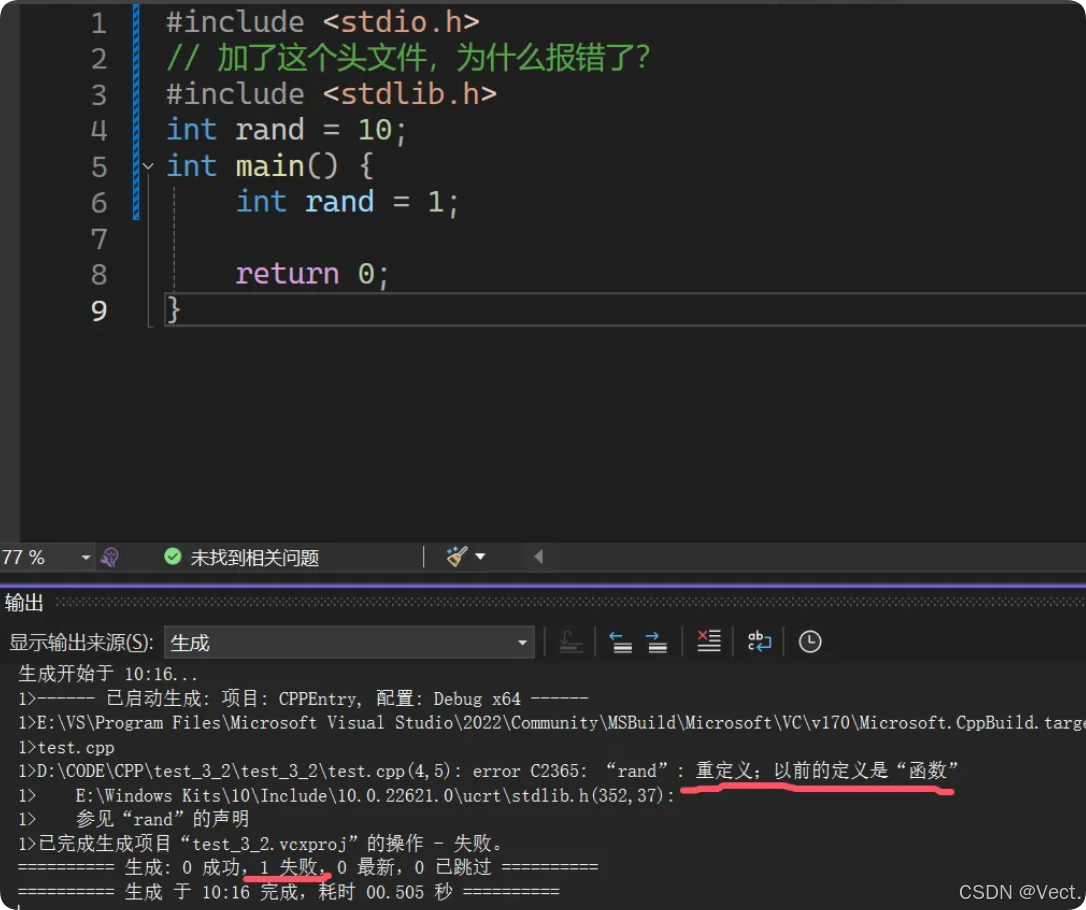
加了这个头文件,为什么报错了?理论上全局变量和局部变量可以同名,同名就遵循局部优先原则,但是rand是stdlib库里的函数名,我们命名与这个函数同名,引发错误
而namespace的价值就体现于此:
变量和函数的名称都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的
3.namespace的定义
- 命名空间是一个声明性区域,为其内部的标识符(类型、函数和变量等的名称)提供一个范围
- namespace本质是定义出一个域,这个域跟全局域各自独立,不同的域可以定义同名变量,所以下面的rand不在冲突了
- namespace只能定义在全局,并且可以嵌套定义
- 项目工程中多文件中定义的同名namespace会认为是同一个namespace,不会冲突
- C++标准库都放在⼀个叫std(standard)的命名空间中
//定义
namespace name{
// fuction type variable
}
// 例如
namespace vect{
int rand = 10;
double d = 1.1;
struct ListNode {
int val;
struct ListNode* next;
};
void Swap(int* pa, int* pb);
}
int main() {
// 默认访问函数指针的地址
printf("%p\\n", rand);
// 访问vect中的rand
printf("%d\\n", vect::rand);
return 0;
}
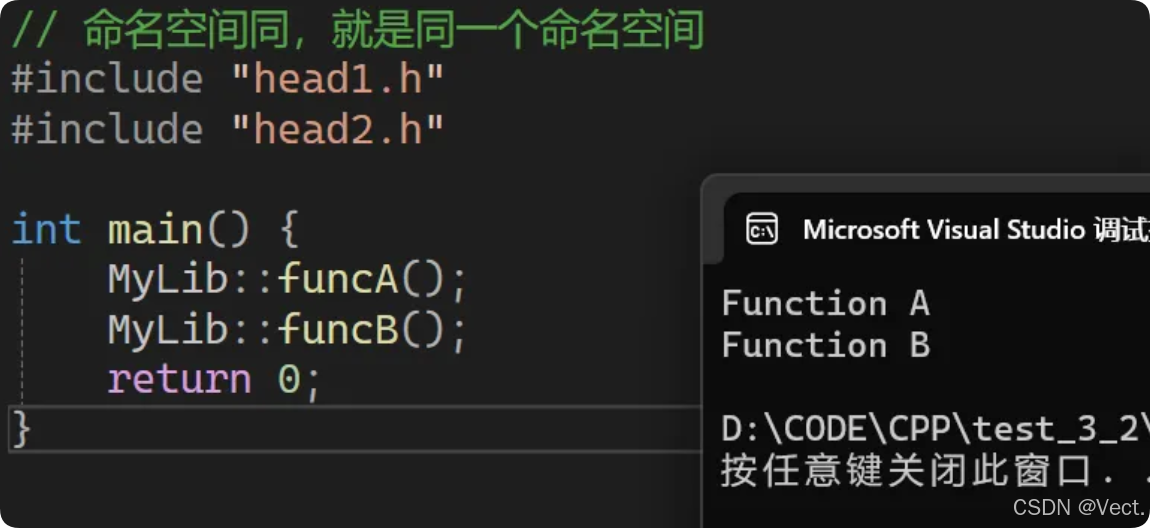
// 多文件命名空间同名,默认就是同一个命名空间
#include "head1.h"
#include "head2.h"
// test.cpp
int main() {
MyLib::funcA();
MyLib::funcB();
return 0;
}
// head1.h
namespace MyLib {
void funcA() { cout << "Function A\\n"; }
}
// head2.h
namespace MyLib { // 合并到同一个命名空间
void funcB() { cout << "Function B\\n"; }
}
输出结果:
4.namespace的使用
编译查找⼀个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间里面去查找。
我们可以将局部域想象成自己家的菜地,全局域是野地,而命名空间则是别人家的菜地
我们只能采摘自己家的菜地或者人人都可采摘的野地,别人家的菜地未经允许是不可采摘的
我们要使⽤命名空间中定义的变量/函数,有三种方式:
- 指定命名空间访问,项目中推荐这种方式
- using将命名空间中某个成员展开,项目中经常访问的不存在冲突的成员推荐这种方式
- 展开命名空间中全部成员,项目不推荐,冲突风险很大,OJ练习中为了方便通常全部展开
这里引入域作用限定符“::”
“::”的左边为空,默认搜查全局域
// 指定特定成员访问
namespace bit {
int val = 1;
}
int val = 10;
void fuc() {
int val = 11;
// 访问函数内部变量
printf("%d\n", val);
// 访问全局变量
printf("%d\n", ::val);
}
int main() {
int val = 9;
// 访问局部变量
printf("%d\n", val);
// 访问全局变量
printf("%d\n", ::val);
// 访问命名空间变量
printf("%d\n", bit::val);
printf("\n");
fuc();
return 0;
}
输出结果: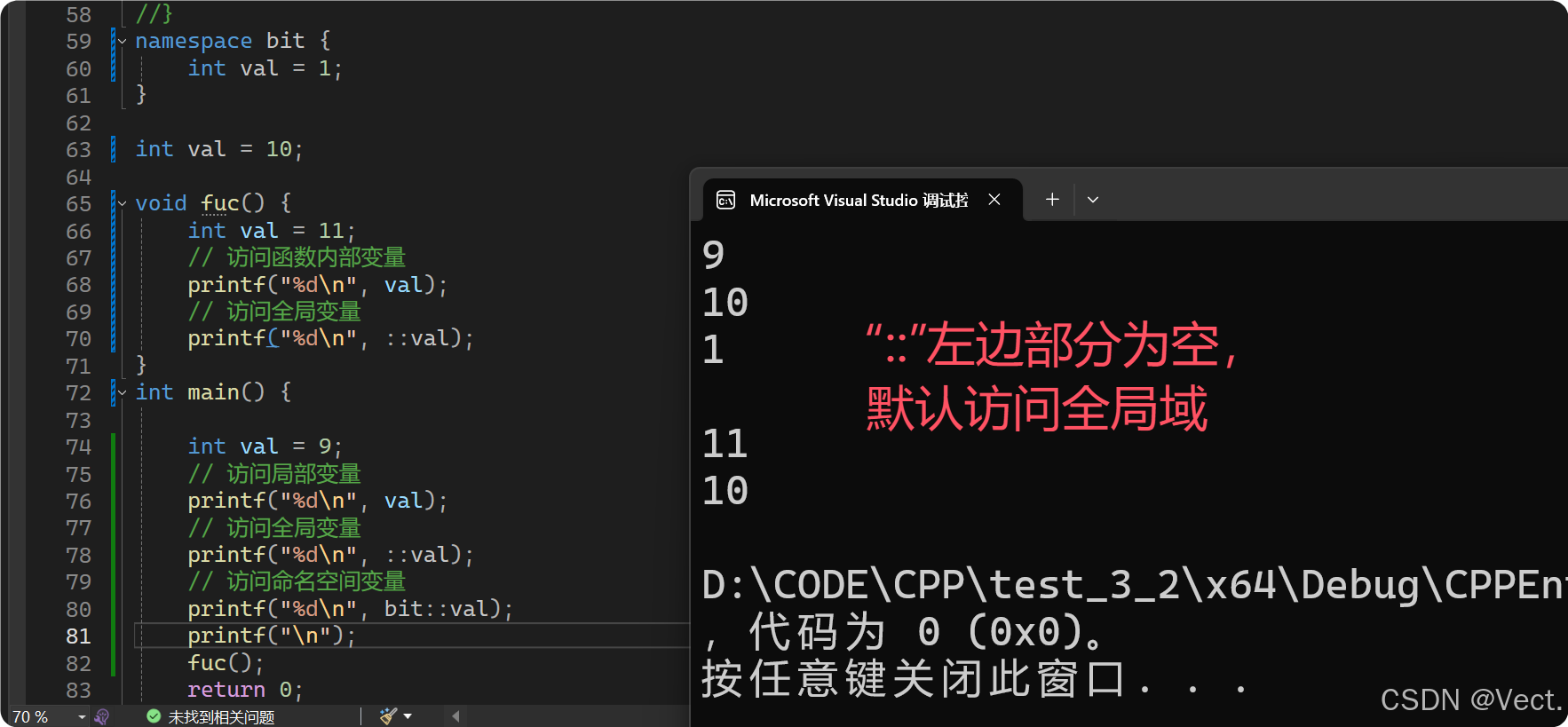
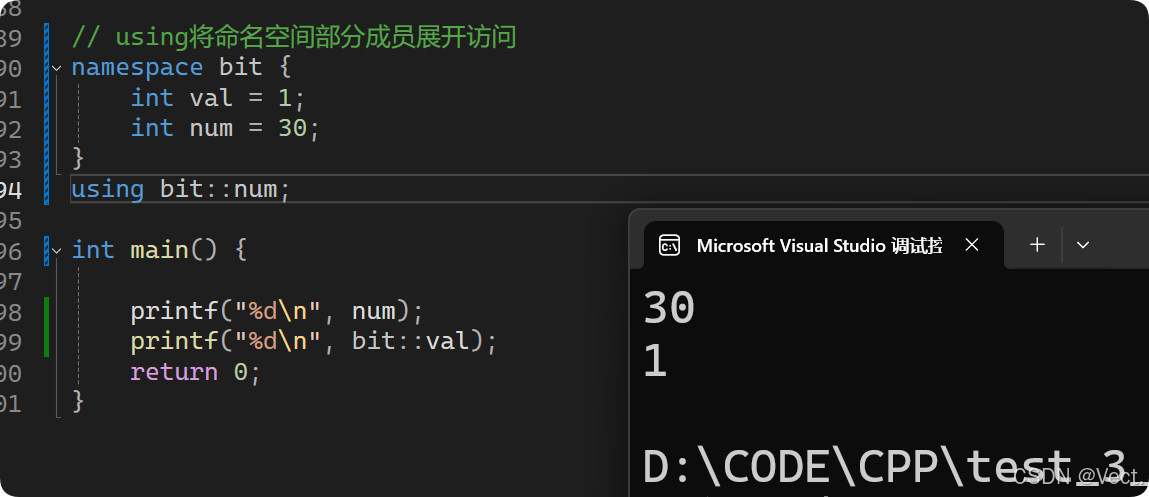
// using将命名空间部分成员展开访问
namespace bit {
int val = 1;
int num = 30;
}
using bit::num;
int main() {
printf("%d\n", num);
printf("%d\n", bit::val);
return 0;
}
输出结果:
// 展开命名空间全部成员
namespace bit {
int val = 1;
int num = 30;
}
using namespace bit;
int main() {
printf("%d\n", num);
printf("%d\n", val);
return 0;
}
输出结果: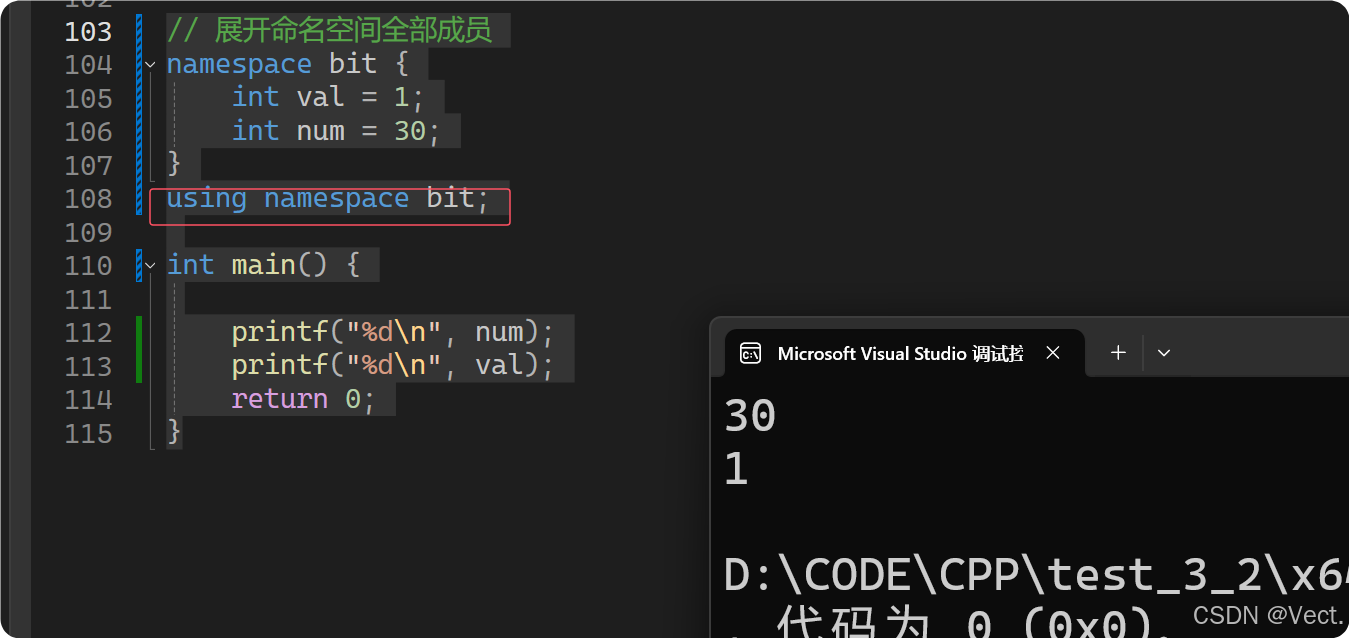
总结一下,现在的访问顺序:
- 当前局部域 // 自家菜地
- 全局域 // 野地
- 命名空间展开域 // 别人菜地但公告允许他人采摘了
二、CPP的输入与输出
- iostream是InputOutputStream的缩写,是标准的输入、输出流库,定义了标准的输入、输出对象
- std::cin 是istream类的对象,它主要面向窄字符(narrow characters)的标准输入流
- std::cout 是ostream类的对象,它主要面向窄字符的标准输出流
- std::endl 是一个函数,流插入输出时,相当于插入⼀个换行字符加刷新缓冲区
- <<是流输出符,>>是流提取符
- 使用CPP输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动动指定格式,CPP的输入输出可以自动识别变量类型
- cout/cin/endl等都属于CPP标准库,CPP标准库都放在⼀个叫std(standard)的命名空间中,所以要通过命名空间的使用方式去用他们
- 一般日常练习中我们可以using namespace std,但实际项目开发中不建议
第一个CPP程序:
// 第一个CPP程序
#include <iostream> // io流
using namespace std;// 展开std标准库
int main() {
cout << "HELLO,CS!" << endl; // << 输出符 可自动匹配类型
return 0;
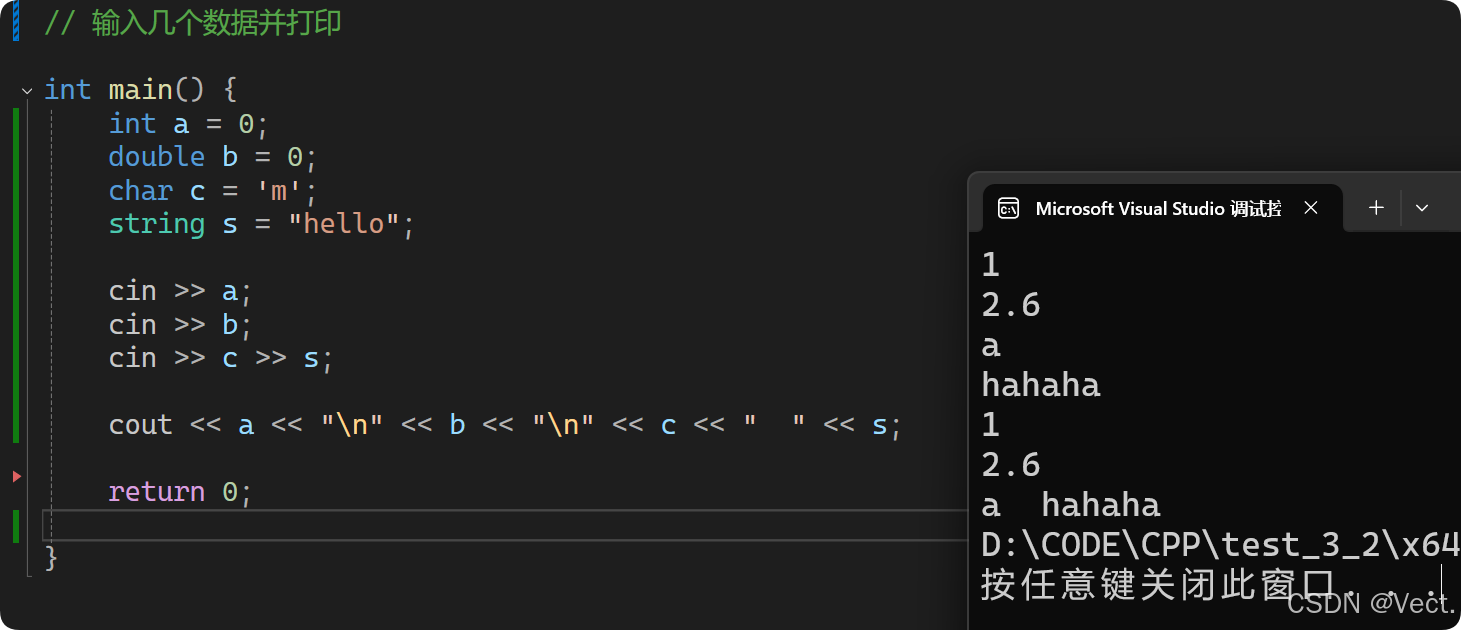
}// 输入几个数据并打印
int main() {
int a = 0;
double b = 0;
char c = 'm';
string s = "hello";
// 可以自动识别类型
cin >> a;
cin >> b;
cin >> c >> s;
cout << a << "\n" << b << "\n" << c << " " << s;
return 0;
}运行结果:
三、缺省参数(默认参数)
1.定义
在函数参数设计中,给形参赋一个值,这个值就称为缺省参数(默认参数),在函数调用时,如果实参不传参数,则使用形参的默认参数
例如:
// 缺省参数
void fuc(int a = 1) {
cout << a << endl;
}
int main() {
fuc(); // 实参未传递实际的值 缺省参数 默认a == 1
fuc(9);// 实参传递实际的值9 非缺省参数 a == 9
return 0;
}输出结果:

2.使用规则
- 缺省参数分为全缺省和半缺省参数,全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值,半缺省参数必须从右往左依次连续缺省,不能间隔跳跃给缺省值
- 带缺省参数的函数调用,必须从左到右依次给实参,不能跳跃给实参
- 函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值
例如:
// 全缺省
void display1(int x = 9, string msg = "Hello", double ratio = 1.5) {
cout << "x=" << x
<< ", msg=" << msg
<< ", ratio=" << ratio << endl;
}
// 半缺省 定义缺省参数 从右往左定义 不可以跳跃
void display2(int x, string msg, double ratio = 1.5) {
cout << "x=" << x
<< ", msg=" << msg
<< ", ratio=" << ratio << endl;
}
int main() {
// 传缺省参数 从左往右
display1();
display1(99);
display1(99,"cs");
display1(99,"cs",8.9);
display2(1,"hahahaha");
display2(1,"hahahaha",8.2);
return 0;
}输出结果: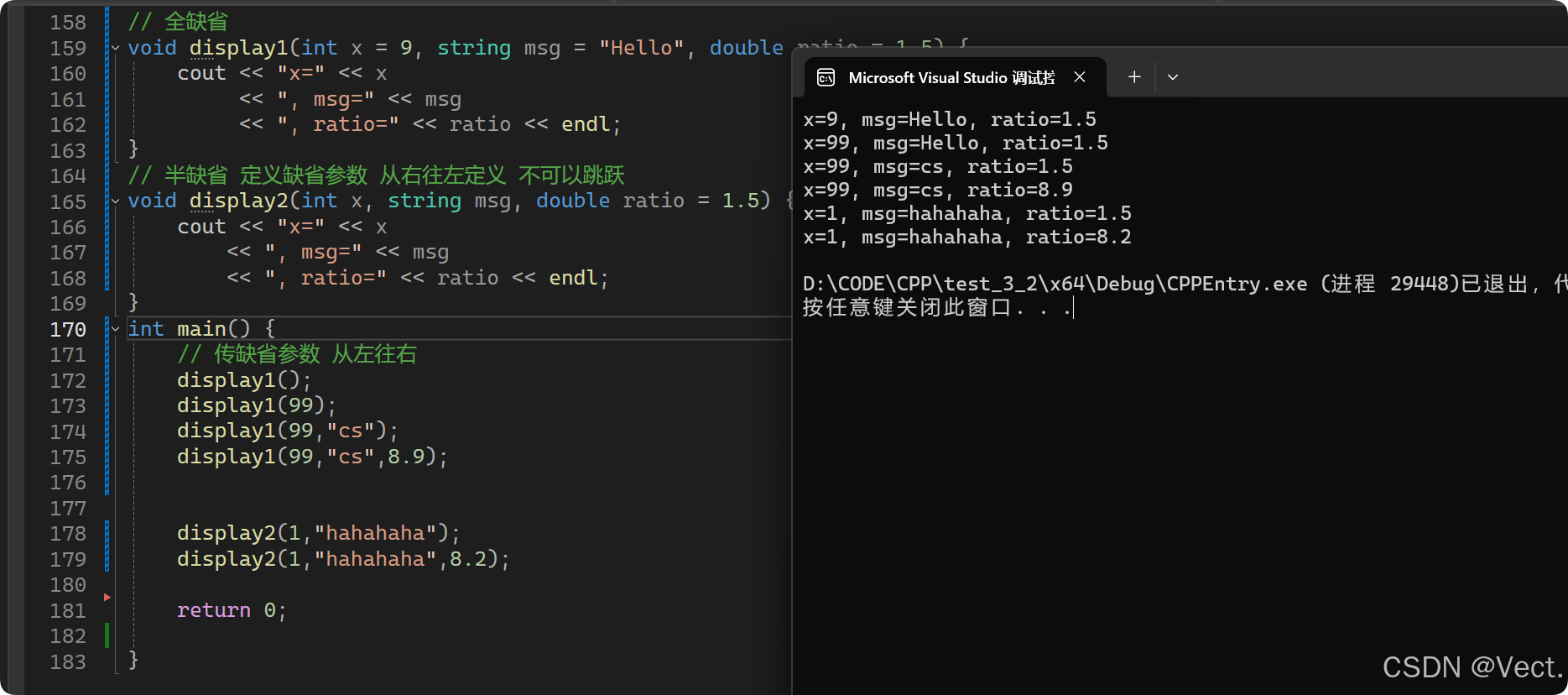
函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省值:
// 头文件声明
void init(int timeout = 1000);
// 源文件定义(错误示例)
// void init(int timeout = 1000) { ... }
// 缺省参数必须在函数声明时给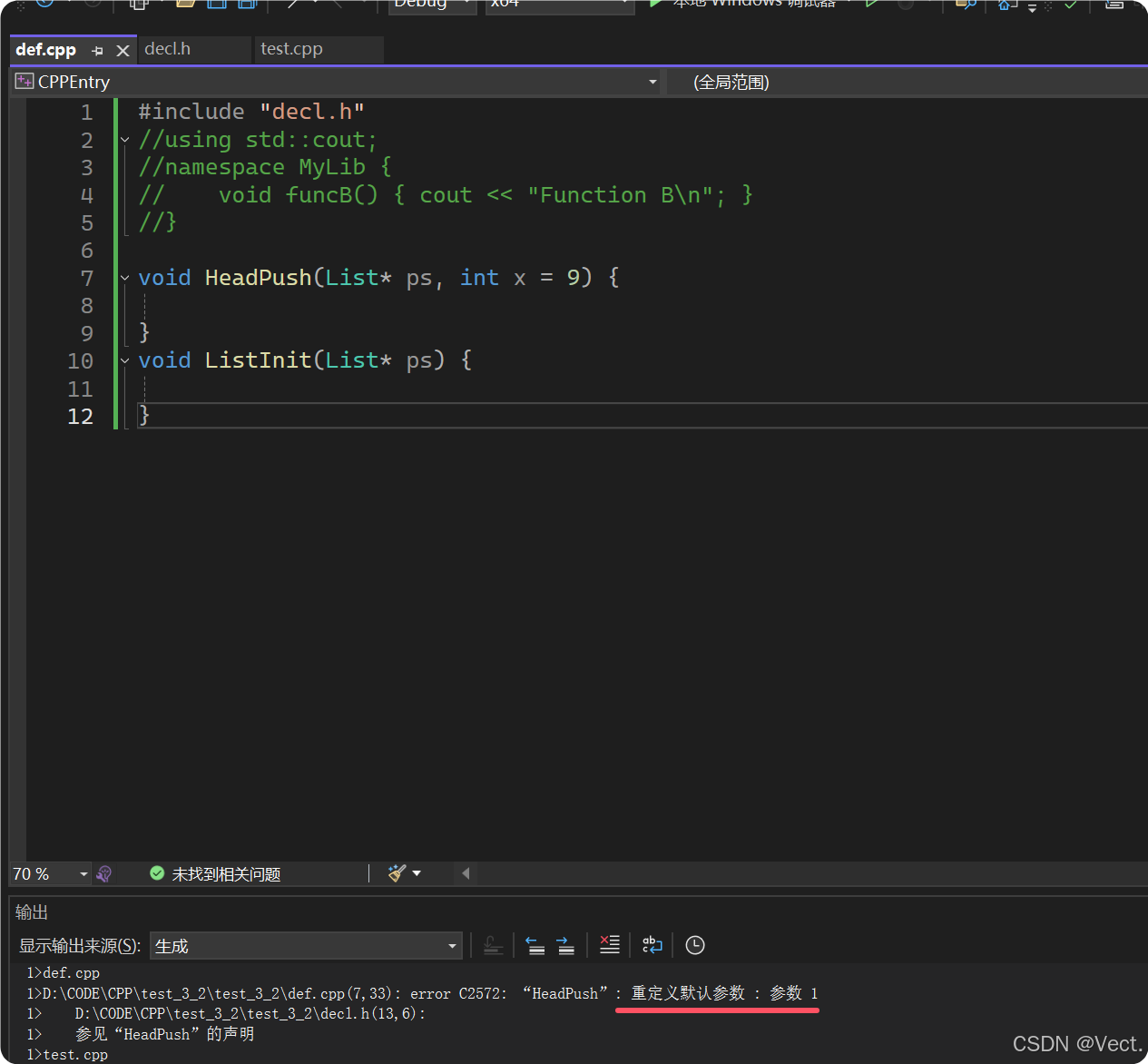
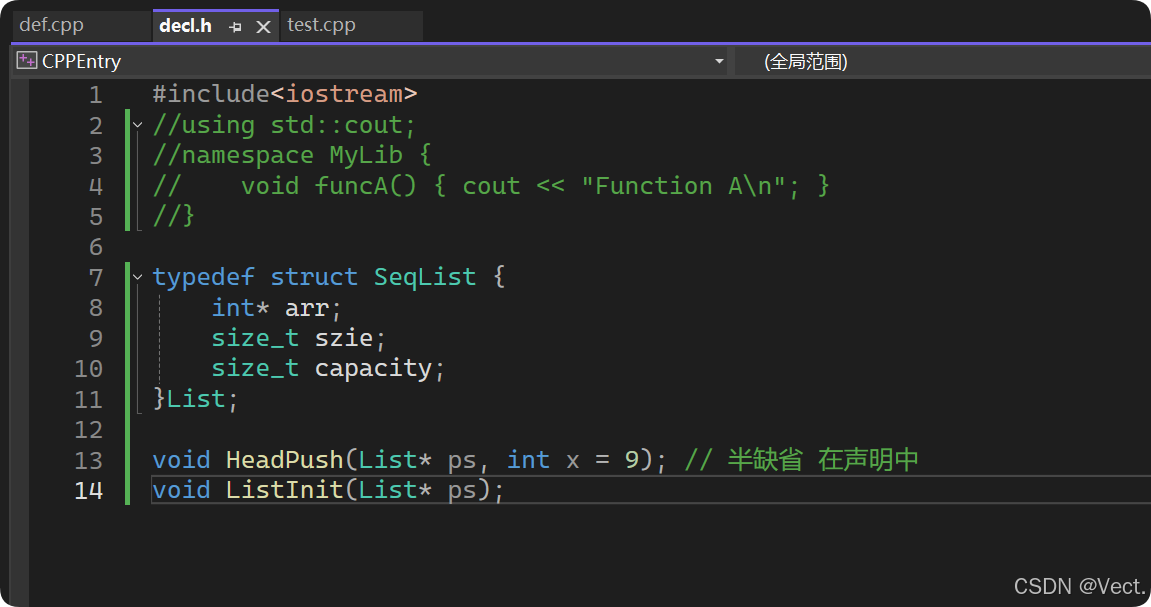 报错了
报错了
将定义中的缺省参数删除:
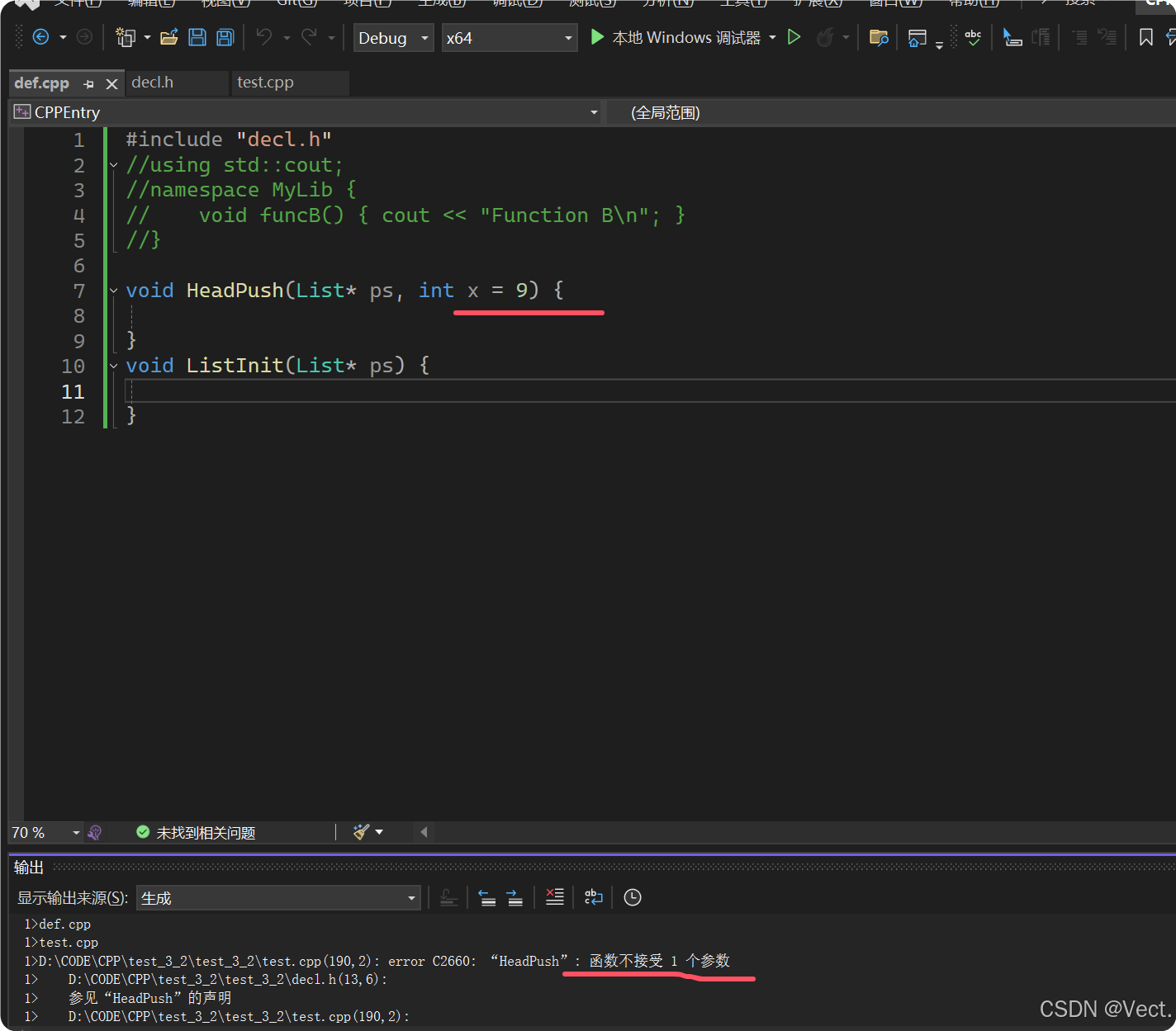
函数定义不接受缺省参数
将定义中的缺省参数删除后:
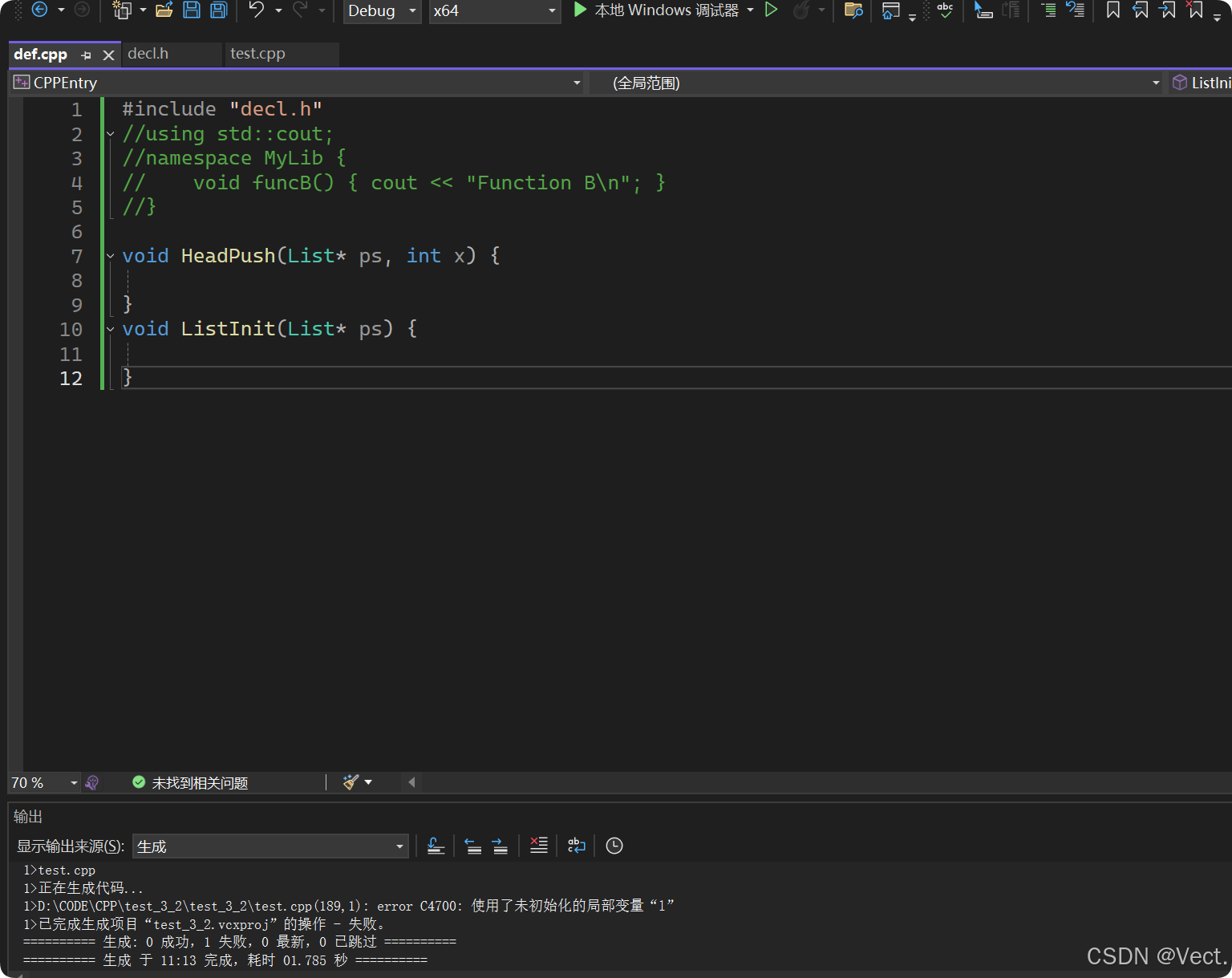
没有重定义缺省参数的错误了,我在主函数中没有初始化变量,这里忽略,只是演示缺省参数在函数定义中不能用,只能在函数声明中使用缺省参数
四、函数重载
函数重载:在CPP中,支持函数定义重名,但是要保证形参的类型、顺序或者个数不同
- 函数形参的名字不能作为判定条件
- 函数的返回值不能作为判定条件
代码示例:
#include <iostream>
using namespace std;
// 函数重载:在CPP中,支持函数定义重名,但是要保证形参的类型、顺序或者个数不同
// 函数形参的名字不能作为判定条件
// 函数的返回值不能作为判定条件,调用时编译器也无法识别到底是哪个函数
// 类型不同
int Add(int a, int b) {
return a + b;
cout << "Add(int a, int b)" << endl;
}
double Add(double a, double b) {
cout << "Add(double a, double b)" << endl;
return a + b;
}
// 顺序不同
void fuc(int x, double y) {
cout << "fuc(int x, double y)" << endl;
}
void fuc(double y, int x) {
cout << "fuc(double y, int x)" << endl;
}
// 个数不同
void Print(char c, int x) {
cout << "Print(char c, int x)" << endl;
}
void Print(char c) {
cout << "Print(char c)" << endl;
}
// 是函数重载,但是编译器不知道匹配谁 存在歧义
void f() {
cout << "f()" << endl;
}
void f(int a = 2) {
cout << "f(int a)" << endl;
}
int main() {
Add(6, 7);
Add(1.3, 8.1);
fuc(7, 8.6);
fuc(8.6, 7);
Print('a',8);
Print('a');
f();
f(1);
return 0;
}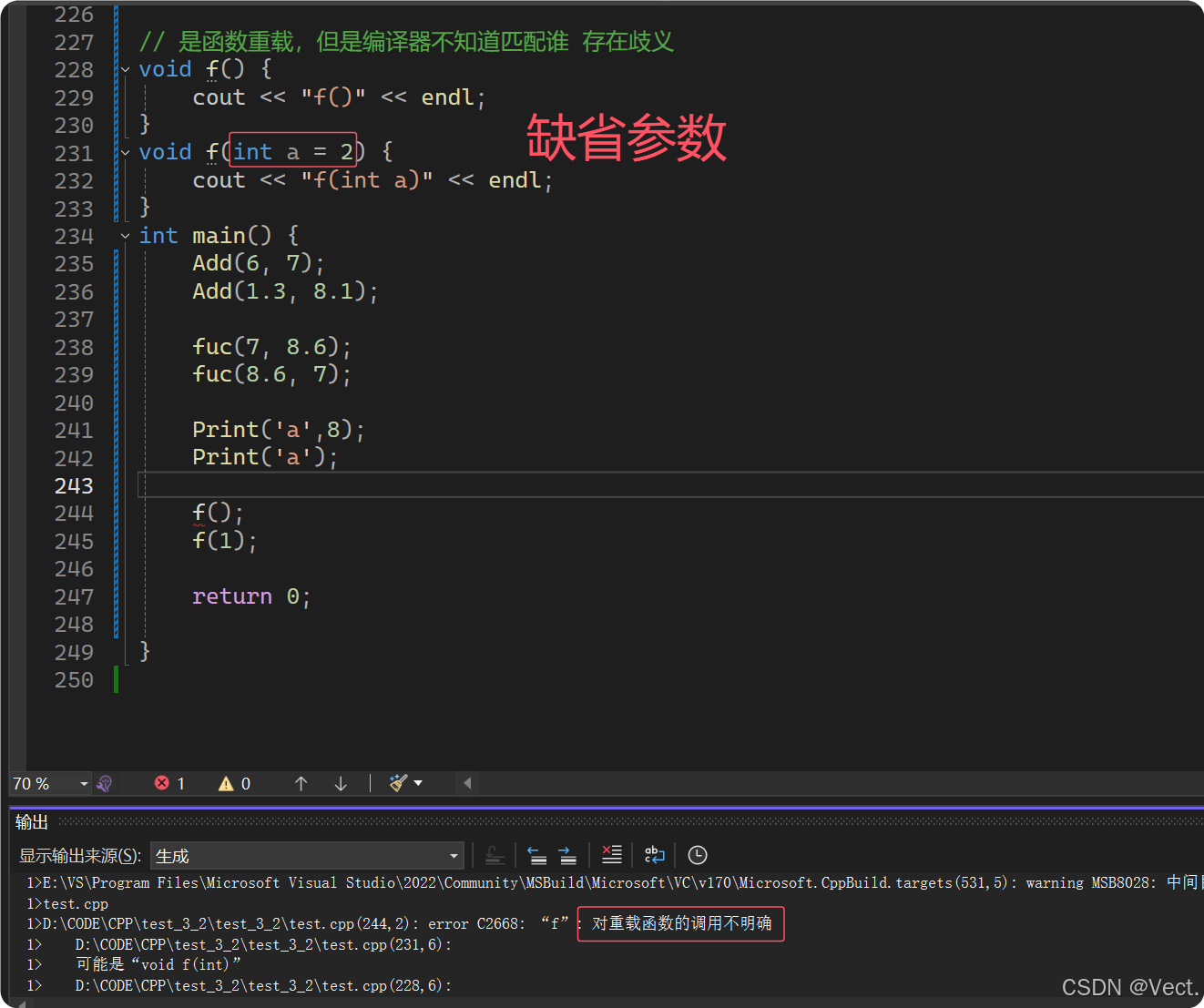
为什么C不支持函数重载而CPP支持?
CPP编译链接时会对函数名进行编码,将参数类型信息融入最终符号名,会将函数改名修饰
C语言编译链接时不会将函数改名修饰
五、引用&
1.定义
为了简化指针的操作,cpp引入引用(&)
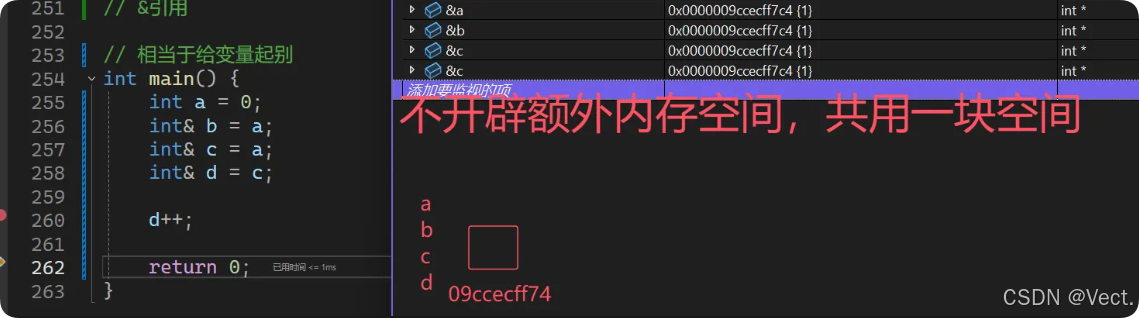
引用是给变量起一个别名,比如说你自己,有自己的大名,小名,还有朋友对你的称呼,每个名字都代表你,因此,引用在语法上不开辟新的内存空间
引用有如下规则:
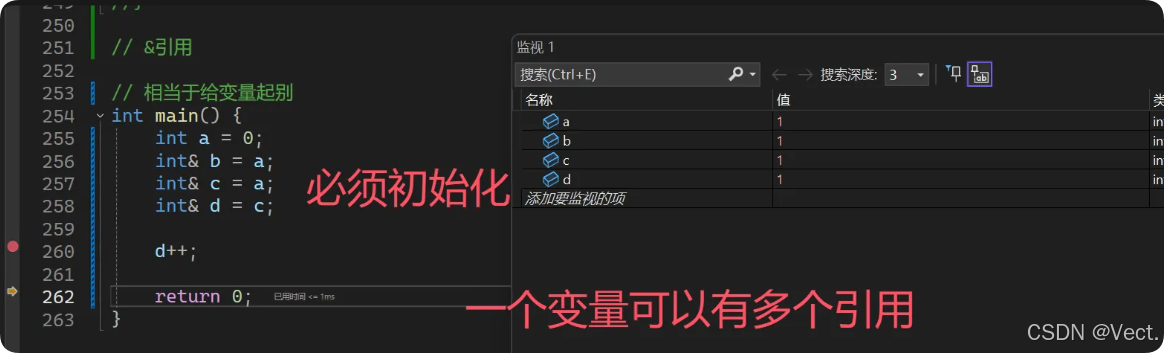
- 引用在定义时必须初始化
- 一个变量可以有多个引用
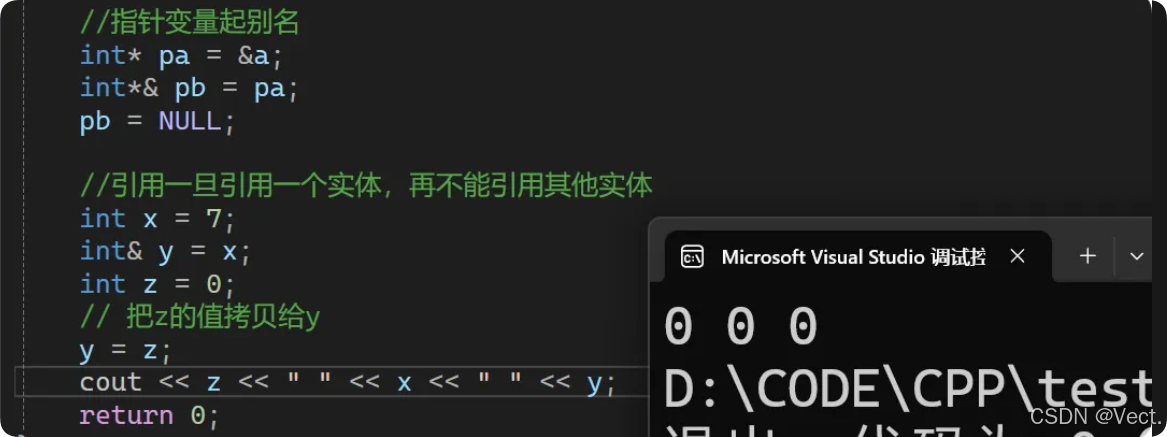
- 引用一旦引用一个实体,再不能引用其他实体
代码示例:
// &引用
// 相当于给变量起别
int main() {
int a = 0;
int& b = a;
int& c = a;
int& d = c;
d++;
cout << "&a" << endl;
cout << "&b" << endl;
cout << "&c" << endl;
cout << "&d" << endl;
return 0;
- 引用一旦引用一个实体,再不能引用其他实体:
int main() {
int a = 0;
int& b = a;
int& c = a;
int& d = c;
d++;
//指针变量起别名
int* pa = &a;
int*& pb = pa;
pb = NULL;
//引用一旦引用一个实体,再不能引用其他实体
int x = 7;
int& y = x;
int z = 0;
// 把z的值拷贝给y
y = z;
cout << z << " " << x << " " << y;
return 0;
}
2.const修饰引用
权限只能平移和缩小,但不能放大!!!!!!!!
类型转换和表达式运算都会产生临时变量 总得有个值来存结果
代码示例:
// const修饰引用
int main() {
const int a = 10;
// 权限放大,不可以 a只读 而b是可修改的
/*int& b = a;*/
// 权限平移
const int& b = a;
int x = 5;
//权限缩小 可以
const int& y = x;
int num = 45;
const int* pnum = #
// 权限平移
const int*& pr = pnum;
// 权限放大 不可以
/*int*& pq = pnum;*/
int* qnum = #
// 权限平移
int*& anum = qnum;
// 权限缩小 但是引用的 int* 与const int* 二者类型不匹配 不可以
/*const int*& bnum = qnum;*/
// CPP允许通过隐式转换创建新指针实现权限缩小
const int* bnum = qnum;
// 类型转换和表达式运算都会产生临时变量 总得有个值来存结果
double val1 = 1.2, val2 = 2.4;
const double& sum = val1 + val2;
int num1 = 5;
float f = num1;
const float& ff = f;
}
 3.指针和引用的关系
3.指针和引用的关系
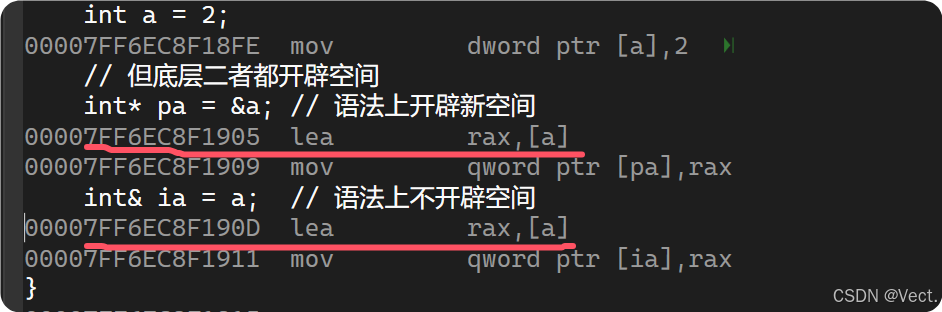
- 在语法上指针需要开辟新的空间,引用给变量起别名无需开辟空间
- 引用必须初始化,指针建议初始化(防止野指针),但不是必须初始化
- 引用在初始化引用一个对象之后,就不能引用其他对象了,指针存储一个变量的地址,可以改变指向,指向其他变量
- 引用可以直接访问引用对象,指针需要解引用才能访问目标对象
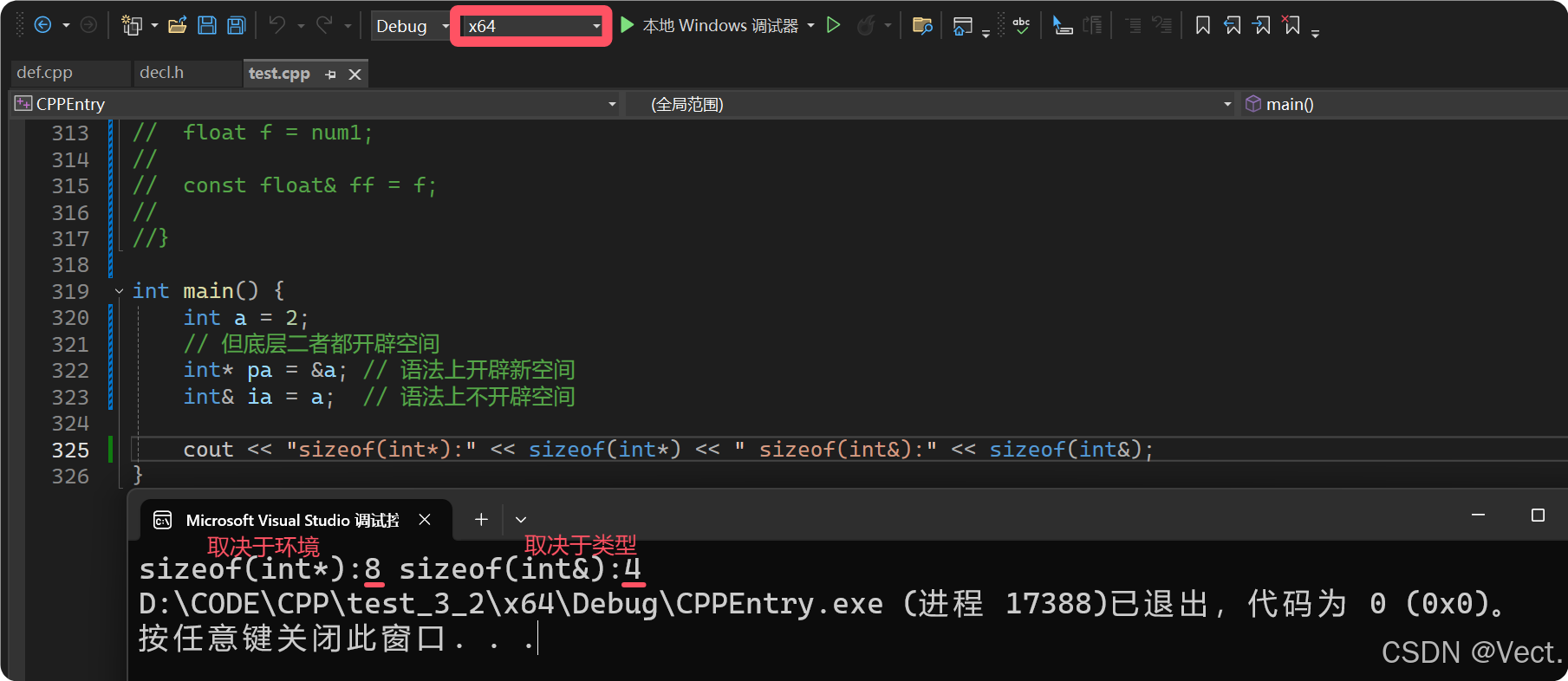
- sizeof中含义不同,引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节,64位下是8字节)
六、内联函数
常规的函数调用:
压栈函数参数->跳转到函数体->执行函数体->返回结果->弹栈。这一系列步骤增加了函数调用的开销,尤其是在小函数中,这种开销可能比函数体本身还要大

所以,在需要频繁调用小函数时,CPP引进了inline,将函数修饰为内联函数,用于提示编译器在函数调用时将函数体直接嵌入到调用点展开,而不是通过常规的函数调用机制调用函数,来提高程序运行效率
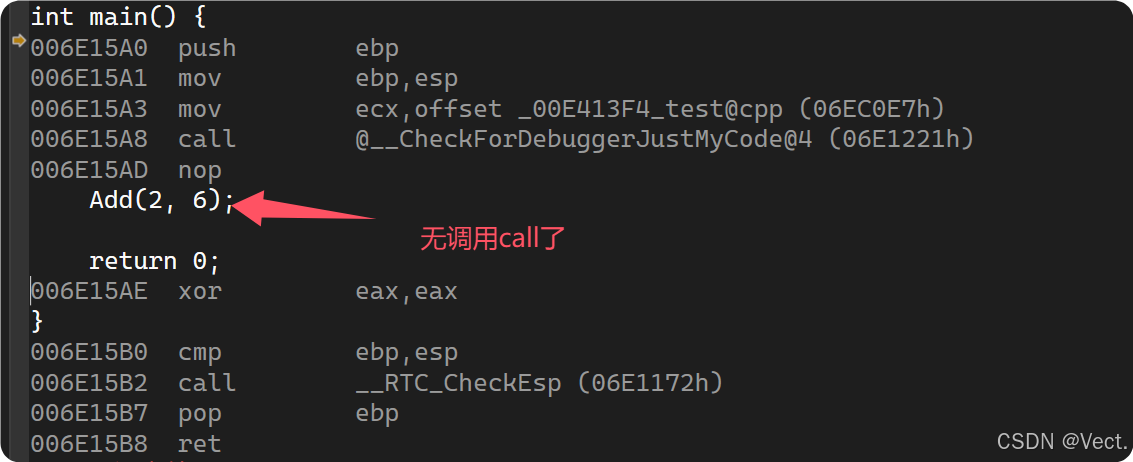
注意:
这里的inlin只是建议,编译器也可以忽略
inline适用于频繁调用的短小函数,对于递归函数,代码相对多⼀些的函数,加上inline也会被编译器忽略
使用内联函数还需要注意两点:
- 内联函数的声明与定义不能多文件分开,建议在同一文件下定义和声明,因为内联函数是将函数体直接展开,并没有保存地址,如果在多文件体系下,链接时找不到函数定义的地址,这个函数就失效了
- vs编译器下,dbug版本默认不展开内联函数,这里需要调整两个地方:
七、 nullptr
NULL实际是⼀个宏
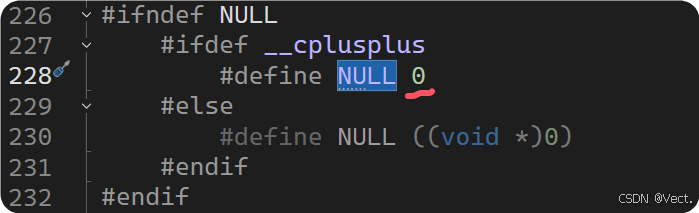
CPP中用关键字nullptr代表空指针
完结撒花~
看到这里,求一个点赞支持~
希望这篇文章对大家CPP过渡有所帮助,如有错误,欢迎评论区指正




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











