




标准化和归一化的区别
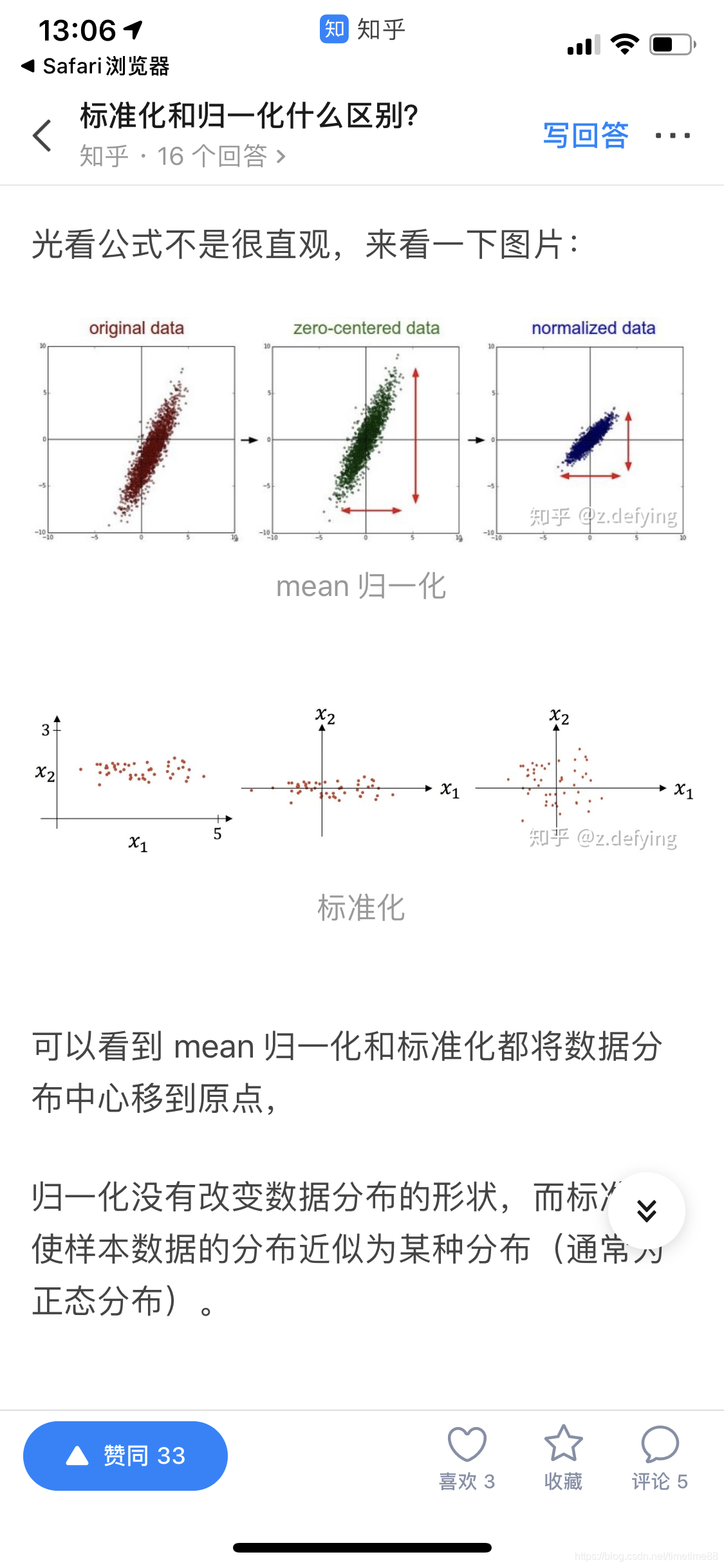
标准化和归一化的区别
最新推荐文章于 2024-01-13 17:04:09 发布
 博客主要探讨了标准化和归一化的区别,这两者在信息技术领域的数据处理中较为重要,了解它们的差异有助于更合理地进行数据操作。
博客主要探讨了标准化和归一化的区别,这两者在信息技术领域的数据处理中较为重要,了解它们的差异有助于更合理地进行数据操作。
博客主要探讨了标准化和归一化的区别,这两者在信息技术领域的数据处理中较为重要,了解它们的差异有助于更合理地进行数据操作。
博客主要探讨了标准化和归一化的区别,这两者在信息技术领域的数据处理中较为重要,了解它们的差异有助于更合理地进行数据操作。
标准化和归一化的区别
 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























