



 Nova是OpenStack中的计算服务控制器,管理虚拟机实例的生命周期,与Hypervisors交互。它包括Nova-api、Nova-compute等多个组件,通过消息队列和数据库进行通信。Nova-scheduler负责实例调度,Nova-compute执行实例操作,Nova-network管理网络,Nova-volume管理卷。启动实例涉及多个组件协作,搭建过程包括配置数据库、消息队列、认证等。
Nova是OpenStack中的计算服务控制器,管理虚拟机实例的生命周期,与Hypervisors交互。它包括Nova-api、Nova-compute等多个组件,通过消息队列和数据库进行通信。Nova-scheduler负责实例调度,Nova-compute执行实例操作,Nova-network管理网络,Nova-volume管理卷。启动实例涉及多个组件协作,搭建过程包括配置数据库、消息队列、认证等。
- 项目介绍Nova是OpenStack中的计算组织控制器,用于为单个用户或使用群组管理虚拟机实例的整个生命周期, 负责管理所有的资源、网络、认证以及可扩展性。OpenStack Compute 没有包含任何的虚拟化软件,相反它定义和运行在主机操作系统上的虚拟化机制(Hypervisors)交互的驱动程序(默认使用KVM),并通过基于Web的程序应用接口(API)来提供功能的使用。
- 服务组件Nova-api 对外提供一个与实例交互的接口,也是外部可用于管理实例的唯一组件,用来引发多数业务流程的活动(如运行一个实例)。API端点是一个基础的HTTP网页服务,通过使用多种API接口(Amazon,Rackspace和相关的模型)来提供认证,授权和基础命令和控制功能。Nova compute 是一个非常重要的守护进程,负责创建和终止虚拟机实例,即管理着虚拟机实例的生命周期。它接受来自消息队列的动作然后执行一系列的系统操作,如启动一个KVM实例,并且更新数据库的状态。可以通过使用API的方式把命令分发到Compute控制器,进行以下的操作: 实例生命周期的管理:运行、结束、重启、销毁实例 卷的管理:通过卷控制器(nova-volume),管理基于LVM的实例卷 授权管理:提供认证和授权服务 对象存储:组件选择性提供存储服务Nova-schedule :接受一个消息队列的虚拟实例请求,通过恰当的调度算法决定在哪台主机上运行这个请求,即从可用资源池中获得一个计算服务,起到调度器的作用。最简单的算法就是随机选择一个。Nova-novncproxy NoVNC代理服务Nova-consoleauth 虚拟机开机日志服务、VNC及日志安全认证服务Nova-xvpvncproxy xvpvnc代理服务 Nova-network(高版本已被neutron取代)接受来自消息队列的任务,对网络执行相应的操作。特定的任务有分配固定IP,为项目配置VLAN,为计算节点配置网络等Nova-volume(高版本已被cinder取代) 用来管理基于LVM的实例卷,有新建卷,删除卷,为实例附加卷,为实例分离卷等相关功能。卷为实例提供一个持久化存储,由于根分区是非持久化的,当实例终止时对它所做的任何改变都会消失。当一个卷从实例分离或者实例终止时,这个卷保留着存储在其中的数据,把这个卷重新加载到相同实例或者附加到不同实例时,这些数据依然能够被访问。Nova-conductor 介于nova-compute和database之间,避免compute直接访问数据库。message queue:消息队列,使用AMQP(Advanced Message Queue Protocol)为各个模块之间的通信建立通道,起到一个集线器的作用,这里是RabbitMQ。Nova通过异步调用请求响应,在响应被接受的时候会触发回调。因为使用了异步通信,不会有用户长时间卡在等待状态,这个是非常有必要的,因为许多API调用预期的行为都很耗时,比如加载一个实例或者是上传一个镜像。一个典型的消息传递事件从API服务器接受来自用户的请求开始。这个API服务器授权这个用户,保证用户是被允许发起相关的命令。在请求中所涉及到的对象的有效性被评估,如果评估有效,将传递给相关的工作处理器。这个请求首先会被发送到消息队列中。工作处理器在它们各自角色或者主机名的基础上监听这个队列。当监听到产生了工作请求,工作处理器接收这个任务并开始执行。完成之后,响应会分发到队列中。队列会被API服务器接收和转述到发起请求的用户。在整个过程中数据库实体会根据需求被查询,增加或者消除。database:存储云基础设施构建时和运行时状态,包括可用的实例类型,正在使用的实例类型,可用的网络和项目。
- 计算服务的原理
它虽然比较复杂,但是信息量不是很大,可以将上图总结为以下三点:
*终端用户 (开发/运维人员和其他openstack组件)与nova-api进行交互
*openstack nova守护进程之间通信通过消息队列(动作)和数据库(信息)交互
*openstack glance是一个完全和openstack nova不一样的架构,它们之间通过glance api交互
总的来说,nova的各个组件是以数据库和队列为中心进行通信的,下面对其中的几个组件做一个简单的介绍:
Queue,也就是消息队列,它就像是网络上的一个hub,nova各个组件之间的通信几乎都是靠它进行的,当前的Queue是用RabbitMQ实现的,它和database一起为各个守护进程之间传递消息。
database存储云基础架构中的绝大多数状态。这包括了可用的实例类型,在用的实例,可用的网络和项目。当前广泛使用的数据库是sqlite3(仅适合测试和开发工作)、MySQL和PostgreSQL。
nova-compute负责决定创造虚拟机和撤销虚拟机,通过运行一系列系统命令(例如发起一个KVM实例,)并把这些状态更新到nova-database中去,其过程相当复杂,但是基本原理很简单。
nova-schedule负责从queue里取得虚拟机请求并决定把虚拟机分配到哪个服务器上去。schedule的算法可以自己定义(也就是实现了一个可插入式的结构。),目前有Simple (最少加载主机),chancd(随机主机分配) ,zone(可用区域内的随机节点)等算法。
nova-volume负责记录每一个计算实例,相当于一个计算请求吧,并负责创建,分配或撤销持久层容器(Amazon的,iSCSI,AoE等等)给这些compute instances。
nova -netwok负责处理队列里的网络任务。
nova-api守护进程是OpenStack Compute的中心。它为所有API查询提供一个入口,并且同时支持OpenStack API 和 Amazon EC2 API。
为了看看nova是如何工作的,我们以启动一个实例为例来进行说明,因为启动一个新的instance涉及到很多openstack nova里面的组件共同协作。
因为创建实例设计的组件较多,此处先解决nova内部的流程(更为详细的见后面):
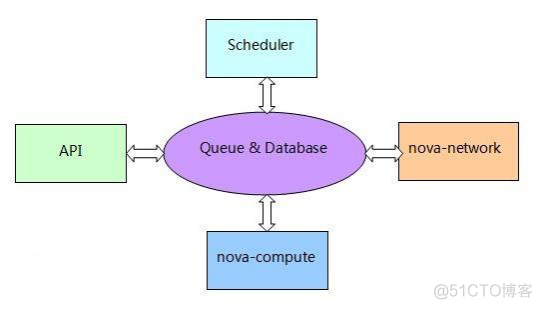
其中:
API:处理客户端的请求,并且转发到 Queue和Database中。
Scheduler:选择一个host去执行命令
nova-compute:启动和停止实例,附加和删除卷等操作
nova-network:管理网络资源,分配固定IP。
接下来就是真正的过程了,先从API开始:
API
例如我们输入一个命令:euca-run-instances-k test -t m1.tiny ami-tiny 它会执行以下操作:
查看这种类型的instance是否达到最大值
给scheduler发送一个消息(实际上是发送到Queue中)去运行这个实例。
Schedule
调度器接收到了消息队列Queue中API发来的消息,然后根据事先设定好的调度规则,选择好一个host,之后,这个instance会在这个host上创建。
Compute
真正去创建一个instance的操作是由Compute完成的,compute与glance-api交互,以及其他的一些操作之后创建出实例。
- 计算服务的搭建先配置控制节点(Controller Node),进行以下操作。
- 首先配置计算服务所需要的数据库首先在数据库中创建名为nova的数据库:
然后授权nova用户对nova库拥有完全权限:

- 创建keystone认证加载admin的环境变量,source admin-openrc.sh创建keystone认证用户nova、nova服务实体,endpoint

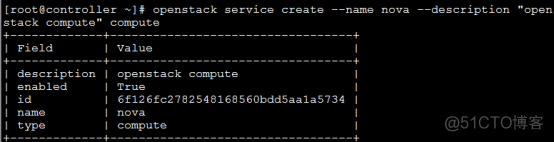
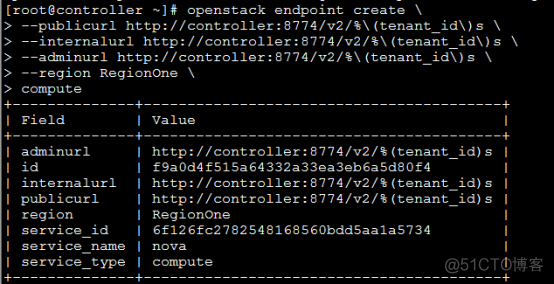
- 安装计算服务软件包
- 修改nova的配置文件/etc/nova/nova.conf
a、首先连接数据库:

b、配置消息队列

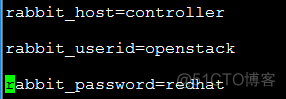
- 创建keystone认证:

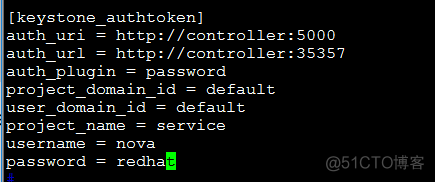
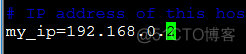
d、指定本机的管理IP:
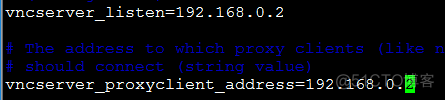
e、配置VNC proxy
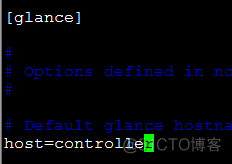
f、配置glance服务器
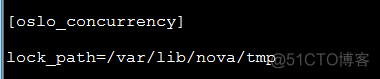
g、配置oslo并发的锁目录
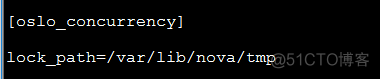
填充nova数据库:

启动服务并开机自启:


到此,控制节点的计算服务配置完毕。
接下来配置计算节点(Computer Node),进行以下操作。
- 安装计算节点的软件包
- 修改nova 配置文件/etc/nova/nova.confa、配置消息队列
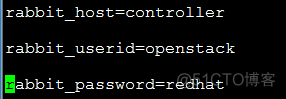
b、配置keystone认证:

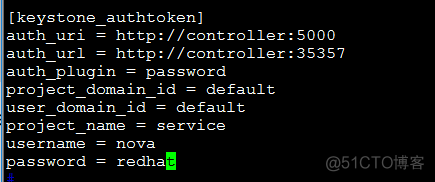
c、指定本机的管理IP:

d、配置远程控制台登录:
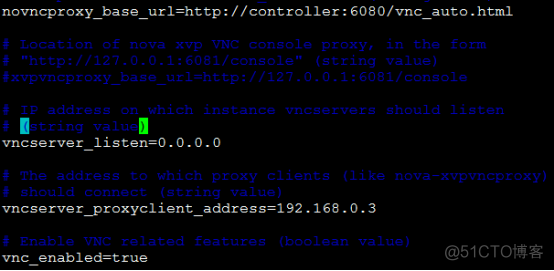
e、配置glance服务器
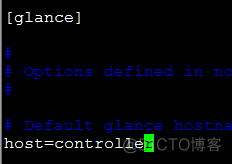
f、配置oslo并发的锁目录
在命令行运行egrep -c '(vmx|svm)' /proc/cpuinfo,如果出现的数字大于等于1,则不需要任何操作,如果出现的是0,那么需要更改libvirt的值为QEMU而不是KVM。

启动服务并开机自启

- 计算服务的验证
在控制节点运行以下命令:
加载admin环境变量 source admin-openrc.sh
用nova来计算一些资源:

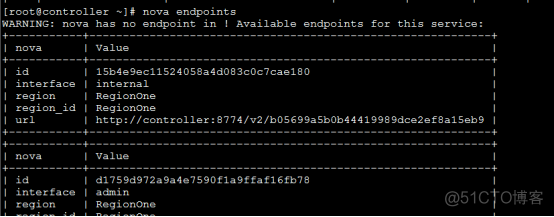

到此nova服务搭建完毕。
Controller节点:
运行nova-api、nova-cert、nova-condutor、nova-scheduler、nova-consoleauth这些小型服务
Compute节点:
运行nova-novncproxy、nova-xvpvncproxy、nova-compute这些小型服务。

Compute manager
Nova-api——> nova-scheduler——> nova-compute——>
或KVM
1、首先nova-api接受来自客户端或者dashboard的请求。接受到请求后先验证请求的合法性。通过验证后,将请求交给nova-scheduler。
2、nova-scheduler负责选择主机。接受到nova-api的请求后,nova-scheduler会查看集群中所有服务正常的计算节点,并在计算节点中选择一个合适的节点启动虚拟机。选择结束后会将请求交给选中的节点的nova-compute服务。
3、nova-compute运行在计算节点上,专门负责创建虚拟机。Nova-compute服务中,compute manager负责接受消息,而真正干活的是compute driver。Openstack的compute driver可以支持很多种hypervisor,比如hyper-V,vmware,XenServer,KVM,Xen等,其中KVM和Xen主要是通过libvirt进行管理。Openstack默认采用libvirt作为底层来管理虚拟机。因此,nova-compute把消息转交给libvirt的时候,nova-compute及开始干活了。接下来就有底层libvirt负责。
4、libvirt、KVM、Xen:首先是libvirt接受消息,在将具体的任务交给KVM和Xen。

















 2127
2127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









