



基于两阶段局部敏感哈希的隐私保护 分布式服务推荐
摘要
随着在各种Web社区中注册的服务数量不断增加,从海量候选服务中找到目标用户真正感兴趣的服务成为一项具有挑战性的任务。在这种情况下,协同过滤(即CF)技术被引入以减轻目标用户在服务选择决策上的负担。然而,现有的基于CF的推荐方法通常假设推荐基础(即历史服务质量数据)是集中的,未考虑数据多源的分布式服务推荐场景。此外,分布式服务推荐需要多个参与方之间的协作,在此过程中用户隐私信息可能暴露。鉴于这些挑战,本文提出了一种基于两阶段局部敏感哈希(LSH)的新型隐私保护分布式服务推荐方法,命名为SerRectwo-LSH。具体而言,在SerRectwo-LSH中,我们首先通过一个隐私保护的两阶段LSH过程寻找目标用户的“相似朋友”;随后,确定这些“相似朋友”所偏好的服务,并将其推荐给目标用户。最后,通过对真实分布式服务质量数据集WS‐DREAM进行的一系列实验,验证了我们的方案在保证隐私保护的同时,在推荐准确性和效率方面的可行性。
关键词
分布式服务推荐 Collaborative 过滤 隐私保护 Efficiency Two-Phase 局部敏感哈希
1 引言
随着各种Web社区(例如亚马逊和IBM)中服务数量和类别的不断增加,从海量候选服务[1–3]中找到目标用户真正感兴趣的服务正变得越来越具有挑战性。在这种情况下,各种轻量级服务推荐技术被引入,以减轻目标用户在服务选择决策上的负担,例如广泛采用的协同过滤(即CF)。通常,通过协同过滤(例如基于用户的协同过滤1),推荐系统可以根据历史服务质量数据找到目标用户的“相似朋友”,然后基于这些“相似朋友”[4]为目标用户提供服务推荐。
然而,现有的基于协同过滤的服务推荐方法存在两个缺点。首先,现有方法通常假设推荐依据(即历史服务质量数据)是集中的,而未考虑服务质量数据来源多样或分布式的推荐场景。此外,在分布式环境中,服务推荐需要多个参与方或平台之间进行密切协作;而在这种跨平台协作过程中,用户隐私可能会暴露。
针对这两个挑战,本文提出了一种基于两阶段局部敏感哈希(LSH)的新型分布式服务推荐方法[5],命名为SerRectwo-LSH,以实现隐私保护的分布式服务推荐。
总之,我们论文的贡献有三个方面。
(1) 据我们所知,现有研究工作很少考虑历史服务质量数据为多源的分布式服务推荐问题。我们对这一分布式服务推荐问题进行了形式化定义,并阐明了其重要意义。(2) 我们将两阶段局部敏感哈希过程引入分布式服务推荐中,以保护用户的关键隐私信息,例如用户观测到的服务质量数据、用户调用过的服务集。(3) 我们在分布式服务质量数据集WS‐DREAM上进行了大量实验,以验证我们方法的可行性与优势。实验结果表明,我们提出的SerRectwo-LSH方法在保证隐私保护的同时,在推荐准确性与效率方面优于其他最先进的方法。
本文的其余部分结构如下。相关工作在第2节中介绍。在第3节中,我们阐述了本文的研究动机。在第4节中,我们提出的SerRectwo-LSH服务推荐方法被详细地介绍。在第5节中,我们进行了一系列实验以验证所提方法的可行性,最后在第6节中,我们对全文进行了总结,并指出了未来的研究方向。
2 相关工作
作为一种经典的信息检索方法,协同过滤(即CF)已成为各种推荐系统中最有 效的技术之一。具体而言,文献[4]和[6],分别提出了基于用户的协同过滤和 基于项目的协同过滤,以实现精确的服务推荐。为了整合基于用户和基于项目 的协同过滤的优势,文献[7]引入了混合协同过滤,其实验结果表明其具有更好 的推荐性能。由于服务质量高度依赖于服务调用上下文(例如服务调用时间、 用户位置、服务位置),文献[8]和[9],分别提出了时间感知协同过滤和位置 感知协同过滤。然而,上述方法仅利用客观的用户‐服务质量数据进行服务推荐, 未考虑目标用户的主观偏好,而主观偏好在目标用户的服务选择决策中也起着 重要作用。针对这一不足,文献[10]提出了一种用户偏好感知协同过滤推荐方 法,以获得更合理的推荐结果。然而,当历史服务质量数据非常稀疏时,上述 方法可能无法产生任何推荐结果。鉴于这一局限性,文献[11]和[12],分别提出 了流行度感知协同过滤和基于信任传播的协同过滤,以应对稀疏数据环境下的 冷启动推荐问题。
然而,上述推荐方法均假设推荐基础(即历史服务质量数据)是集中的, 未考虑分布式服务推荐场景以及由此引发的隐私保护问题。为了保护用户隐私, 文献[13]中提出了一种简单的方法,建议每个用户仅发布其观察到的服务质量 数据的一小部分。然而,发布的少量数据仍可能泄露用户的部分隐私信息。针 对这一缺点,文献[14]采用了数据混淆技术,将真实服务质量数据转换为混淆 的数据,从而隐藏并保护真实服务质量数据。但是,由于用于服务推荐的数据 已被混淆,推荐准确性也随之下降。考虑到这一缺陷,文献[15]采用了一种 “分‐合”机制,即将每条用户‐服务质量数据首先划分为多个包含较少用户隐私 的质量片段,然后利用这些质量片段进行后续的服务推荐。然而,该方法存在 两个缺点:第一,由于[15]中采用的“分‐合”操作通常耗时较长,导致推荐 效率显著降低;此外,该方法无法保护某些私有用户信息,例如两个用户共同 调用的服务交集。
针对上述挑战,本文提出了一种基于两阶段LSH的新型服务推荐方法,即 SerRectwo-LSH,以解决分布式环境中的隐私保护服务推荐问题。接下来,通过 一个直观的示例进一步阐述本文的研究动机。
3 研究动机
在本节中,图1中的示例用于阐明本文的研究动机。如图1所示,utarget(在亚马逊平台中)表示推荐系统希望为其推荐服务的目标用户;u1是IBM平台中的一个用户;{ws1,…, wsn}是候选Web服务,每个服务都可能被任意平台中的任何用户调用。如果用户u在平台pf (即亚马逊或IBM)中曾经调用过服务ws,则该用户ws观察到的服务质量数据由u记录在pf中。
接下来,为了找到用户utarget的相似朋友,我们需要首先根据传统的基于用户的协同过滤方法,通过公式(1)计算utarget与u1,之间的相似度,即Sim(utarget, u1)。其中,PCC(utarget, u1)(2[0, 1])表示根据utarget和u1,观察到的历史服务质量数据计算得到的utarget与u1,之间的皮尔逊相关系数[16];coef(utarget,u1)表示PCC(utarget, u1)的可信度,可通过公式(2)获得,其中Itarget和I1分别表示用户utarget和u1,调用的服务集合。
$$
Sim(utarget, u1) = coef(utarget, u1) \times PCC(utarget, u1) \quad (1)
$$
$$
coef(utarget, u1) = \frac{|Itarget \cap I1|}{|Itarget \cup I1|} \quad (2)
$$
根据上述分析,我们可以得出结论:为了计算公式(1)中的用户相似度Sim(utarget, u1),亚马逊与IBM之间的协作是必要的。然而,这种跨平台协作过程常常面临巨大挑战。具体而言,由于隐私问题,IBM通常不愿意向亚马逊公开其关于u1的数据(例如u1,曾经调用的服务集合以及u1观测到的服务质量数据),这严重阻碍了亚马逊与IBM之间的协作,使得公式(1)中Sim(utarget, u1)的计算变得不可行。
鉴于这一挑战,我们将局部敏感哈希(LSH)技术引入跨平台服务推荐,提出了一种新颖的两阶段基于LSH的推荐方法,即SerRectwo-LSH ,以解决隐私保护的分布式服务推荐问题。

4 基于两阶段LSH的服务推荐方法:SerRectwo-LSH
在本节中,我们提出了服务推荐方法SerRectwo-LSH ,该方法包含图2中的四个步骤。其中,{u1,…, um}为用户集合,utarget表示目标用户,{ws1,…, wsn}为候选服务集合,q是Web服务的质量维度(例如,响应时间)。
我们方案的主要思想是:对于每个用户ui(1 ≤ i ≤ m),可在步骤1中基于LSH以保护隐私的方式计算(1)中的PCC(utarget,ui),并在步骤2中基于MinHash[17](一种LSH变体)以保护隐私的方式计算(2)中的coef(utarget, ui);随后,根据上述两个步骤得到的结果,在步骤3中计算(1)中的Sim(utarget, ui),并据此确定utarget的相似朋友;最后,根据步骤3中得出的相似朋友,在步骤4中向utarget提供服务推荐。
接下来,我们将详细介绍这四个步骤。
步骤1:基于LSH计算PCC(utarget, ui)
首先,我们选择一个LSH函数族H(ui) ={h1(ui), …, hr(ui)},为每个用户ui(1 ≤ i ≤ m)构建索引(包含较少的隐私信息)。此处采用的LSH函数取决于所使用的 “距离”类型。由于皮尔逊相关系数(PCC)[16]常被用作各类推荐系统中的距离度量,在此步骤中,我们利用与PCC相对应的LSH函数来构建用户索引。接下来,我们介绍用户索引的具体构建过程。
对于用户ui,其历史服务质量数据可用一个n维向量u i !=(ws1.q, …, wsn.q)表示,其中wsj.q表示服务wsj(1 ≤ j ≤ n)在维度q上的服务质量,若用户ui此前从未调用过服务wsj,则wsj.q = 0。
根据LSH理论[18],,向量u! i的LSH函数,记为h( u! i),如(3)所示。其中,v!是一个n维向量(v1,…, vn),其中vj(1 ≤ j ≤ n)是随机生成的,且vj 2[−1, 1]成立;符号“”表示两个向量之间的点积。LSH背后的原理是: 将向量v!视为一个超平面,如果两个向量u!1和u!2位于v!的同一侧(即u!1v ![0和u!2v![0同时成立,或u!1v! 0和u!2v! 0同时成立),则 u!1和u!2以高概率相似。
$$
h(\vec{u_i}) =
\begin{cases}
1 & \text{if } \vec{u_i} \cdot \vec{v} > 0 \
0 & \text{if } \vec{u_i} \cdot \vec{v} \leq 0
\end{cases}
\quad (3)
$$
因此,通过(3)式中的哈希函数,用户ui被转换为一个二值哈希值,即0或1。
由于LSH本质上是一种基于概率的方法[5],,更多的哈希函数或哈希表可能会带来更高的推荐准确性。因此,为了实现准确的服务推荐,此处引入了多个哈希函数和哈希表。具体而言,我们假定采用了T个哈希表,且每个哈希表对应r个哈希函数。然后,对于每个哈希表,得到一个r维向量H(u! i)=(h1(u! i), …, hr(u! i)),该向量可被视为用户ui在哈希表中的索引。因此,一个平台(例如图 1中的IBM)可以仅向其他平台(例如图1中的亚马逊)发布较短的用户索引,而无需透露其他关键隐私信息,例如用户观测到的服务质量数据;从而保护了用户隐私。
此外,用户索引可以在推荐请求到达之前预先建立,因为用于构建用户索引的历史服务质量数据已经被某个平台记录(例如,在图1中,utarget’和u1’的服务质量数据分别由亚马逊和IBM记录)。因此,推荐效率可以得到显著提升。
此外,对于两个用户u1和u2,,如果它们在任意哈希表中的索引相同(即公式 (4)中的条件成立),则u1和u2会被投影到同一桶中,因而可以被视为具有高概率的相似性[5]。
$$
\exists x, \text{ satisfy } H_x(\vec{u_1}) = H_x(\vec{u_2}) \quad (x \in {1, …, T}) \quad (4)
$$
接下来,我们计算utarget的索引,即H(utar!get),并将其与H(u i !)(1 ≤ i ≤ m)进行比较。如果在任意一个T个哈希表中满足H(utar!get) = H(u i !),则我们可以高概率地认为utarget和ui之间的PCC值,即PCC(utarget, ui) = 1;否则, PCC(utarget, ui) = 0。最后,我们选择那些PCC(utarget, ui) = 1的用户ui,并将它们作为utarget的相似朋友的候选(记录在集合Friend_setPCC中)。
步骤2:基于MinHash计算coef(utarget, ui)
对于任意用户ui(1 ≤ i ≤ m),其曾调用的服务集可表示为一个n维列向量Vi !=(Vi−1,…, Vi−n)T,其中当用户ui之前曾调用过服务wsj时,Vi−j = 1(1 ≤ j ≤ n);否则,Vi−j = 0。因此,我们可以得到公式(5)中的用户‐服务调用矩阵M,其中每个用户对应一列。接下来,在矩阵
$$
M =
\begin{bmatrix}
V_{1-1} & V_{2-1} & \cdots & V_{m-1} \
V_{1-2} & V_{2-2} & \cdots & V_{m-2} \
\vdots & \vdots & \ddots & \vdots \
V_{1-n} & V_{2-n} & \cdots & V_{m-n}
\end{bmatrix}
\quad (5)
$$
M,我们从上到下记录每列中第一个“1”的位置(在(5)中用蓝色圆圈标记)。例如,u1列的位置值为“2”,因为u1从未调用过ws1,但曾调用过ws2;同样, u2列的位置值为“1”,因为u2曾调用过ws1。因此,我们可以得到一个m维行向量R。例如,对于(5)中的示例,R=(2, 1, …, 2)成立。
随后,我们随机交换矩阵M中所有服务的顺序,然后重复上述过程以生成k(k n)个行向量R1,…, Rk。从而得到一个新的k×m矩阵M*(见(6)),其中每一列(r1i, r2i, …, rki)T可被视为一个短用户签名(记为集合Sigi={r1i, r2i, …, rki}),用于描述用户ui的曾调用的服务集。因此,对于一个平台(例如图1中的IBM),它可以仅发布用户ui的短用户签名Sigi,并向其他平台(例如图1中的亚马逊)泄露极少的隐私,而无需透露ui曾调用的Web服务集;从而保护了ui的隐私。
此外,由于用于构建用户签名的曾调用的服务集已经被某个平台记录(以图1为例,utarget’和u1’的曾调用的服务集分别由亚马逊和IBM记录),用户签名Sigi(1 ≤ i ≤ m)可以在推荐请求到达之前离线生成;因此,推荐效率可以显著地提高。
接下来,根据MinHash理论[17],公式(2)可转化为公式(7)。当k n时, | Sigi | | Ii |在(7)中成立。因此,我们可以通过(7)以一种隐私保护且高效的方式计算coef(utarget, ui)。
$$
M^* =
\begin{bmatrix}
R_1 \
R_2 \
\vdots \
R_k
\end{bmatrix} =
\begin{bmatrix}
r_{11} & r_{12} & \cdots & r_{1m} \
r_{21} & r_{22} & \cdots & r_{2m} \
\vdots & \vdots & \ddots & \vdots \
r_{k1} & r_{k2} & \cdots & r_{km}
\end{bmatrix}
\quad (6)
$$
$$
coef(utarget, u1) = \frac{|Itarget \cap I1|}{|Itarget \cup I1|} \approx \frac{|Sigtarget \cap Sig1|}{|Sigtarget \cup Sig1|}
\quad (7)
$$
步骤3:确定utarget的相似朋友
在步骤1和步骤2中,我们已获得用户ui(1 ≤ i ≤ m)的PCC(utarget, ui)和coef(utarget, ui)。然后根据(1),可得到utarget与 ui之间的相似度,即 Sim(utarget, ui)。此处,我们只需计算utarget与Friend_setPCC集合中用户的相似度值(该集合在步骤1中得出),因为根据LSH的性质,Friend_setPCC之外的用户与utarget高度相似的可能性较低。接下来,对每个ui ∈ Friend_setPCC,通过公式(1)计算Sim(utarget, ui);随后,将Sim(utarget, ui)值最高的前3名用户视为utarget的相似朋友,并加入新的集合Friend_setcoef*PCC中。
步骤4:服务推荐
接下来,我们利用目标用户的相似朋友(即在步骤3中获得的Friend_setcoef*PCC中的用户)来进行服务推荐。具体而言,对于每个目标用户utarget从未调用过的服务wsj,我们基于公式(8)预测其在维度q上的质量qtarget-j。其中,qi-j表示服务wsj在维度q上由用户ui所评价的质量,Sim(utarget, ui)表示在步骤3中获得的用户utarget与ui之间的相似度。最后,我们选择具有最优预测质量的服务并推荐给目标用户,从而完成整个服务推荐过程。
$$
q_{target-j} = \frac{\sum_{ui \in Friend_set_{coef
PCC}} Sim(utarget, ui) \times q_{i-j}}{\sum_{ui \in Friend_set_{coef
PCC}} Sim(utarget, ui)}
\quad (8)
$$
5 实验
在本节中,我们进行了一系列实验以验证所提出的SerRectwo-LSH方法的可行性。实验基于一个真实的分布式服务质量(即响应时间和吞吐量)数据集 WS‐DREAM[19],该数据集收集了339个用户(来自不同国家)对5825个 Web服务的真实服务质量评估结果。在实验中,仅考虑服务的一个质量维度,即响应时间,并将每个国家作为一个独立的平台,以模拟分布式服务推荐场景。
具体而言,为了进行服务质量预测和服务推荐,从WS‐DREAM的用户‐服务质量矩阵中移除(100 − p)%的条目(参数p∈(0, 100))。即,我们使用p%已知的服务质量数据来预测其余(100 −p)%的缺失数据,并将预测的服务质量与真实服务质量进行比较,以衡量服务推荐性能。更具体地,分别测试和比较以下两个评价指标(由于LSH的内在特性能够很好地保护用户隐私,本文不再评估所提方案的隐私保护能力)。
(1) 时间开销:生成最终推荐结果所消耗的时间。(2) 平均绝对误差(越小越好):推荐服务的预测服务质量与真实服务质量之间的平均差异。
此外,我们将我们的方案与另外三种先进的推荐方法进行了比较,即 UPCC[20]、PPICF[15]和P‐UIPCC[14]。实验在一台配备2.40 GHz处理器和12.0 GB内存的联想笔记本电脑上进行。该机器运行Windows 10、JAVA 8 和MySQL 5.7。每次实验重复10次,最终采用平均实验结果。
具体而言,实验中测试并比较了以下六个配置文件。其中,m 和 n 分别表示用户数量和Web服务数量;T 和 r分别表示LSH表数量以及每个LSH表中的哈希函数数量(见步骤1);k 表示MinHash函数数量,即公式(6)中行向量的数量;p%表示用户‐服务质量矩阵密度。
Profile 1:四种方法在m和n上的推荐效率比较
本实验中,我们测试并比较了四种方法的推荐效率。实验参数设置如下:m从100变化到300,n=5000,T=10,r=8,p=5。
在图3(a)中,n=5000且m从100变化到300。由图3(a)可以看出,UPCC、PPICF和P-UIPCC方法的时间开销均随着m的增长而增加,这是因为需要遍历所有m个用户以找到目标用户的相似朋友;而我们提出的SerRectwo-LSH方法的时间开销非常小,优于其他三种方法,因为该方法中的大部分任务(例如步骤1中的用户索引构建、步骤2中的用户签名生成)均可离线完成。因此,推荐效率显著提高。
在图3(b)中,m=300且n从1000变化到5000。实验结果也显示出与图3(a)相似的推荐效率变化趋势。随着n的增长,UPCC、PPICF和P-UIPCC方法的时间开销均随之增加,因为这三种方法在用户相似度计算过程中都需要考虑所有n个服务。而我们的SerRectwo-LSH方法在推荐效率方面优于其他三种方法,因为在我们的方法中,用户相似度计算工作是在离线状态下完成的。因此,推荐效率得到了显著地提升。
 . n = 5000)
. n = 5000)
 . m = 300)
. m = 300)
Profile 2:四种方法在m和n上的推荐准确性比较
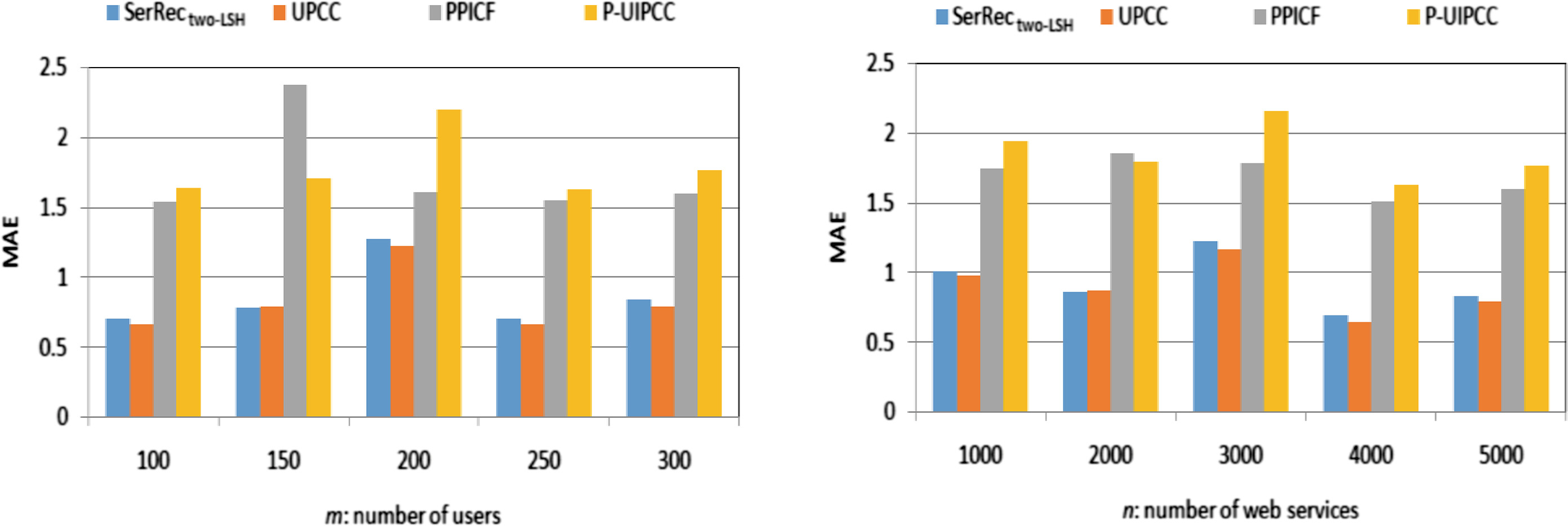
在本配置中,我们测试并比较了四种推荐方法的准确性(即平均绝对误差,越小越好)。具体实验参数设置如下:k=30, T=10, r=8, p=5。实验结果如图4所示。
在图4(a)中,n=5000且m从100变化到300。如图4(a)所示,PPICF和P-UIPCC方法的推荐准确性值均较低(即,平均绝对误差值均较高)。这是因为在这两种方法中,用于进行服务推荐的数据已被混淆以保护用户隐私;因此,推荐准确性有所降低。而由于我们所提出的SerRectwo-LSH方法采用的LSH技术特性,只有目标用户的“最相似”好友才会被返回用于进一步的服务推荐,因此我们方案的推荐准确性通常较高(即,平均绝对误差值较低),且接近于基准方法UPCC。类似的实验结果也可在图4(b)中观察到,其中m=300保持不变,n从1000变化到5000。原因与图4(a)相同,此处不再赘述。
 . n = 5000)
. n = 5000)
 . m = 300)
. m = 300)
Profile 3:SerRectwo-LSH相对于k的推荐准确性
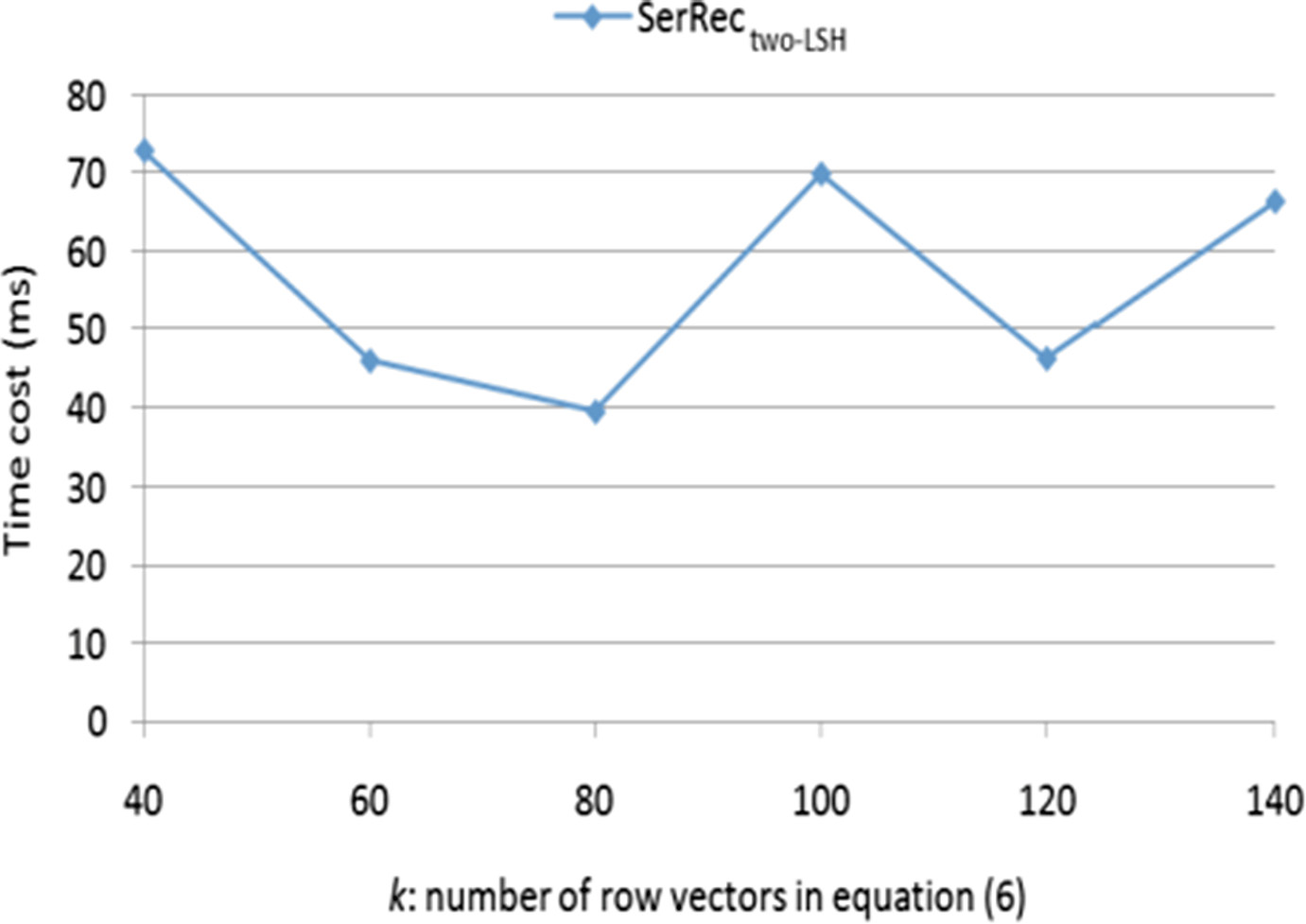
在本剖面中,我们测试了我们的SerRectwo-LSH方法的推荐准确性与参数k(即公式(6)中的行向量数量)之间的关系。实验参数设置如下:m=200, n=3000, T=10, r=8, p=5, k从40变化到140。具体的实验结果如图5所示。
如图5所示,SerRectwo-LSH方法的推荐准确性随k的增长而近似提升(即,平均绝对误差值近似减小);这是由于SerRectwo-LSH方法中采用的MinHash技术本质上是一种基于概率的搜索技术,根据MinHash理论,较大的k值通常意味着更高的搜索准确性[17]。
Profile 4:SerRectwo-LSH相对于k的推荐效率
在本文中,我们测试了所提出的SerRectwo-LSH方法的推荐效率与参数k(即公式(6)中的行向量数量)之间的关系。参数设置如下:m=200,n=3000,T=10,r=8,p=5,k的取值范围为40到140。实验结果如图6所示。
从图6可以看出,SerRectwo-LSH的时间开销与参数k之间的关系并不十分规律。这是因为式(6)中的行向量仅用于生成离线的用户签名,而与在线相似朋友搜索的效率无关。此外,如图6所示,SerRectwo-LSH的时间开销相当小,由于我们方法中采用的MinHash的时间复杂度基于MinHash理论[17]为常数。
Profile 5:SerRectwo-LSH相对于r的推荐准确性
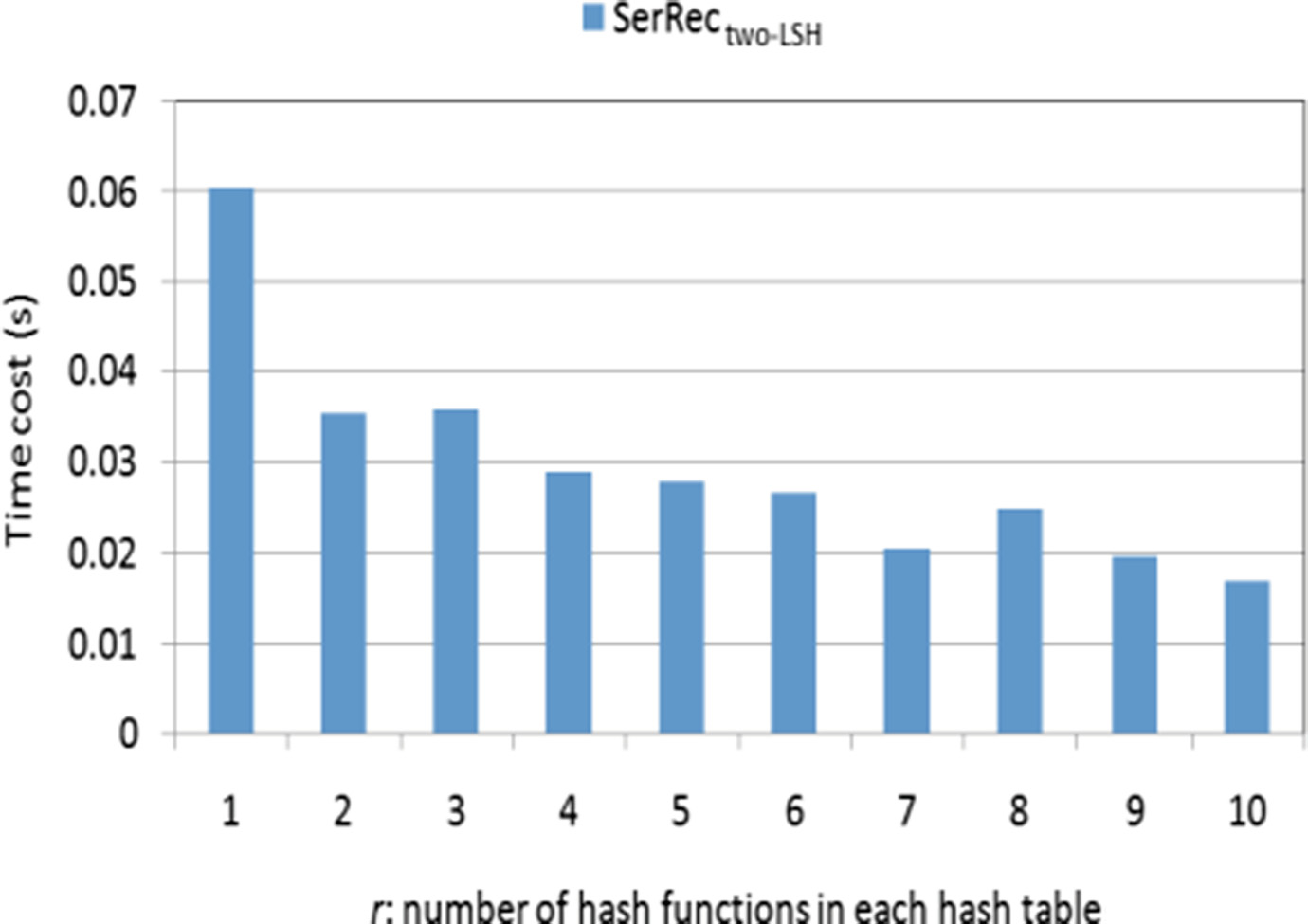
In this profile,我们测试了我们的SerRectwo-LSH方法的推荐准确性与参数r(即每个哈希表中的哈希函数数量)之间的关系。实验参数设置如下:m=200, n=3000, T=10, k=30, p=5, r从1变化到9。实验结果如图7所示。
如图7所示,推荐准确性随着r的增长而近似提升(即平均绝对误差减小)。这是因为较大的r值通常意味着更严格的相似好友搜索过滤条件;因此,获得的目标用户的好友与其更为相似,从而相应地提高了推荐准确性。此外,当r较大时(例如,当r=5、7、9),仅获取并选用目标用户“最相似”的好友进行服务推荐;因此,推荐准确性大致保持不变。
Profile 6:SerRectwo-LSH相对于r的推荐效率
在本文中,我们测试了SerRectwo-LSH方法相对于r的推荐效率。实验参数设置如下:m=200,n=3000,T=10,k=30,p=5,r从1变化到10。实验结果如图8所示。
如图8所示,SerRectwo-LSH方法的时间开销随着r的增大而近似减少。这是因为较大的r值通常意味着在搜索相似朋友时过滤条件更严格;因此当r增大时,返回并用于服务推荐的目标用户的相似朋友数量更少。因此,随着r的增长,时间开销近似减少。
6 结论
传统的基于CF的Web服务推荐方法通常假设推荐基础(即历史服务质量数据)是集中的,未考虑分布式服务推荐场景以及由此带来的隐私泄露风险。针对这一挑战,我们将局部敏感哈希(LSH)技术引入分布式服务推荐,并进一步提出一种两阶段基于LSH的推荐方法,命名为SerRectwo-LSH,以保护用户隐私信息。
具体而言,首先,采用LSH技术保护用户的部分隐私数据,例如用户观测到的历史服务质量数据;其次,采用MinHash(一种LSH变体)技术保护另一类用户隐私,例如用户调用过的服务集。最后,通过在真实世界分布式服务质量数据集WS‐DREAM上进行的一系列实验,验证了该方案在保证隐私保护的同时,在服务推荐准确性与效率方面的可行性。
由于LSH本质上是一种基于概率的技术,我们提出的SerRectwo-LSH服务推荐方法在某些情况下可能无法生成任何推荐结果。未来,我们将研究这一意外的推荐失败问题,并进一步完善我们的工作,以提高推荐鲁棒性。

















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









