




 本文澄清了JMeter压测中的常见误解,并介绍了如何通过添加ConstantThroughputTimer来精确控制每秒查询率(QPS),实现预期的并发量。
本文澄清了JMeter压测中的常见误解,并介绍了如何通过添加ConstantThroughputTimer来精确控制每秒查询率(QPS),实现预期的并发量。
1、误区
在JMeter压测过程中,我们通常认为1s内100的并发量(即:QPS为100)的设置如下:
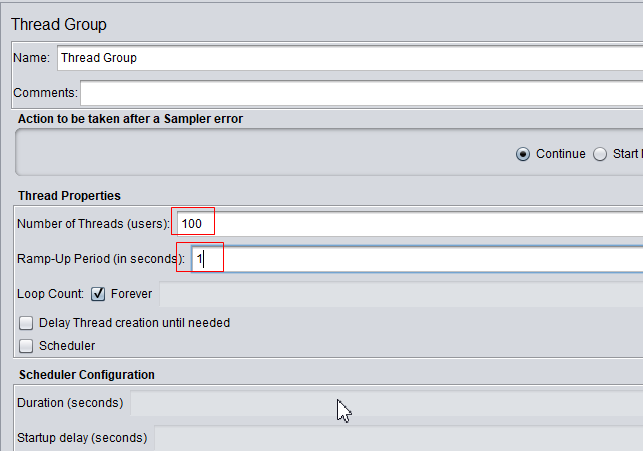
此时,没有再添加额外的控制器。上述中的参数设置解释:
Number of Threads(users): 启用的并发线程个数
Ramp0up Period(in seconds):在多少秒之内将上述并发的线程启动起来
Loop Count:控制循环次数
说明:
一个常见的误解,认为Number of Threads(users)设置为100,Ramp-Up Period(in seconds)设置为1,就是每秒发起100个请求量(错误)。
上述的设置,表示在1s内启动100个线程,之后,jmeter便以最大限度的100个并发进行压测,不能保证1s内只有100个请求。
我们用上述的设置,对某个接口进行压测,发现:

在一秒内,发起的请求居然有五百多个,与实际想要的1s发起100个并发是有差别的。
2、解决方法:
添加Constant Throughput Timer(常数吞吐量定时器),该定时器可以方便地控制给定的取样器发送请求的吞吐量。
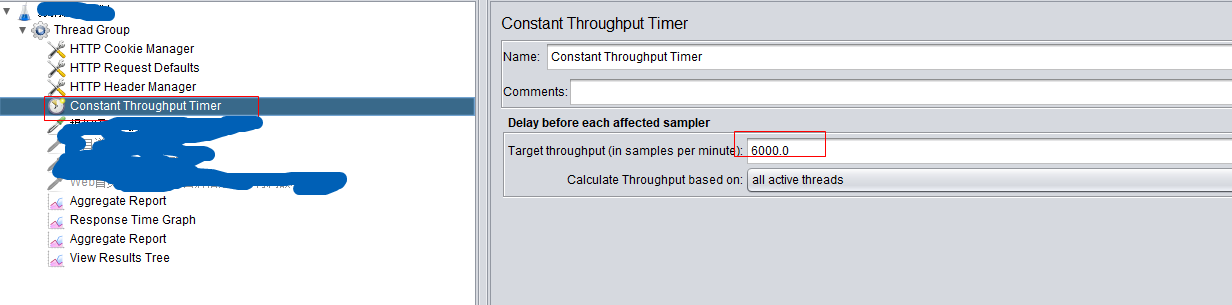
Delay before each affected sampleer下的Target throughput(in samples per minute)设置的值为6000(由于单位是一分钟,如果要求QPS为100,则该值设置为60*100=6000)
Calculate Throughput based on的选项有5个(这里我选择all active threads),分别是:
1)This thread only:控制每个线程的吞吐量,选择这种模式时,总的吞吐量为设置的target Throughput 乘以改线程的数量。
2)all active threads:设置的target Throughput 将分配在每个活跃线程上,每个活跃线程在上次运行结束后等待合理的时间再次运行。活跃线程指同一时刻同时运行的线程。
3)all active threads in current thread group:设置的target Throughput将分配在当前线程组的每一个活跃线程上,当测试计划中只有一个线程时,改选项和all active threads选项的效果完全相同。
4)all active threads(shared):与all active threads的选项基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程上运行一次结束后等待合理的时间后再次运行。
5)all active threads in current thread group(shared):与all active threads in current thread group 基本相同,唯一的区别是,每个活跃线程都会在所有活跃线程的上一次运行结束后等待合理的时间再次运行。

















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









