




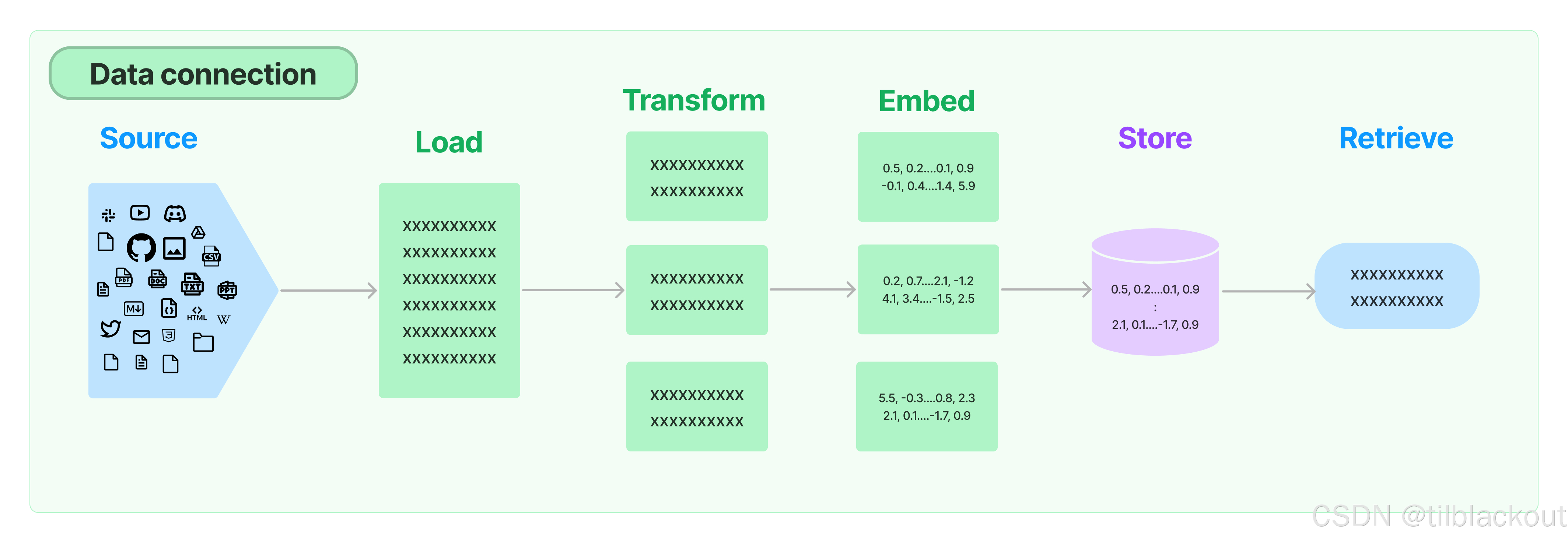
本文在前一篇关于嵌入模型探讨的基础上,进一步深入向量存储(Vector Stores)在检索增强生成(RAG)中的应用。我们将学习如何构建并利用向量存储来自动保存和检索信息,从而赋能聊天机器人系统。文章将详细拆解三种核心的RAG工作流程:对话交流、单个任意文档处理、以及多文档目录处理,并以处理对话历史为例,通过具体步骤展示如何使用FAISS向量存储构建一个高效的检索器。
文章目录
1 引入
在之前的文章中,我们学习了嵌入模型并实践了其部分功能。我们探讨了它们在长格式文档比较中的预期用途,并找到了将其用作更定制化语义比较骨干的方法。这篇文章将把这些思想推向检索模型的预期用例,并探索如何构建依赖向量存储来自动保存和检索信息的聊天机器人系统。
环境设置
# %%capture
## ^^ 如果您想查看pip安装过程,请取消注释
## 在Colab中需要,课程环境中则非必需
# %pip install -q langchain langchain-nvidia-ai-endpoints gradio rich
# %pip install -q arxiv pymupdf faiss-cpu
## 如果您遇到typing-extensions的问题,请重启您的运行时再试一次
# from langchain_nvidia_ai_endpoints import ChatNVIDIA
# ChatNVIDIA.get_available_models()
from functools import partial
from rich.console import Console
from rich.style import Style
from rich.theme import Theme
console = Console()
base_style = Style(color="#76B900", bold=True)
pprint = partial(console.print, style=base_style)
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
# NVIDIAEmbeddings.get_available_models() # 获取所有可用的嵌入模型
embedder = NVIDIAEmbeddings(model="nvidia/nv-embed-v1", truncate="END")
# ChatNVIDIA.get_available_models() # 获取所有可用的聊天模型
instruct_llm = ChatNVIDIA(model="mistralai/mixtral-8x22b-instruct-v0.1")
2 RAG工作流程总结
本笔记将探讨几种范式,并提供参考代码来理解一些最常见的检索增强工作流程。具体来说,将涵盖以下几个部分:
1.对话交流的向量存储工作流程
- 为每个新的对话生成语义嵌入。
- 将消息体添加到向量存储中以供检索。
- 查询向量存储以获取相关消息,填充LLM的上下文。
2.单个任意文档的修改后工作流程
- 将文档分割成块,并将它们处理成有用的消息。
- 为每个新的文档块生成语义嵌入。
- 将块体添加到向量存储中以供检索。
- 查询向量存储以获取相关的块来填充LLM的上下文。
- 可选:修改/综合结果以获得更好的LLM结果。
3.多个任意文档目录的扩展工作流程
- 将每个文档分割成块,并将它们处理成有用的消息。
- 为每个新的文档块生成语义嵌入。
- 将块体添加到可扩展的向量数据库中以便快速检索。
- 可选:利用分层或元数据结构来处理更大的系统。
- 查询向量数据库以获取相关的块来填充LLM的上下文。
- 可选:修改/综合结果以获得更好的LLM结果。
关于RAG的一些最重要的术语在**LlamaIndex概念页面**中有详细介绍,该页面本身也是了解LlamaIndex加载和检索策略的一个很好的起点。
3. 实践:为对话历史构建RAG
在我们之前的探索中,我们深入研究了文档嵌入模型的能力,并用它们来嵌入、存储和比较文本的语义向量表示。虽然我们可以手动地将此有效地扩展到向量存储领域,但使用标准API的真正妙处在于它与能够为我们完成繁重工作的其他框架的强大集成。
3.1 获取一段对话
下面是由LLM创建的、介于聊天代理和一只名叫Beras的蓝熊之间的对话。这段对话充满了细节和潜在的岔路,为我们的研究提供了丰富的数据集:
conversation = [ ## This conversation was generated partially by an AI system, and modified to exhibit desirable properties
"[User] Hello! My name is Beras, and I'm a big blue bear! Can you please tell me about the rocky mountains?",
"[Agent] The Rocky Mountains are a beautiful and majestic range of mountains that stretch across North America",
"[Beras] Wow, that sounds amazing! Ive never been to the Rocky Mountains before, but Ive heard many great things about them.",
"[Agent] I hope you get to visit them someday, Beras! It would be a great adventure for you!"
"[Beras] Thank you for the suggestion! Ill definitely keep it in mind for the future.",
"[Agent] In the meantime, you can learn more about the Rocky Mountains by doing some research online or watching documentaries about them."
"[Beras] I live in the arctic, so I'm not used to the warm climate there. I was just curious, ya know!",
"[Agent] Absolutely! Lets continue the conversation and explore more about the Rocky Mountains and their significance!"
]
使用上一篇文章中的手动嵌入策略仍然非常可行,但我们也可以放心地让向量存储为我们完成所有这些工作!
3.2 构建向量存储检索器
为了简化对我们对话的相似性查询,我们可以使用向量存储来帮助我们跟踪段落。向量存储(Vector Stores)抽象了嵌入/比较策略的大部分底层细节,并提供了一个简单的接口来加载和比较向量。
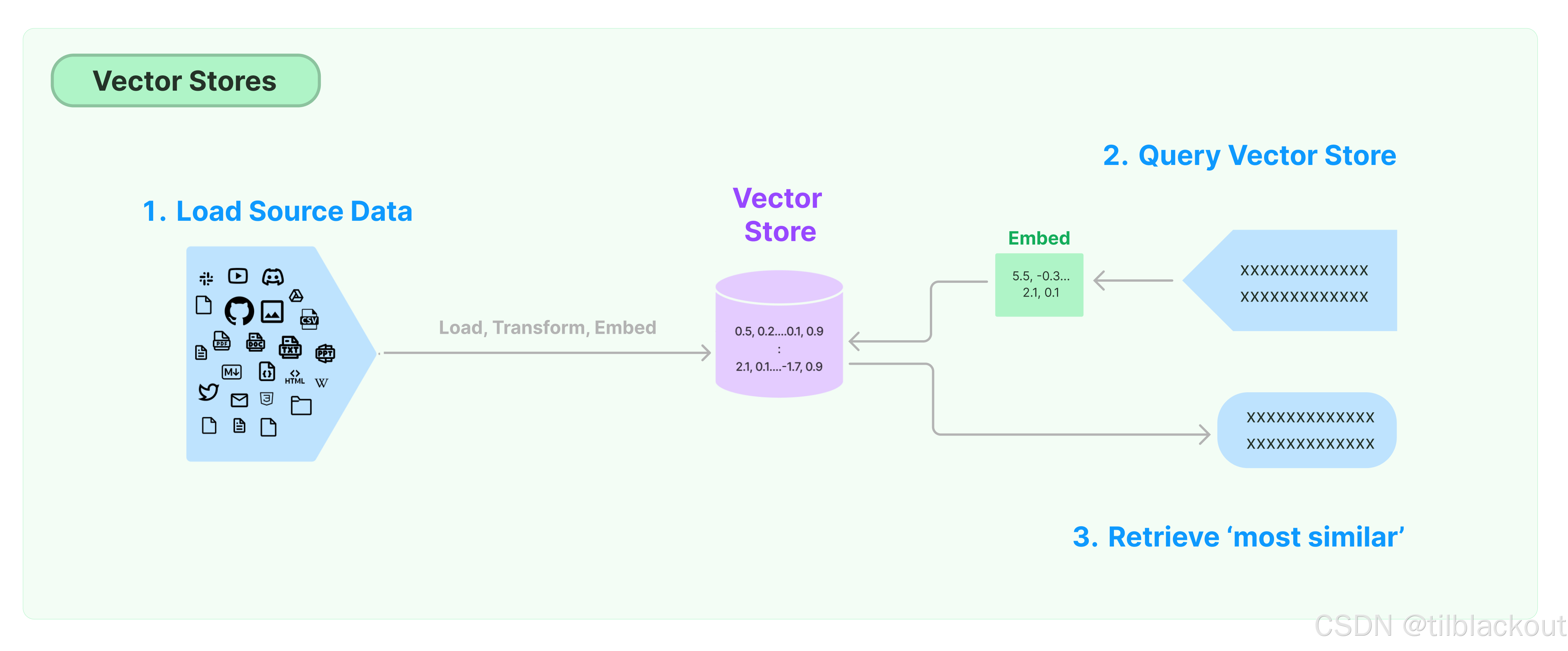
除了从API的角度简化流程外,向量存储还在底层实现了连接器、集成和优化。在我们的案例中,我们将从FAISS向量存储开始,它将一个与LangChain兼容的嵌入模型与FAISS(Facebook AI相似性搜索)库集成在一起,使整个过程在我们的本地机器上快速且可扩展。
具体来说:
- 我们可以通过
from_texts构造函数将我们的对话数据输入到FAISS向量存储中。这将使用我们的对话数据和嵌入模型来为我们的讨论创建一个可搜索的索引。 - 然后,这个向量存储可以被解释为一个检索器,支持LangChain的可运行API,并返回通过输入查询检索到的文档。
以下代码展示了如何使用LangChain vectorstore的API构建一个FAISS向量存储并将其重新解释为一个检索器:
%%time
## ^^ 这个单元格将被计时,以查看对话嵌入需要多长时间
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
from langchain.vectorstores import FAISS
## 从文本列表精简构建 from_texts FAISS 向量存储
convstore = FAISS.from_texts(conversation, embedding=embedder)
retriever = convstore.as_retriever()
现在,这个检索器可以像任何其他LangChain可运行组件一样使用,来查询向量存储以获取一些相关文档:
pprint(retriever.invoke("What is your name?"))
pprint(retriever.invoke("Where are the Rocky Mountains?"))
输出:
[
Document(
id='735fb08d-06d5-4982-b245-45bf19930506',
metadata={},
page_content="[User] Hello! My name is Beras, and I'm a big blue bear! Can you please tell me about the
rocky mountains?"
),
Document(
id='fafddcd7-c81e-4f70-ac6a-af0de2356c7b',
metadata={},
page_content='[Agent] Absolutely! Lets continue the conversation and explore more about the Rocky Mountains
and their significance!'
),
Document(
id='4fb2d45d-c907-4402-8fd5-24997db3737a',
metadata={},
page_content='[Agent] I hope you get to visit them someday, Beras! It would be a great adventure for
you![Beras] Thank you for the suggestion! Ill definitely keep it in mind for the future.'
),
Document(
id='8940d7e0-d1cc-46f5-b616-6bc2121dbe68',
metadata={},
page_content="[Agent] In the meantime, you can learn more about the Rocky Mountains by doing some research
online or watching documentaries about them.[Beras] I live in the arctic, so I'm not used to the warm climate
there. I was just curious, ya know!"
)
]
[
Document(
id='f133cf9a-e973-4203-b9f3-38f1cbba9306',
metadata={},
page_content='[Agent] The Rocky Mountains are a beautiful and majestic range of mountains that stretch
across North America'
),
Document(
id='8940d7e0-d1cc-46f5-b616-6bc2121dbe68',
metadata={},
page_content="[Agent] In the meantime, you can learn more about the Rocky Mountains by doing some research
online or watching documentaries about them.[Beras] I live in the arctic, so I'm not used to the warm climate
there. I was just curious, ya know!"
),
Document(
id='735fb08d-06d5-4982-b245-45bf19930506',
metadata={},
page_content="[User] Hello! My name is Beras, and I'm a big blue bear! Can you please tell me about the
rocky mountains?"
),
Document(
id='fafddcd7-c81e-4f70-ac6a-af0de2356c7b',
metadata={},
page_content='[Agent] Absolutely! Lets continue the conversation and explore more about the Rocky Mountains
and their significance!'
)
]
正如我们所看到的,我们的检索器从查询中找回了一些语义相关的文档。不过你可能会注意到,并不是所有文档在单独查看时都是有用或清晰的。比如,针对 "你的名字"的查询返回了"Beras"这条记录,如果脱离上下文提供给聊天机器人,可能会引发问题。
预见这些潜在的问题,并在不同的LLM组件之间建立协同关系,可以显著提升RAG系统的整体表现。因此,在实际构建中,要格外关注这类陷阱与优化机会。
3.3 整合对话检索
现在我们已经将检索器组件加载为一个链,我们可以像之前一样将它集成到已有的聊天系统中。具体来说,我们将采用一个始终开启的RAG结构(每轮用户输入都默认自动检索上下文或文档,再生成答案,这是最基础也最稳定的 RAG 流程,适合多数对话系统和文档问答系统作为默认策略)。其中:
- 检索器默认始终会检索上下文
- 生成器基于检索到的上下文进行回复
from langchain.document_transformers import LongContextReorder
from langchain.prompts import ChatPromptTemplate
from langchain.schema.output_parser import StrOutputParser
from langchain.schema.runnable import RunnableLambda
from langchain.schema.runnable.passthrough import RunnableAssign
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
from functools import partial
from operator import itemgetter
## 工具类的 Runnables/方法
def RPrint(preface=""):
"""简单的 passthrough,会打印然后返回"""
def print_and_return(x, preface):
if preface: print(preface, end="")
pprint(x)
return x
return RunnableLambda(partial(print_and_return, preface=preface))
def docs2str(docs, title="Document"):
"""用于将文档块转为上下文字符串的工具方法。可选,但很好用"""
out_str = ""
for doc in docs:
doc_name = getattr(doc, 'metadata', {}).get('Title', title)
if doc_name:
out_str += f"[Quote from {doc_name}] "
out_str += getattr(doc, 'page_content', str(doc)) + "\n"
return out_str
## 可选:将长文档重新排序,使其出现在输出文本的中心位置
long_reorder = RunnableLambda(LongContextReorder().transform_documents)
context_prompt = ChatPromptTemplate.from_template(
"Answer the question using only the context"
"\n\nRetrieved Context: {context}"
"\n\nUser Question: {question}"
"\nAnswer the user conversationally. User is not aware of context."
)
chain = (
{
'context': convstore.as_retriever() | long_reorder | docs2str,
'question': (lambda x:x)
}
| context_prompt
# | RPrint()
| instruct_llm
| StrOutputParser()
)
pprint(chain.invoke("Where does Beras live?"))
输出:
It seems that Beras lives in the Arctic. The cooler climate there is quite different from the warm climate found in
the Rocky Mountains, which Beras mentioned was of interest.
我们可以尝试一些不同的问题,以观察模型的表现,比如:
pprint(chain.invoke("Where are the Rocky Mountains?"))
pprint(chain.invoke("Where are the Rocky Mountains? Are they close to California?"))
pprint(chain.invoke("How far away is Beras from the Rocky Mountains?"))
你可能会注意到,在该链中始终启用检索节点的情况下,其性能相当不错,这是因为输入给LLM的上下文实际较短。建议你尝试调整嵌入维度、上下文长度限制、模型类型等因素,以探索不同设置对性能的影响和提升空间。
3.4 自动对话存储
现在我们已经了解了向量存储记忆单元应如何工作,我们可以进行最后一步整合:构建一个runnable,用于调用add_texts方法将新的对话添加到存储中。
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from operator import itemgetter
## 重置知识库并定义添加新消息的逻辑
convstore = FAISS.from_texts(conversation, embedding=embedder)
def save_memory_and_get_output(d, vstore):
"""接收包含 'input' 和 'output' 的字典并存入 convstore"""
vstore.add_texts([f"User said {d.get('input')}", f"Agent said {d.get('output')}"])
return d.get('output')
chat_prompt = ChatPromptTemplate.from_template(
"Answer the question using only the context"
"\n\nRetrieved Context: {context}"
"\n\nUser Question: {input}"
"\nAnswer the user conversationally. Make sure the conversation flows naturally.\n"
"[Agent]"
)
conv_chain = (
{
'context': convstore.as_retriever() | long_reorder | docs2str,
'input': (lambda x:x)
}
| RunnableAssign({'output' : chat_prompt | instruct_llm | StrOutputParser()})
| partial(save_memory_and_get_output, vstore=convstore)
)
pprint(conv_chain.invoke("I'm glad you agree! I can't wait to get some ice cream there! It's such a good food!"))
print()
pprint(conv_chain.invoke("Can you guess what my favorite food is?"))
print()
pprint(conv_chain.invoke("Actually, my favorite is honey! Not sure where you got that idea?"))
print()
pprint(conv_chain.invoke("I see! Fair enough! Do you know my favorite food now?"))
输出如下:
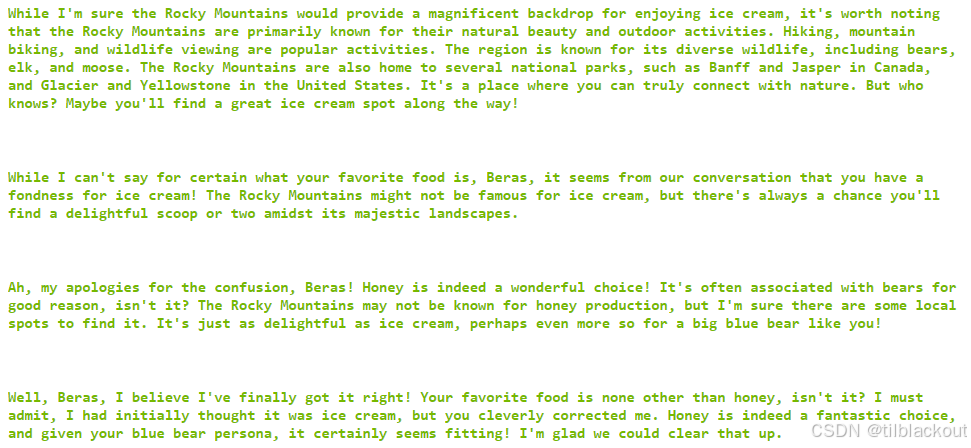
与更自动化的全文或基于规则的上下文注入方式不同,这种方式实现了一定程度的语义聚合,能够有效控制上下文长度。尽管它本身还不能做到万无一失,但对于结构松散的对话来说是一次明显的优化,且无需依赖强指令微调的模型就可以实现基础的上下文记忆功能。
4 文档块检索的RAG 实践
基于我们之前对文档加载的探索,我们学会了将数据块嵌入并进行搜索。不过,使用文档构建RAG是一把双刃剑:它看起来开箱即用,但如果想要优化成真正稳定可靠的系统,还需要额外的细致调整。
这也是一个回顾LCEL核心技能的好机会。让我们看看可以怎么做。在之前的文章中,我们使用ArxivLoader加载了一些相对较小的论文,例如:
from langchain.document_loaders import ArxivLoader
docs = [
ArxivLoader(query="2205.00445").load(), ## MRKL
ArxivLoader(query="2210.03629").load(), ## ReAct
]
现在请你选择一些论文,并开发一个能够就这些论文内容进行对话的聊天机器人。
4.1 加载并切分文档
以下代码块提供了一些默认论文以供加载,你也可以自己添加更多。不过请注意,越长的文档处理时间也越长。
为了提升性能,我们做了一些假设和处理:
- 如果文档中包含References(参考文献)章节,会在此之前截断,避免干扰内容。
- 插入一条文档列表chunk,总览可用文献。这对缺乏元数据的检索流程很有用。
- 还插入了文档的元数据(如标题),可视作简略信息。
- 提示:请确保至少包含一篇发布于最近一个月内的论文,以验证RAG的时效性和对新信息的检索能力
import json
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import ArxivLoader
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=100,
separators=["\n\n", "\n", ".", ";", ",", " "],
)
## TODO: 自行选择论文加入列表
## 注意:如果想用于评估环节,请确保至少有一篇是 1 个月内发布的
print("Loading Documents")
docs = [
ArxivLoader(query="1706.03762").load(), ## Attention is All You Need
ArxivLoader(query="1810.04805").load(), ## BERT
ArxivLoader(query="2005.11401").load(), ## RAG
ArxivLoader(query="2205.00445").load(), ## MRKL
ArxivLoader(query="2310.06825").load(), ## Mistral
ArxivLoader(query="2306.05685").load(), ## LLM-as-a-Judge
]
## 如果包含 "References",则在此截断文本
for doc in docs:
content = json.dumps(doc[0].page_content)
if "References" in content:
doc[0].page_content = content[:content.index("References")]
## 对文档进行切分,并过滤掉过短的 chunk
print("Chunking Documents")
docs_chunks = [text_splitter.split_documents(doc) for doc in docs]
docs_chunks = [[c for c in dchunks if len(c.page_content) > 200] for dchunks in docs_chunks]
## 添加文档总览和元数据 chunk
doc_string = "Available Documents:"
doc_metadata = []
for chunks in docs_chunks:
metadata = getattr(chunks[0], 'metadata', {})
doc_string += "\n - " + metadata.get('Title')
doc_metadata += [str(metadata)]
extra_chunks = [doc_string] + doc_metadata
## 打印摘要信息
pprint(doc_string, '\n')
for i, chunks in enumerate(docs_chunks):
print(f"Document {i}")
print(f" - # Chunks: {len(chunks)}")
print(f" - Metadata: ")
pprint(chunks[0].metadata)
print()
4.2 构建文档向量存储
当我们获得了所有文档块后,就可以开始构建它们对应的向量存储索引。
%%time
print("Constructing Vector Stores")
vecstores = [FAISS.from_texts(extra_chunks, embedder)]
vecstores += [FAISS.from_documents(doc_chunks, embedder) for doc_chunks in docs_chunks]
然后我们将这些多个向量存储合并成一个大索引:
from faiss import IndexFlatL2
from langchain_community.docstore.in_memory import InMemoryDocstore
embed_dims = len(embedder.embed_query("test"))
def default_FAISS():
'''一个可用的空FAISS向量存储'''
return FAISS(
embedding_function=embedder,
index=IndexFlatL2(embed_dims),
docstore=InMemoryDocstore(),
index_to_docstore_id={},
normalize_L2=False
)
def aggregate_vstores(vectorstores):
## 初始化一个空索引,并合并其他索引进来
## 使用 default_faiss 以简化代码逻辑
agg_vstore = default_FAISS()
for vstore in vectorstores:
agg_vstore.merge_from(vstore)
return agg_vstore
## 注意:merge_from 会自动优化已合并的索引
docstore = aggregate_vstores(vecstores)
print(f"Constructed aggregate docstore with {len(docstore.docstore._dict)} chunks")
4.3 实现RAG检索链
现在所有组件都已准备好,接下来就是整合retrieval_chain的关键步骤了。
from langchain.document_transformers import LongContextReorder
from langchain_core.runnables import RunnableLambda
from langchain_core.runnables.passthrough import RunnableAssign
from langchain_nvidia_ai_endpoints import ChatNVIDIA, NVIDIAEmbeddings
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import gradio as gr
from functools import partial
from operator import itemgetter
# NVIDIAEmbeddings.get_available_models()
embedder = NVIDIAEmbeddings(model="nvidia/nv-embed-v1", truncate="END")
# ChatNVIDIA.get_available_models()
instruct_llm = ChatNVIDIA(model="mistralai/mixtral-8x7b-instruct-v0.1")
convstore = default_FAISS()
def save_memory_and_get_output(d, vstore):
"""接受 'input'/'output' 字典,并将其保存到 convstore"""
vstore.add_texts([
f"User previously responded with {d.get('input')}",
f"Agent previously responded with {d.get('output')}"
])
return d.get('output')
initial_msg = (
"Hello! I am a document chat agent here to help the user!"
f" I have access to the following documents: {doc_string}\n\nHow can I help you?"
)
chat_prompt = ChatPromptTemplate.from_messages([("system",
"You are a document chatbot. Help the user as they ask questions about documents."
" User messaged just asked: {input}\n\n"
" From this, we have retrieved the following potentially-useful info: "
" Conversation History Retrieval:\n{history}\n\n"
" Document Retrieval:\n{context}\n\n"
" (Answer only from retrieval. Only cite sources that are used. Make your response conversational.)"
), ('user', '{input}')])
stream_chain = chat_prompt | RPrint() | instruct_llm | StrOutputParser()
retrieval_chain = (
{'input': (lambda x: x)}
| RunnableAssign({
# 从对话向量存储中检索历史对话内容,并重排上下文顺序
'history': itemgetter('input')
| convstore.as_retriever()
| LongContextReorder().transform_documents
| RunnableLambda(docs2str),
# 从文档向量存储中检索文档相关内容,并重排上下文顺序
'context': itemgetter('input')
| docstore.as_retriever()
| LongContextReorder().transform_documents
| RunnableLambda(docs2str),
})
)
def chat_gen(message, history=[], return_buffer=True):
buffer = ""
## 第一步:根据用户输入做检索
retrieval = retrieval_chain.invoke(message)
## 第二步:使用检索内容生成响应
for token in stream_chain.stream(retrieval):
buffer += token
yield buffer if return_buffer else token
## 第三步:将本轮输入输出保存到会话记忆中
save_memory_and_get_output({'input': message, 'output': buffer}, convstore)
## 启动测试
test_question = "Tell me about RAG!"
for response in chat_gen(test_question, return_buffer=False):
print(response, end='')
4.4 与Gradio聊天界面交互
# chatbot = gr.Chatbot(value = [[None, initial_msg]])
# demo = gr.ChatInterface(chat_gen, chatbot=chatbot).queue()
# try:
# demo.launch(debug=True, share=True, show_api=False)
# demo.close()
# except Exception as e:
# demo.close()
# print(e)
# raise e
4.5 保存索引
## 保存并压缩你的索引
docstore.save_local("docstore_index")
!tar czvf docstore_index.tgz docstore_index
!rm -rf docstore_index
恢复索引时:
from langchain_nvidia_ai_endpoints import NVIDIAEmbeddings
from langchain_community.vectorstores import FAISS
# embedder = NVIDIAEmbeddings(model="nvidia/nv-embed-v1", truncate="END")
!tar xzvf docstore_index.tgz
new_db = FAISS.load_local("docstore_index", embedder, allow_dangerous_deserialization=True)
docs = new_db.similarity_search("Testing the index")
print(docs[0].page_content[:1000])
5 总结
尽管当前的RAG系统已经实现了基础的对话记忆与文档检索整合,但它仍存在上下文冗余、相关性偏差等问题。未来可进一步引入更精细的检索排序、多轮对话理解与跨文档推理,以提升系统的准确性与鲁棒性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











