




目前,我们按请求到达的顺序依次处理,并使用固定批大小为 8 的方式进行推理。这种方式不仅导致 GPU 利用率低,还增加了响应延迟。这在实际应用中很常见,尤其是当用户发送的是单个推理请求而不是批量数据时,GPU 资源常常得不到充分利用。
虽然模型本身的优化可以提升运行速度,但如果推理服务的架构设计不合理,仍会导致资源浪费。
为了解决这个问题,Triton 提供了多种机制来提升 GPU 利用率并降低延迟。本节我们将重点介绍三种策略:并发模型执行、调度策略 和动态批处理。
本文用到的脚本文件可在Triton模型部署相关脚本文件下载。
文章目录
1 并发模型执行
Triton 架构允许多个模型以及同一模型的多个实例在单个 GPU 上并行执行。下图展示了一个例子:有两个模型model0和model1。假设Triton当前未处理任何请求,当分别针对两个模型的请求同时到达时,Triton会立即将它们调度到GPU上,并由GPU的硬件调度器并行执行它们的计算。
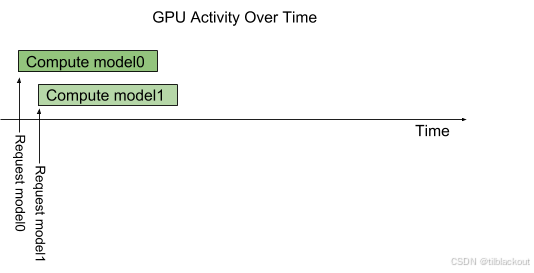
默认行为
默认情况下,如果多个相同模型的请求同时到达,Triton会串行执行它们,只在GPU上一次调度一个请求,如下图所示。
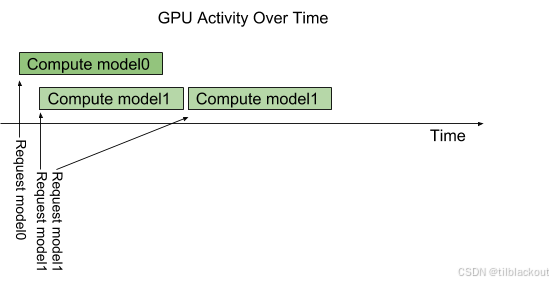
Triton 提供了实例组(instance-group)功能,允许为每个模型配置多个并行执行的实例。每个并行执行称为一个 执行实例。默认情况下,Triton为每个模型分配一个实例,这意味着每次只能有一个推理在进行中。
实例组(Instance Groups)
通过instance-group配置,可以增加模型的执行实例数量。下图展示了当模型model1配置为允许三个执行实例时的执行情况。可以看到,前三个 model1 推理请求会被立即并行执行,第四个请求需要等待前三个中的一个完成后才能执行。
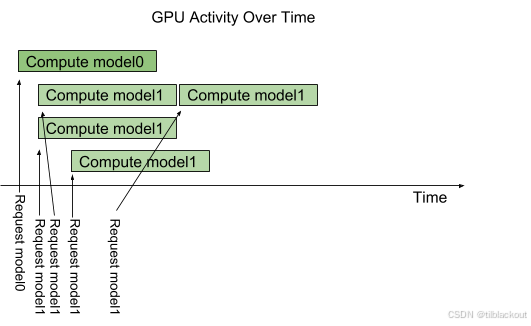
1.1 GPU利用率观察
对于大多数模型来说,Triton中能带来最大性能提升的功能是动态批处理。
- 动态批处理:自动将多个小请求合并成一个大批次,然后一次性送入模型进行推理,以此提升吞吐量并更好地利用 GPU。
与设置多个模型实例相比,动态批处理无需额外存储模型参数或重复读取模型数据,能更高效地利用GPU资源。在我们配置多个执行实例前,先再次使用单个实例执行模型,观察GPU的资源利用情况。
(1)在运行性能工具前,先执行以下命令观察GPU状态:
watch -n0.5 nvidia-smi
你应该会看到如下输出:
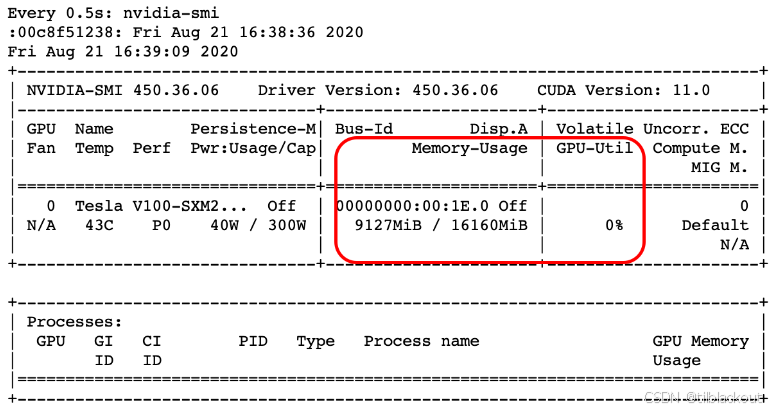
(2)执行与上一篇文章中相同的基准测试,但将批大小改为1,再次观察 nvidia-smi 的输出,注意GPU的内存和利用率。
# 设置 Triton Server 主机名,并检查服务器状态
tritonServerHostName = "triton"
!./utilities/wait_for_triton_server.sh {tritonServerHostName}
# 加载前面的配置
modelVersion="1"
precision="fp32"
batchSize="1"
maxLatency="500"
maxClientThreads="10"
maxConcurrency="2"
dockerBridge="host"
resultsFolderName="1"
profilingData="utilities/profiling_data_int64"
# 配置参数并运行性能测试工具
modelName = "bertQA-onnx-trt-fp16"
maxConcurrency= "10"
batchSize="1"
print("运行模型: " + modelName)
!bash ./utilities/run_perf_client_local.sh \
{modelName} \
{modelVersion} \
{precision} \
{batchSize} \
{maxLatency} \
{maxClientThreads} \
{maxConcurrency} \
{tritonServerHostName} \
{dockerBridge} \
{resultsFolderName} \
{profilingData}
你应该会观察到如下利用率:
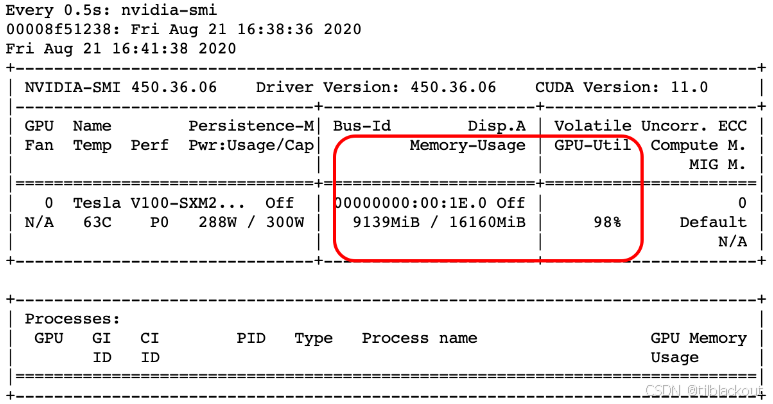
maxConcurrency=10 意味着同时有多个请求并发执行,虽然每个请求只有一个样本(batch size=1),但并发度高,还是能让GPU满负荷运转。
增加实例数量通常能显著提升推理吞吐量,特别是在批大小较小或请求频繁的情况下。单个模型实例只能处理一个请求流,容易导致GPU空闲时间较多,无法发挥其并行计算优势。而多个实例可以并发处理多个请求,使GPU能同时运行多个线程,从而提高总体利用率。
1.2 启用并发执行
现在我们来看看如何启用并发执行,并观察它对模型性能的影响。和上一篇文章一样,首先将检查点转换为可部署模型并导出:
# 设置模型名称和导出格式
modelName = "bertQA-onnx-conexec"
exportFormat = "onnx"
# 导出模型为 ONNX 格式并生成 Triton 配置
!python ./deployer/deployer.py \
--{exportFormat} \
--save-dir ./candidatemodels \
--triton-model-name {modelName} \
--triton-model-version 1 \
--triton-max-batch-size 8 \
--triton-dyn-batching-delay 0 \
--triton-engine-count 1 \
-- --checkpoint ./data/bert_qa.pt \
--config_file ./bert_config.json \
--vocab_file ./vocab \
--predict_file ./squad/v1.1/dev-v1.1.json \
--do_lower_case \
--batch_size=8
# 查看导出模型的文件夹内容
!ls -alh ./candidatemodels/bertQA-onnx-conexec
现在我们在./candidatemodels/bertQA-onnx-conexec/中可以看到配置文件 config.pbtxt。为了启用多个实例,需要将config.pbtxt文件中instance_group的count值从1改为更大的数字,这里改为2。
instance_group [
{
count: 2
kind: KIND_GPU
gpus: [ 0 ]
}
]
为了公平比较,也启用TensorRT加速,在 optimization 块中加入:
optimization {
execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" }
}]
}
cuda { graphs: 0 }
}
保存配置后,将模型移动到Triton模型库中:
# 将模型移动到 Triton 模型仓库以供加载
!mv ./candidatemodels/bertQA-onnx-conexec model_repository/
对模型执行标准压力测试,并比较单实例与多实例下的吞吐和延迟变化:
# 设置并发和批大小,运行性能测试工具
maxConcurrency= "10"
batchSize="1"
print("运行模型: " + modelName)
!bash ./utilities/run_perf_client_local.sh \
{modelName} \
{modelVersion} \
{precision} \
{batchSize} \
{maxLatency} \
{maxClientThreads} \
{maxConcurrency} \
{tritonServerHostName} \
{dockerBridge} \
{resultsFolderName} \
{profilingData}
清理模型目录以释放显存,仅保留bertQA-torchscript模型:
# 移除部分模型以释放 GPU 资源
!mv /dli/task/model_repository/bertQA-onnx /dli/task/candidatemodels/
!mv /dli/task/model_repository/bertQA-onnx-conexec /dli/task/candidatemodels/
!mv /dli/task/model_repository/bertQA-onnx-trt-fp16 /dli/task/candidatemodels/
# 查看剩余模型
!ls /dli/task/model_repository
2 调度策略
Triton支持批量推理,允许每个推理请求指定一批输入。在GPU上对一批输入进行推理,可以显著提升吞吐量。然而,在许多应用中,推理请求是单个发送的,而不会一批一批发送,因此它们无法享受到批处理带来的吞吐优势。
推理服务器提供多种调度和批处理算法,支持不同的模型类型和用例,它们能自动帮你合并请求、安排模型的执行方式,从而提高效率。选择调度器/批处理器的关键依据包括:
- 推理任务是否有状态(每次推理都互相独立,比如图像分类模型)或无状态(模型会记住之前的输入,比如语音识别或聊天对话模型)
- 应用是使用单个模型(只有一个模型负责处理请求)还是使用多个模型组成的流水线(多个模型分工合作)
2.1 无状态推理(Stateless Inference)
在无状态推理中(如本课程案例),我们主要有两种调度选项:
- 默认调度器(default scheduler):将请求均匀分发到分配的所有实例。这适用于推理结构已知,且请求是规则批量发送的场景。
- 动态批处理(dynamic batching):将多个单独请求合并成一个批次,并类似地将这些批次分发到所有实例。这将在稍后详细讨论。
2.2 有状态推理(Stateful Inference)
在有些推理任务中,模型需要记住之前发生过的事情,才能正确处理后续请求,这就是有状态推理。有状态模型(或自定义后端)会在推理请求之间维护状态。模型期望接收多个形成一个推理序列的请求,并且所有这些请求必须路由到相同的模型实例,以确保状态的正确更新。
此外,模型还可能需要Triton提供控制信号,例如序列开始的标志。Triton的序列批处理器(sequence batcher)支持两种调度策略:
- Direct(直接):每个序列都绑定到一个固定的批次槽位。适用于模型在每个槽位维护状态的情况。
- Oldest(最旧优先):确保同一序列的请求发送到同一实例,并使用动态批处理将不同序列的推理合并执行。
2.3 管道/集成模型(Pipelines/Ensembles)
集成模型(Ensemble model)表示一个模型流水线,由一个或多个模型组成,并连接它们的输入输出张量。典型用途是封装复杂流程,例如:数据预处理 -> 推理 -> 数据后处理。
使用集成模型可以避免中间张量传输的开销,并减少发送到Triton的请求数量。如下图所示:
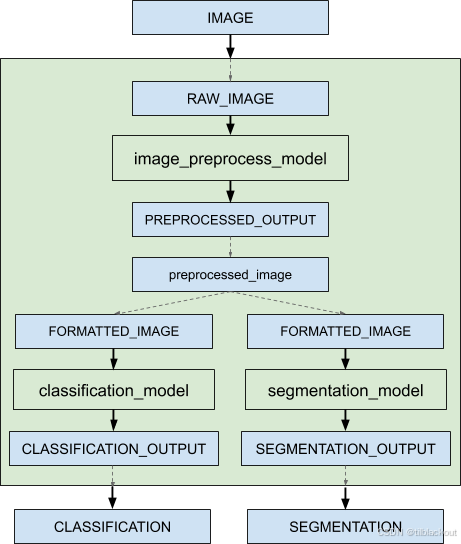
无论集成中的模型使用哪种调度器,整个集成模型必须使用集成调度器(ensemble scheduler)。从外部看,集成模型表现为一个单独的模型,但其内部定义了模型间的数据流步骤(step),调度器负责收集每一步的输出,并将其作为输入提供给下一步。
3 动态批处理(Dynamic Batching)
动态批处理是Triton的一项功能,它允许将多个推理请求在服务器端合并成批,以提升吞吐率。
当模型实例可用时,动态批处理器会尝试将调度器中的请求组装成批。请求按到达顺序被添加到批中。如果可生成一个preferred size(首选大小)的批,则发送该批进行推理;否则,发送一个不超过最大批量大小的最大可能批。
动态批处理器可以配置请求在调度器中等待一段时间,以便其他请求进入队列形成批。例如,下面的配置允许最多等待 100 微秒:
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
max_queue_delay_microseconds: 100
}
3.1 实现动态批处理
首先,我们再次导出一个 ONNX 模型。
# 设置模型名称和导出格式
modelName = "bertQA-onnx-trt-dynbatch"
exportFormat = "onnx"
# 使用 deployer.py 脚本导出模型,配置动态批处理相关参数
!python ./deployer/deployer.py \
--{exportFormat} \
--save-dir ./candidatemodels \
--triton-model-name {modelName} \
--triton-model-version 1 \
--triton-max-batch-size 8 \
--triton-dyn-batching-delay 0 \
--triton-engine-count 1 \
-- --checkpoint ./data/bert_qa.pt \
--config_file ./bert_config.json \
--vocab_file ./vocab \
--predict_file ./squad/v1.1/dev-v1.1.json \
--do_lower_case \
--batch_size=8
修改模型配置文件 config.pbtxt,启用动态批处理:
dynamic_batching {
preferred_batch_size: [ 4, 8 ]
max_queue_delay_microseconds: 100
}
同时启用 TensorRT 加速,在 optimization 中添加:
optimization {
execution_accelerators {
gpu_execution_accelerator : [ {
name : "tensorrt"
parameters { key: "precision_mode" value: "FP16" }
}]
}
cuda { graphs: 0 }
}
保存配置后,将模型移动至 Triton 模型仓库,并运行性能工具进行测试。
# 将模型移动到 Triton 模型仓库中
!mv ./candidatemodels/bertQA-onnx-trt-dynbatch model_repository/
# 配置并运行性能测试工具,测试动态批处理模型
modelName = "bertQA-onnx-trt-dynbatch"
maxConcurency= "10"
batchSize="1"
print("运行模型: " + modelName)
!bash ./utilities/run_perf_client_local.sh \
{modelName} \
{modelVersion} \
{precision} \
{batchSize} \
{maxLatency} \
{maxClientThreads} \
{maxConcurency} \
{tritonServerHostName} \
{dockerBridge} \
{resultsFolderName} \
{profilingData}
运行上述代码,你应该会观察到推理延迟和吞吐量都有显著提升。
4 总结
本文系统介绍了如何通过并发模型执行、调度策略和动态批处理来优化Triton Inference Server的推理性能。在实验中,我们观察了 GPU 利用率的变化,理解了单实例与多实例、静态批处理与动态批处理之间的差异和优势。
我们发现:
- 高并发 + 小批量请求在单实例下可能导致资源瓶颈,而增加实例数量可以提升吞吐;
- 动态批处理能有效整合多个小请求,进一步提升性能,同时减少内存开销;
- 针对不同模型结构(有状态/无状态、单模型/集成模型),选择合适的调度方式是优化的关键。
通过合理配置Triton,我们可以在保证推理准确性的同时,显著提高 GPU 利用率、降低延迟、提升整体服务吞吐能力。下一篇文章,我们将正式评估推理性能,并学习如何在不同并发级别下系统地分析性能…


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











