






一、列表初始化(区别于初始化列表)
介绍:包括多参数函数隐式类型转换在内的,一切皆可列表初始化,其可以不加赋值符号
如:
//这是之前就常见的
int a1[]={1,2,3,4,5};
int a2[5]={0};
//列表初始化结构体与普通内置类型,且不加赋值符号
struct Text
{
int t1;
int t2;
};
Text p {1,2};
int x2 {2};
//对类初始化和临时变量接收
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
,_month(month)
,_day(day)
{
}
protected:
int _year;
int _month;
int _day;
};
Date d1 {2025,3,10};//需要类本身存在三参数构造函数
const Date& d2 {2025,3,10};//接收initializer_list中间转化的临时变量
此处d2处如果不加const,会出现如下报错:
![]()
这是因为initializer list转化的中间变量具有“常性 ”
需要const修饰方可接收
1.补:遇到类型截断时的措施
列表初始化如果遇到类型截断,会报警告或者错误
如
short {100};
二、初始化列表initializer_list
介绍:{}中可以有任意多个值,可以实现挨个插入容器当中
对比于列表初始化:列表初始化的{}中只能有指定数目的值,一次只能为容器提供一个对象
实际上,它本身是一个类模板
template<class T> class initializer_list;
起作用与容器很像,其存储原理是:在栈上开一块数组的空间,initializer_list类型的对象中只存储该数组空间的首尾指针,其在32位下大小位8,存储的位置也在栈上
2.补:初始化列表和列表初始化可以混用
在本身有初始化列表构造的情况下,可以用列表初始化来配合初始化列表进行构造
例如vector中
vector<int> v6{ {1},{2},{3},{4} };三、decltype读取类型并用于创建
decltype是declaration type的缩写,declaration意思是声明,综合起来看是声明类型的意思
整体用法与typeid有些类似,但是decltype的推导结果可以直接作为类型来使用
如:
const int i=1;
decltype(&i) p;//可以生成一个const int*类型的变量p
cout<<typeid(p).name()<<endl;//可以打印查看p的类型
vector<decltype(&i)> vp;//可以生成一个存储const int*类型的顺序表四、nullptr空指针
C++中NULL被置为0,可能会带来这样的问题:
0既可以为整型常量,又可以为指针常量
有种替代方案是:(void*)0,但也存在使用的时候需要强转的问题
nullptr表示空指针,很好的解决了NULL本身的问题
五、左值引用与右值引用
5.1什么是左值和左值引用
左值是一个表示数据的表达式,我们可以获取它的地址,一般情况下可以对他进行赋值(const修饰除外),左值可以出现在赋值符号的左,右两侧
左值引用是左值的引用,给左值取别名
5.2什么是右值和右值引用
右值也是一个表示数据的表达式,我们不可以获取它的地址,右值只能出现在赋值符号的右侧
右值引用是右值的引用,给右值取别名
例如:常量,表达式返回值,函数返回值(返回值类型为左值引用的除外)
5.3结合例子体会左值引用和右值引用的使用
5.3.1左值
左值最大的特点是:可以取地址
int* p=new int(10);
int b=1;
const int c=b;//左值可以在赋值符号右侧
*p=10;//*p可以取地址,也是一个左值
string str("111111");
str[0];5.3.2右值
右值最大的特点是:不可以取地址
常见的像常量,临时对象,匿名对象等等
double x=1.1 , y=2.2;//这时左值,服务于下边的x+y
10;
x+y;
fmin(x,y);//是一个库函数,返回值为double类型
string("111111");
5.3.3左值引用给左值取别名
直接用即可
//结合上述左值举例
int*& ll1=p;
int& ll2=b;
int& ll3=*p;5.3.4右值引用给右值取别名
直接用即可
//结合上述右值举例
int&& rr1=10;
double&& rr2=x+y;
double&& rr3=fmin(x,y);5.3.5左值引用给右值取别名
不可以直接用
其中涉及的问题是:临时变量等右值具有常性,需要加const来修饰左值引用
const int& lr1=10;
const double& lr2=x+y;
const double& lr3=fmin(x,y);
const string& lr4=string("111111");5.3.5补:vector中push_back的实现就是例子
在实现vector时,传给push_back的参数类型是const T&
这个参数类型十分巧妙。不论是传过来左值还是右值都可以正常接收
5.3.6右值引用给左值取别名
不可以直接用
其中涉及的问题是:二者本身就冲突,必须要借助函数move,使用如move(左值)的方式来将左值转化为右值
move的作用就是传入左值,然后返回相对应的右值
int*&& rl1=move(p);
int&& rl2=move(b);
int&& rl3=move(*p);
string&& rl4=move(s);5.4他们的底层实现
我们要注意:底层汇编的实现与上层语法表达的意义有时是背离的
正如左值引用和右值引用,其实他们的底层都是指针
左值引用的汇编:

观察可以发现,汇编层面其实就是很简单的将p地址对应的值通过lea+mov给到ll1地址对应的值
右值引用的汇编:
 观察不难发现,实际上就是多了一步
观察不难发现,实际上就是多了一步
将x+y计算出来的过程 :
开了一块栈空间

其中跨度大小位50h
之后还是通过lea+mov给到rr2地址对应的值
5.4补:既然底层相同,那么move的作用相当于什么呢?
由上我们已经知道了在汇编层其实左值引用和右值引用没有冲突,那么拦截他们混用的一定是语法层
所以move几乎就是一个类型转换
例如
string&& rl4=move(s);就可以是
string&& rl4=(string&&)s;完全可以依照需求进行强转
六.右值引用的意义与移动语义
⭐6.1右值引用最核心的意义
实际上稍早一些的编译器(C++11标准运用之前),都需要避开大对象传值返回
例如杨辉三角题目中涉及到的vector<vector<int>>
因为这一缺陷被诟病已久,在C++11时提出了移动语义的概念来解决这一问题:
引用是为了减少拷贝
而移动构造配合右值引用更是可以略去传值返回的拷贝(深拷贝的类,移动构造才有意义)
略去拷贝的原理是:
右值对应的类类类型都属于临时创建的对象,不能取地址,用完就要消亡(称为“将亡值”)
而移动构造实际上就是把该对象swap一下,让他的资源不去释放而是直接利用,过程中传参为右值引用类型
如:
string(string&& str)
{
swap(str);
}6.2 有无移动构造的对比
假设这样一个场景:
在一个函数中,运行过程中创建了一个类的实例化str,之后必须传值返回这个str
①无移动构造
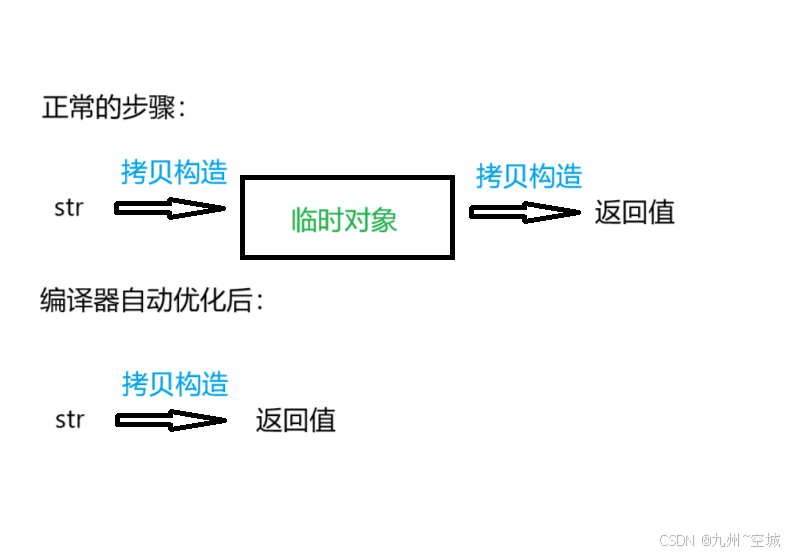
编译优化后会有一次拷贝构造的消耗
②有移动构造
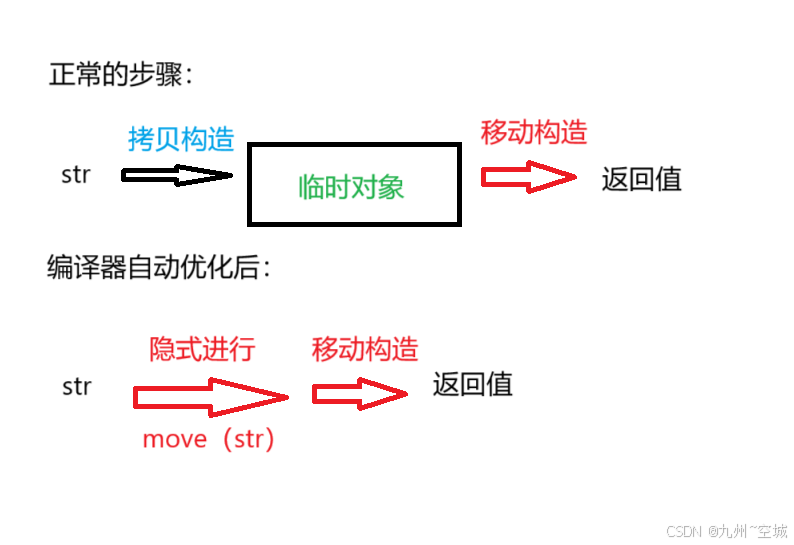
编译优化后会有0次拷贝构造的消耗
6.3 VS2022:编译器优化实现省略拷贝
假设6.2中的场景对应函数to_string,传入整形,返回字符串,在函数实现过程中会新建str来作为之后的返回值
在main函数中调用语句:
string s1=to_string(1234);具体实现过程如图示:
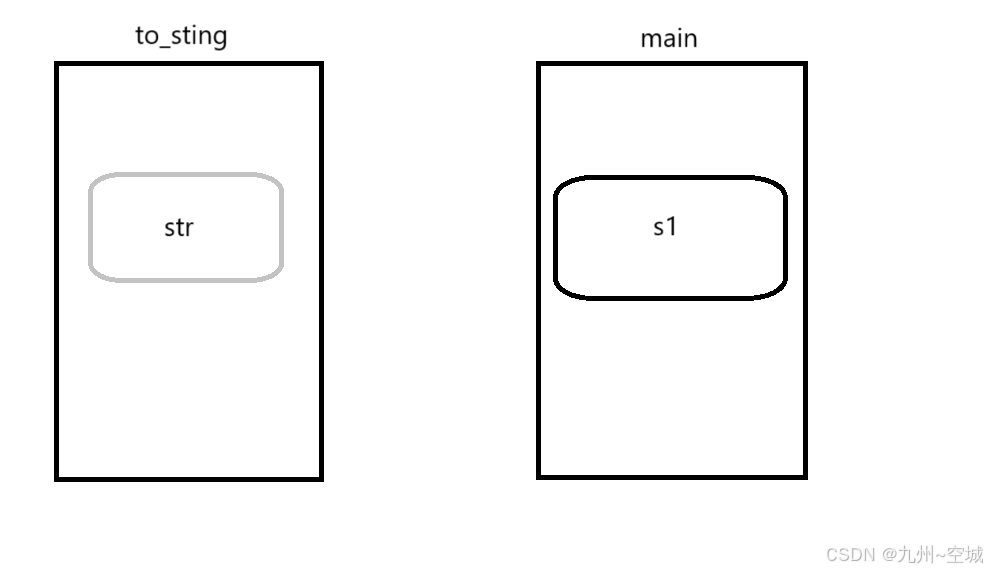
to_string函数运行过程中不会再新建str,而会直接找到main,去其中构造s1,这样以后有无移动构造都不会让传值传参有任何消耗
6.3补:在Linux中,g++有一条单独的指令可以关闭编译器优化
g++ -O0 +[.cpp文件名] -o +[可执行程序名]
6.4移动赋值
我们如果把6.3中的
string s1=to_string(1234);更改为
string s1;
s1=to_string(1234);那么还会触发编译器的自动优化吗?
答案是不会的, 为此我们需要对赋值重载函数进行添加,添加一个传右值引用的参数对应的重载,即“移动赋值”
如
string& operator=(string&& s)
{
swap(s);
return *this;//交换后还要帮助完成释放的工作
}6.5移动拷贝在一些容器的插入过程中也会起到提效的作用
如list有对应的push_back接口:传入右值引用
void push_back (value_type&& val);
具体使用如:
list<string> lt;
//情况一:先进行普通拷贝,再走拷贝构造
string s1("111");
lt.push_back(s1);
//情况二:先进行普通拷贝,再走移动拷贝
lt.push_back(string("222"));
//情况三:先进行普通拷贝,再走移动拷贝
lt.push_back("333");
//走移动拷贝,但会导致s1的资源被转移
lt.push_back(move(s1));⭐6.6右值引用正常情况下为右值的引用,那么右值引用本身的属性是什么?
是左值,因为如移动构造中,是需要通过swap来减少消耗的,而我们知道右值具有常性,不可能顺利完成swap,因此要swap必须传入左值
因为这个缘故,如果我们要模拟实现push_back传入右值引用的接口(就是移动拷贝)
必须要传入insert一个move(str),而在list的构造中又需要new一个节点......
综合来看需要若干次move,还需要理清何时move
6.7万能引用(又名引用折叠)
例如要写一个函数模板
template<class T>
void func(T&& x)
{//...}如果每次都要写一个左值版本和一个右值版本就太麻烦了
因此规定:
T&&类型参数在进行接收时
①传入T&&,即识别为T&&,右值引用
②传入T&,即识别为T&,左值引用
6.8完美转发
因为右值引用本身的属性时左值,而一次次需要时才move又太过麻烦,为此提出了“完美转发”
的概念,来实现“传入左值引用则不变,传入右值引用则更改属性为右值”
实际上,完美转发是一个类模板,
forward<T>([传入参数])
完美转发的例子:
void Func(int& x){//...}
void Func(const int& x){//...}
void Func(int&& x){//...}
void Func(const int&& x){//...}
template<class T>
void testFunc(T&& t)
{
//???
}我们希望???的位置可以帮助我们实现的是
void testFunc(int& t){Func(t);}
void testFunc(const int& t){Func(t);}
void testFunc(int&& t){Func(move(t));}
void testFunc(const int&& t){Func(move(t));}可无论填入Func(t)还是Func(move(t))都无法满足要求
因此我们要填的是:
Func(forward<T>(t))
此时,模板实例化为左值引用,保持属性传给Func
模板实例化为右值引用,转变属性回到右值再传给Func
七、增加了几个新的容器
新增的容器右4个,其中三个之前已经介绍过了,
<array>
<unordered_map>
<unordered_set>
①对于array
主要解决的是C中这个问题:
越界读检查不出,越界较大写也查不出
int a[10]={0};
cout<<a[10]<<endl;//不报错,但越界了
cout<<a[11]<<endl;//不报错,但越界了
a[15]=1;//越界较严重,写也查不出虽然对于越界的检查更加严格了,但当静态数组太大的时候容易导致栈溢出
②unordered_map和unordered_set
可以有效提高效率,详情可参考
C++中的unordered_set,unordered_map,哈希表/散列表以及哈希表的模拟实现_遍历 unorder set-优快云博客
③新的<forward_list>
他是一个单链表,只允许头插/头删(很少用,他可以的list都可以)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









