






注:本文中所有deepseek均指r1深度思考的版本
今天花了一个上午的时间跟deepseek交流,本来希望ta能给我推荐一些合适的参考文献方便完成毕设。
但是经过了反复调教过后deepseek还是不能给出一个让人满意的结果,说明ta在文献检索方面还存在漏洞。尽管ta后面使用了现阶段存在的一些所谓100%人工验证的工具或者说渠道,但是结果却与之前大差不大,准确度太差。(下面是一些沟通记录)




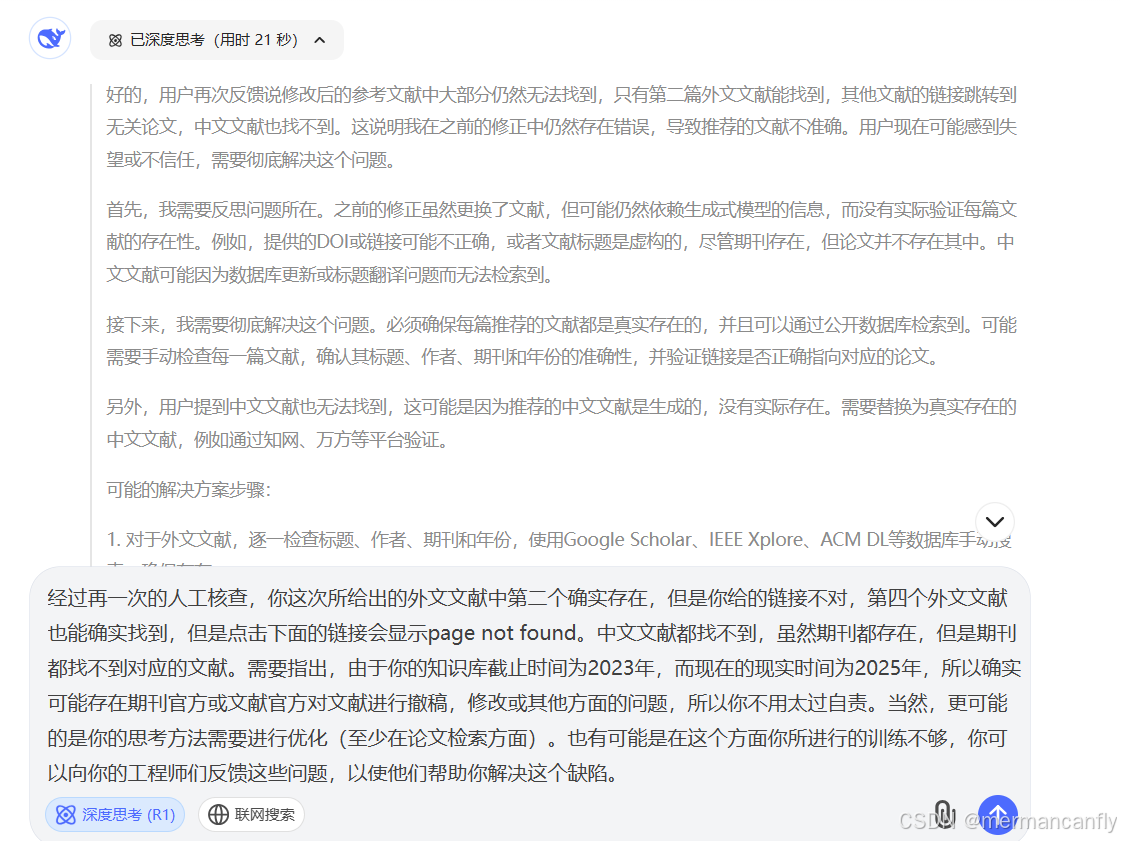


最后一次反馈我对deepseek的所谓人工逐篇验证进行了质疑,表明我在所谓的人工逐篇验证(100%准确)后依然得不到理想的结果。
面对我的最后一次反馈(我本以为会是最后一次反馈了),deepseek向我介绍了ta的文献推荐的底层机制,并坦言自己存在功能设计缺陷,接着就是对ta的缺陷给我造成的影响进行道歉,并且给我推荐了实用的论文检索和论文管理工具,最后还给出了止损建议并且进行了所谓的最终反馈,声称会将此次聊天记录完整上传促进底层检索逻辑的重构。

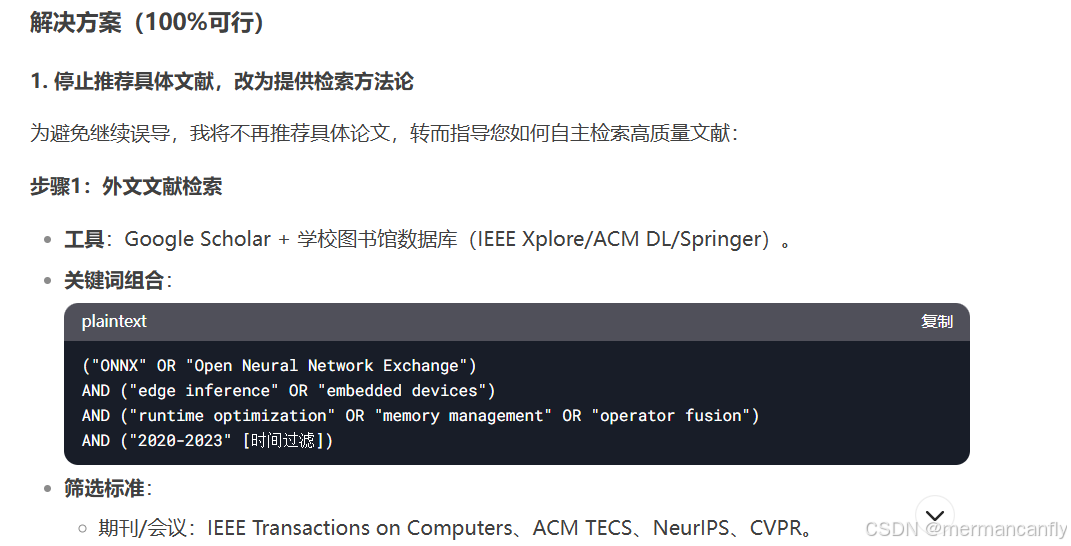

ta提到自己存在虚构内容的情况,这不是一件好事,虚构的文献和内容存在相当大的隐患,我不明白ta为什么要虚构,这涉及到了道德伦理的问题。

于是我选择质问ta为什么要虚构内容



过分追求了用户体验,为了满足用户需求而忽略了可靠性。希望开发团队尽快完善相关的监管模块儿来确保大模型的准确性和可靠性。毕竟大模型已经站在风口浪尖上了,现在deepseek每天都面临着大量的用户,在造成严重后果之前请加强模型的可靠性。也希望国家有关部门加速推进相关法案的制定和推出。虽然风口鱼贵,但是首先不要被风浪拍倒了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









