







最近领导让做一次关于spark的分享,于是专门把spark的流程看了一边,做一下记录,
也是为了练练markdown,仅此而已。
版本信息
spark version 2.3.3
jdk 1.8
idea 2019
MacBook Pro
从RDD开始
在spark中,一个action算子触发真正的计算,我们看下RDD上的count
/**
* Return the number of elements in the RDD.
*/
def count(): Long = sc.runJob(this, Utils.getIteratorSize _).sum
这就是一个一般的函数调用,有点内容的东西,就是这个方法
/**
* Counts the number of elements of an iterator using a while loop rather than calling
* [[scala.collection.Iterator#size]] because it uses a for loop, which is slightly slower
* in the current version of Scala.
*/
def getIteratorSize[T](iterator: Iterator[T]): Long = {
var count = 0L
while (iterator.hasNext) {
count += 1L
iterator.next()
}
count
}
这个方法也很简单,就是一个计数。所以RDD上的action算子没有什么难点,很容易明白。
RDD上的action算子实际触发的上SparkContext的runJob方法,下面就进入了
SparkContext
/**
* Run a job on all partitions in an RDD and return the results in an array.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @return in-memory collection with a result of the job (each collection element will contain
* a result from one partition)
*/
def runJob[T, U: ClassTag](rdd: RDD[T], func: Iterator[T] => U): Array[U] = {
runJob(rdd, func, 0 until rdd.partitions.length)
}
这个函数也没什么难点,就是函数重载调用,多了一个计算分区的参数
/**
* Run a function on a given set of partitions in an RDD and return the results as an array.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like `first()`
* @return in-memory collection with a result of the job (each collection element will contain
* a result from one partition)
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: Iterator[T] => U,
partitions: Seq[Int]): Array[U] = {
val cleanedFunc = clean(func)
runJob(rdd, (ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it), partitions)
}
需要注意下这个clean函数的功能
val cleanedFunc = clean(func)
我们传递的匿名函数,可能有外部变量,这里专门做了处理,使之可以序列化。
具体的技术细节,不明白,仔细看了一遍注释说明,这个clean的目的是明白了
有兴趣的同学可以点进去看看源码上的注释
继续调用runJob的重载方法,这里的函数参数
可能比较难理解一点的是这个参数
(ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it)
这里是我难理解的一个地方,作为对比,我们放一起看两个runJob调用
runJob(rdd, func, 0 until rdd.partitions.length)
runJob(rdd, (ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it), partitions)
上面的runJob中的参数都是实际参数
而在下面的runjob中,怎么看都觉得第二个参数
(ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it)
是一个 形 式 参 数 \color{red}{形式参数} 形式参数 ,而不是实际参数,这是一个疑惑点。
昨天想了一晚上,搞明白了,这里传递的就是一个函数,
其实在count函数中Utils.getIteratorSize也是一个函数,
我们看下参数原型
/**
* Run a function on a given set of partitions in an RDD and return the results as an array.
* The function that is run against each partition additionally takes `TaskContext` argument.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like `first()`
* @return in-memory collection with a result of the job (each collection element will contain
* a result from one partition)
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int]): Array[U] = {
val results = new Array[U](partitions.size)
runJob[T, U](rdd, func, partitions, (index, res) => results(index) = res)
results
}
参数原型是
func: (TaskContext, Iterator[T]) => U
我们实现了这个参数,只不过套用了cleanedFunc来实现,啥也没干而已
(ctx: TaskContext, it: Iterator[T]) => cleanedFunc(it)
那 么 这 个 函 数 会 在 什 么 时 候 , 什 么 地 点 被 用 到 呢 ? \color{red}{那么这个函数会在 什么时候,什么地点被用到呢?} 那么这个函数会在什么时候,什么地点被用到呢?
答案是 将来在ResultStage中会被序列化到ResultTask中,从driver端发送到executor端,开始计算任务
计算结果拉回到driver上,填充数组
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like `first()`
* @param resultHandler callback to pass each result to
*/
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
又一次clean闭包,这里的最后一句代码
rdd.doCheckpoint()
递归保存设置了检查点的RDD,可见checkpoint操作在job完成后调用。
开始转入高层调度器
DAGScheduler
/**
* Run an action job on the given RDD and pass all the results to the resultHandler function as
* they arrive.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like first()
* @param callSite where in the user program this job was called
* @param resultHandler callback to pass each result to
* @param properties scheduler properties to attach to this job, e.g. fair scheduler pool name
*
* @note Throws `Exception` when the job fails
*/
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
ThreadUtils.awaitReady(waiter.completionFuture, Duration.Inf)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
DAGScheduler的runJob方法没有难理解的地方,内部调用方法submitJob开始提交job
/**
* Submit an action job to the scheduler.
*
* @param rdd target RDD to run tasks on
* @param func a function to run on each partition of the RDD
* @param partitions set of partitions to run on; some jobs may not want to compute on all
* partitions of the target RDD, e.g. for operations like first()
* @param callSite where in the user program this job was called
* @param resultHandler callback to pass each result to
* @param properties scheduler properties to attach to this job, e.g. fair scheduler pool name
*
* @return a JobWaiter object that can be used to block until the job finishes executing
* or can be used to cancel the job.
*
* @throws IllegalArgumentException when partitions ids are illegal
*/
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
可以看到submitJob中向eventProcessLoop投递了一个JobSubmitted事件,
DAGScheduler内部的消息循环体
DAGSchedulerEventProcessLoop#doOnReceive 处理事件
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, workerLost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}
反过来再次调用DAGScheduler的内部方法handleJobSubmitted真正的job提交
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
}
handleJobSubmitted方法分成两个阶段
划分stage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
提交stage
submitStage(finalStage)
我们先整体描述一下思路
划分stage的阶段,用语言描述如下
代码先后顺序是:
1. 首先创建最后一个ResultStage时,这时需要倒数第二个ShuffleMapStage作为父Stage
2. 创建倒数第二个ShuffleMapStage时,需要倒数第三个ShuffleMapStage作为父Stage
3. 除了最后2个stage是单独创建以外,其他的stage批量存在栈中然后创建
所以,真实的创建过程如下
1. 用后进先出的stack结构,从后向前回溯shuffleDependency入栈,然后出栈创建ShuffleMapStage
2. 创建倒数第二个ShuffleMapStage
3. 创建最后一个ResultStage
Stage的提交是递归提交
1. 如果有父Stage未提交,提交父Stage
2. 如果父Stage都已经提交,提交该Stage
下面看下具体代码实现,划分stage
finalStage = createResultStage(finalRDD, func, partitions, jobId, callSite)
/**
* Create a ResultStage associated with the provided jobId.
*/
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
这个代码逻辑并不复杂,很好理解,创建父Stage,然后创建ResultStage,
因为代码调用前套关系,这个方法中的ResultStage自然就是job中最后一个Stage
倒数第二个Stage(如果ResultStage是join产生的那就是倒数第二个和倒数第三个)
/**
* Get or create the list of parent stages for a given RDD. The new Stages will be created with
* the provided firstJobId.
*/
private def getOrCreateParentStages(rdd: RDD[_], firstJobId: Int): List[Stage] = {
getShuffleDependencies(rdd).map { shuffleDep =>
getOrCreateShuffleMapStage(shuffleDep, firstJobId)
}.toList
}
代码很短,理解起来也很容易
/**
* Returns shuffle dependencies that are immediate parents of the given RDD.
*
* This function will not return more distant ancestors. For example, if C has a shuffle
* dependency on B which has a shuffle dependency on A:
*
* A <-- B <-- C
*
* calling this function with rdd C will only return the B <-- C dependency.
*
* This function is scheduler-visible for the purpose of unit testing.
*/
private[scheduler] def getShuffleDependencies(rdd: RDD[_]): HashSet[ShuffleDependency[_, _, _]] = {
val parents = new HashSet[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
val waitingForVisit = new ArrayStack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
toVisit.dependencies.foreach {
case shuffleDep: ShuffleDependency[_, _, _] =>
parents += shuffleDep
case dependency =>
waitingForVisit.push(dependency.rdd)
}
}
}
parents
}
这
里
用
到
了
s
t
a
c
k
结
构
\color{red}{这里用到了 stack 结构 }
这里用到了stack结构
NarrowDependency的rdd入栈
ShuffleDependency的rdd不入栈
因此倒数第二个ShuffleMapStage的rdd都会出入一次栈,
最终找到与ResultStage直接关联的ShuffleDependency函数结束。
在这个方法中,我们能得到更多洞察。
toVisit.dependencies
dependency.rdd
rdd中保存了dependency,这是rdd的5大属性之一
dependency中保存了rdd
对应到代码中就是
/**
* :: DeveloperApi ::
* Base class for dependencies where each partition of the child RDD depends on a small number
* of partitions of the parent RDD. Narrow dependencies allow for pipelined execution.
*/
@DeveloperApi
abstract class NarrowDependency[T](_rdd: RDD[T]) extends Dependency[T] {
/**
* Get the parent partitions for a child partition.
* @param partitionId a partition of the child RDD
* @return the partitions of the parent RDD that the child partition depends upon
*/
def getParents(partitionId: Int): Seq[Int]
override def rdd: RDD[T] = _rdd
}
NarrowDependency中用了一个rdd 方法 保存_rdd构造参数,
我原来一直认为NarrowDependency序列化的时候不会保存rdd,因为没有对应字段,
但是自己写了一个小代码跑了一下,发现确实是保存到磁盘上了
package com.wsy
import java.io.{File, FileInputStream, FileOutputStream, ObjectInputStream, ObjectOutputStream}
import org.apache.spark.internal.Logging
class Student(name: String) extends Serializable {
def getName(): String = name
}
object Test extends Logging {
def main(args: Array[String]): Unit = {
val a = new Student("lilei")
val file = new File("student.txt")
val oout = new ObjectOutputStream(new FileOutputStream(file))
oout.writeObject(a)
oout.close()
val oin = new ObjectInputStream(new FileInputStream(file))
val student = oin.readObject().asInstanceOf[Student]
oin.close()
println(student.getName())
}
}
而在
ShuffleDependency类中明确用_rdd字段保存,但是可以看到加了@transient
/**
* :: DeveloperApi ::
* Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle,
* the RDD is transient since we don't need it on the executor side.
*
* @param _rdd the parent RDD
* @param partitioner partitioner used to partition the shuffle output
* @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If not set
* explicitly then the default serializer, as specified by `spark.serializer`
* config option, will be used.
* @param keyOrdering key ordering for RDD's shuffles
* @param aggregator map/reduce-side aggregator for RDD's shuffle
* @param mapSideCombine whether to perform partial aggregation (also known as map-side combine)
*/
@DeveloperApi
class ShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag](
@transient private val _rdd: RDD[_ <: Product2[K, V]],
val partitioner: Partitioner,
val serializer: Serializer = SparkEnv.get.serializer,
val keyOrdering: Option[Ordering[K]] = None,
val aggregator: Option[Aggregator[K, V, C]] = None,
val mapSideCombine: Boolean = false)
extends Dependency[Product2[K, V]] {
override def rdd: RDD[Product2[K, V]] = _rdd.asInstanceOf[RDD[Product2[K, V]]]
private[spark] val keyClassName: String = reflect.classTag[K].runtimeClass.getName
private[spark] val valueClassName: String = reflect.classTag[V].runtimeClass.getName
// Note: It's possible that the combiner class tag is null, if the combineByKey
// methods in PairRDDFunctions are used instead of combineByKeyWithClassTag.
private[spark] val combinerClassName: Option[String] =
Option(reflect.classTag[C]).map(_.runtimeClass.getName)
val shuffleId: Int = _rdd.context.newShuffleId()
val shuffleHandle: ShuffleHandle = _rdd.context.env.shuffleManager.registerShuffle(
shuffleId, _rdd.partitions.length, this)
_rdd.sparkContext.cleaner.foreach(_.registerShuffleForCleanup(this))
}
因为@transient注解的关系,所以driver上的Dependency上持有rdd的,
但是序列化以后,发送到executor后,经过反序列化的Dependency上没有rdd的
自己写了一小段代码,模拟跑了一下,写入磁盘,然后再从磁盘读出来
发现rdd1,rdd2没有打印输出,说明没写入磁盘
package com.wsy.rdd
import java.io.{File, FileInputStream, FileOutputStream, ObjectInputStream, ObjectOutputStream}
class Rdd(val name:String,var deps:Dependency) extends Serializable{
override def toString: String = {
val str=s"Rdd(${name},${deps})"
str
}
}
abstract class Dependency(val name:String) extends Serializable {
def rdd:Rdd
}
abstract class NarrowDependency(name:String,_rdd: Rdd) extends Dependency(name ) {
override def rdd: Rdd = _rdd
}
class ShuffleDependency(name:String,@transient private val _rdd: Rdd) extends Dependency(name){
override def rdd: Rdd = _rdd
override def toString: String = {
val str=s"ShuffleDependency(${name},${_rdd})"
str
}
}
class OneToOneDependency(name:String,rdd: Rdd) extends NarrowDependency(name,rdd) {
override def toString: String = {
val str=s"OneToOneDependency(${name},${rdd})"
str
}
}
object Util {
def main(args: Array[String]): Unit = {
//rdd序列化到executor的时候,只序列化一个stage的rdd
val rdd1=new Rdd("rdd1",null)
val dep1=new OneToOneDependency("OneToOneDependency1",rdd1)
val rdd2=new Rdd("rdd2",dep1)
val dep2=new ShuffleDependency("ShuffleDependency1",rdd2)
val rdd3=new Rdd("rdd3",dep2)
val dep3=new OneToOneDependency("OneToOneDependency2",rdd3)
val rdd4=new Rdd("rdd4",dep3)
val file = new File("rdd4.txt")
val oout = new ObjectOutputStream(new FileOutputStream(file))
oout.writeObject(rdd4)
oout.close()
val oin = new ObjectInputStream(new FileInputStream(file))
val newPerson = oin.readObject()
oin.close()
println("内存中的rdd4")
println(rdd4)
println("序列化到磁盘,再次从磁盘读出来的rdd4")
println(newPerson)
}
}

这一段对目前的理解没有什么帮助,但是对于后面Task序列化很有帮助
因为我自己以前始终不明白,序列化发送task到executor到底发送的是什么东西
在后面可以看到
对于ShuffleMapTask是(rdd,shuffleDependency)
对于ResultStage 是(rdd,func)
那么我想肯定有好多人跟我有一样的困惑,这两段小代码对于理解挺有帮助
我们经常说RDD构成一个DAG,就是因为这种结构,RDD中有Dependency,
Dependency中有RDD,这样不断的延长DAG
得到了最后一个rdd的ShuffleDependency后,创建ShuffleMapStage
/**
* Gets a shuffle map stage if one exists in shuffleIdToMapStage. Otherwise, if the
* shuffle map stage doesn't already exist, this method will create the shuffle map stage in
* addition to any missing ancestor shuffle map stages.
*/
private def getOrCreateShuffleMapStage(
shuffleDep: ShuffleDependency[_, _, _],
firstJobId: Int): ShuffleMapStage = {
shuffleIdToMapStage.get(shuffleDep.shuffleId) match {
case Some(stage) =>
stage
case None =>
// Create stages for all missing ancestor shuffle dependencies.
getMissingAncestorShuffleDependencies(shuffleDep.rdd).foreach { dep =>
// Even though getMissingAncestorShuffleDependencies only returns shuffle dependencies
// that were not already in shuffleIdToMapStage, it's possible that by the time we
// get to a particular dependency in the foreach loop, it's been added to
// shuffleIdToMapStage by the stage creation process for an earlier dependency. See
// SPARK-13902 for more information.
if (!shuffleIdToMapStage.contains(dep.shuffleId)) {
createShuffleMapStage(dep, firstJobId)
}
}
// Finally, create a stage for the given shuffle dependency.
createShuffleMapStage(shuffleDep, firstJobId)
}
}
这里和createResultStage如出一辙
/**
* Create a ResultStage associated with the provided jobId.
*/
private def createResultStage(
rdd: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
jobId: Int,
callSite: CallSite): ResultStage = {
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ResultStage(id, rdd, func, partitions, parents, jobId, callSite)
stageIdToStage(id) = stage
updateJobIdStageIdMaps(jobId, stage)
stage
}
方法createResultStage中,先创建parents,后创建ResultStage
方法getOrCreateShuffleMapStage中,先创建ancestor shuffle dependencies,
后创建倒数第二个Stage,也就是倒数第一个ShuffleMapStage,
因为ResultStage是最后一个Stage
/** Find ancestor shuffle dependencies that are not registered in shuffleToMapStage yet */
private def getMissingAncestorShuffleDependencies(
rdd: RDD[_]): ArrayStack[ShuffleDependency[_, _, _]] = {
val ancestors = new ArrayStack[ShuffleDependency[_, _, _]]
val visited = new HashSet[RDD[_]]
// We are manually maintaining a stack here to prevent StackOverflowError
// caused by recursively visiting
val waitingForVisit = new ArrayStack[RDD[_]]
waitingForVisit.push(rdd)
while (waitingForVisit.nonEmpty) {
val toVisit = waitingForVisit.pop()
if (!visited(toVisit)) {
visited += toVisit
getShuffleDependencies(toVisit).foreach { shuffleDep =>
if (!shuffleIdToMapStage.contains(shuffleDep.shuffleId)) {
ancestors.push(shuffleDep)
waitingForVisit.push(shuffleDep.rdd)
} // Otherwise, the dependency and its ancestors have already been registered.
}
}
}
ancestors
}
这里用一个stack结构,从后向前回溯,一直回溯到第一个rdd,
然后把获得的所有的ShuffleDependency装入栈中
这里的ShuffleDependency是从倒数第二个ShuffleDependency开始的
倒数第一个ShuffleDependency不在其中
/**
* Creates a ShuffleMapStage that generates the given shuffle dependency's partitions. If a
* previously run stage generated the same shuffle data, this function will copy the output
* locations that are still available from the previous shuffle to avoid unnecessarily
* regenerating data.
*/
def createShuffleMapStage(shuffleDep: ShuffleDependency[_, _, _], jobId: Int): ShuffleMapStage = {
val rdd = shuffleDep.rdd
val numTasks = rdd.partitions.length
val parents = getOrCreateParentStages(rdd, jobId)
val id = nextStageId.getAndIncrement()
val stage = new ShuffleMapStage(
id, rdd, numTasks, parents, jobId, rdd.creationSite, shuffleDep, mapOutputTracker)
stageIdToStage(id) = stage
shuffleIdToMapStage(shuffleDep.shuffleId) = stage
updateJobIdStageIdMaps(jobId, stage)
if (!mapOutputTracker.containsShuffle(shuffleDep.shuffleId)) {
// Kind of ugly: need to register RDDs with the cache and map output tracker here
// since we can't do it in the RDD constructor because # of partitions is unknown
logInfo("Registering RDD " + rdd.id + " (" + rdd.getCreationSite + ")")
mapOutputTracker.registerShuffle(shuffleDep.shuffleId, rdd.partitions.length)
}
stage
}
这里又调用了getOrCreateParentStages
getOrCreateParentStages -->getOrCreateShuffleMapStage -->createShuffleMapStage --> getOrCreateParentStages
形成了一个循环
从createShuffleMapStage中,我们可以看到
一个ShuffleMapStage是由ShuffleDependency确定的
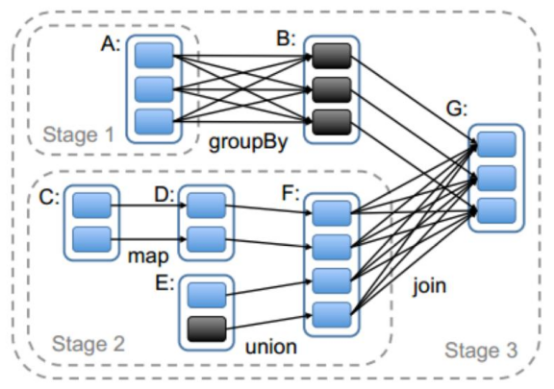
比如下图中
stage1由groupBy确定
stage2由join确定
stage3是resultStage
Stage都创建好以后,可以提交,提交一个Stage,对应了提交一组Task
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
Stage的创建虽然不是递归的,但是用栈结构,真实创建顺序是从头到尾
Stage提交是递归的,真实提交顺序同样是从头到尾
提交task的动作就包含着submitMissingTasks方法中,
这个方法代码很长,只看关心的代码
/** Called when stage's parents are available and we can now do its task. */
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// SparkListenerStageSubmitted should be posted before testing whether tasks are
// serializable. If tasks are not serializable, a SparkListenerStageCompleted event
// will be posted, which should always come after a corresponding SparkListenerStageSubmitted
// event.
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
// If there are tasks to execute, record the submission time of the stage. Otherwise,
// post the even without the submission time, which indicates that this stage was
// skipped.
if (partitionsToCompute.nonEmpty) {
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
}
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
// the serialized copy of the RDD and for each task we will deserialize it, which means each
// task gets a different copy of the RDD. This provides stronger isolation between tasks that
// might modify state of objects referenced in their closures. This is necessary in Hadoop
// where the JobConf/Configuration object is not thread-safe.
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes and partitions are both effected by the checkpoint status. We need
// this synchronization in case another concurrent job is checkpointing this RDD, so we get a
// consistent view of both variables.
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case e: Throwable =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
// Abort execution
return
}
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo(s"Submitting ${tasks.size} missing tasks from $stage (${stage.rdd}) (first 15 " +
s"tasks are for partitions ${tasks.take(15).map(_.partitionId)})")
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
stage match {
case stage: ShuffleMapStage =>
logDebug(s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})")
markMapStageJobsAsFinished(stage)
case stage : ResultStage =>
logDebug(s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})")
}
submitWaitingChildStages(stage)
}
}
在submitMissingTasks中
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
这一段获取rdd的partition数据在集群中的物理位置,是 绝对 的
后面的
@DeveloperApi
object TaskLocality extends Enumeration {
// Process local is expected to be used ONLY within TaskSetManager for now.
val PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY = Value
type TaskLocality = Value
def isAllowed(constraint: TaskLocality, condition: TaskLocality): Boolean = {
condition <= constraint
}
}
这些是数据和内存 相对 而言的优先级级别
得到数据的位置以后,序列化task
var taskBinary: Broadcast[Array[Byte]] = null
var partitions: Array[Partition] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
var taskBinaryBytes: Array[Byte] = null
// taskBinaryBytes and partitions are both effected by the checkpoint status. We need
// this synchronization in case another concurrent job is checkpointing this RDD, so we get a
// consistent view of both variables.
RDDCheckpointData.synchronized {
taskBinaryBytes = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
partitions = stage.rdd.partitions
}
从这里我们看到,ShuffleMapStage和ResultStage的task是不同的
我们的count算子的函数是在ResultStage中序列化的
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func):
并且stage.shuffleDep和stage.func地位是对等的,在Task类中可以看到
ShuffleMapTask
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
ResultTask
func(context, rdd.iterator(partition, context))
将来在executor端,计算时,
rdd的iterator方法
在ShuffleMapTask中被ShuffleWriter使用(ShuffleWriter就是从stage.shuffleDep得到的)
在ResultTask中被func函数使用
把序列化好的task广播出去,因为task是相同的,每个分区计算任务都一样
taskBinary = sc.broadcast(taskBinaryBytes)
序列化了通用的partition计算函数,剩下的就是生成含有分区信息的Task类的序列
val tasks: Seq[Task[_]] = try {
val serializedTaskMetrics = closureSerializer.serialize(stage.latestInfo.taskMetrics).array()
stage match {
case stage: ShuffleMapStage =>
stage.pendingPartitions.clear()
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = partitions(id)
stage.pendingPartitions += id
new ShuffleMapTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, properties, serializedTaskMetrics, Option(jobId),
Option(sc.applicationId), sc.applicationAttemptId)
}
case stage: ResultStage =>
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptNumber,
taskBinary, part, locs, id, properties, serializedTaskMetrics,
Option(jobId), Option(sc.applicationId), sc.applicationAttemptId)
}
}
}
我们看到一个stage生成一组task,每个task对应一个partition
这里有一点思考
后面将看到发送到executor端的不是Task,而是TaskDescription
所以在目前,Task上看不到executor信息,也就是说,
这些task无论发送到哪个executor上都可以完成计算,差别大的是计算时间
task完成封装后,这一组task打包成TaskSet交给底层调度器TaskScheduler,
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptNumber, jobId, properties))
在submitTasks方法中,taskSet又封装成TaskSetManager
TaskSchedulerImpl
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
在这个submitTasks方法中,createTaskSetManager中创建TaskSetManager
val manager = createTaskSetManager(taskSet, maxTaskFailures)
// Label as private[scheduler] to allow tests to swap in different task set managers if necessary
private[scheduler] def createTaskSetManager(
taskSet: TaskSet,
maxTaskFailures: Int): TaskSetManager = {
new TaskSetManager(this, taskSet, maxTaskFailures, blacklistTrackerOpt)
}
在TaskSetManager的构造函数中
首先根据task对应partition的数据物理位置,分门别类存入Map结构中
// Add all our tasks to the pending lists. We do this in reverse order
// of task index so that tasks with low indices get launched first.
for (i <- (0 until numTasks).reverse) {
addPendingTask(i)
}
/** Add a task to all the pending-task lists that it should be on. */
private[spark] def addPendingTask(index: Int) {
for (loc <- tasks(index).preferredLocations) {
loc match {
case e: ExecutorCacheTaskLocation =>
pendingTasksForExecutor.getOrElseUpdate(e.executorId, new ArrayBuffer) += index
case e: HDFSCacheTaskLocation =>
val exe = sched.getExecutorsAliveOnHost(loc.host)
exe match {
case Some(set) =>
for (e <- set) {
pendingTasksForExecutor.getOrElseUpdate(e, new ArrayBuffer) += index
}
logInfo(s"Pending task $index has a cached location at ${e.host} " +
", where there are executors " + set.mkString(","))
case None => logDebug(s"Pending task $index has a cached location at ${e.host} " +
", but there are no executors alive there.")
}
case _ =>
}
pendingTasksForHost.getOrElseUpdate(loc.host, new ArrayBuffer) += index
for (rack <- sched.getRackForHost(loc.host)) {
pendingTasksForRack.getOrElseUpdate(rack, new ArrayBuffer) += index
}
}
if (tasks(index).preferredLocations == Nil) {
pendingTasksWithNoPrefs += index
}
allPendingTasks += index // No point scanning this whole list to find the old task there
}
// Set of pending tasks for each executor. These collections are actually
// treated as stacks, in which new tasks are added to the end of the
// ArrayBuffer and removed from the end. This makes it faster to detect
// tasks that repeatedly fail because whenever a task failed, it is put
// back at the head of the stack. These collections may contain duplicates
// for two reasons:
// (1): Tasks are only removed lazily; when a task is launched, it remains
// in all the pending lists except the one that it was launched from.
// (2): Tasks may be re-added to these lists multiple times as a result
// of failures.
// Duplicates are handled in dequeueTaskFromList, which ensures that a
// task hasn't already started running before launching it.
private val pendingTasksForExecutor = new HashMap[String, ArrayBuffer[Int]]
// Set of pending tasks for each host. Similar to pendingTasksForExecutor,
// but at host level.
private val pendingTasksForHost = new HashMap[String, ArrayBuffer[Int]]
// Set of pending tasks for each rack -- similar to the above.
private val pendingTasksForRack = new HashMap[String, ArrayBuffer[Int]]
// Set containing pending tasks with no locality preferences.
private[scheduler] var pendingTasksWithNoPrefs = new ArrayBuffer[Int]
// Set containing all pending tasks (also used as a stack, as above).
private val allPendingTasks = new ArrayBuffer[Int]
这样每个task的数据在什么位置就很清楚了
然后计算task的locality levels
/**
* Track the set of locality levels which are valid given the tasks locality preferences and
* the set of currently available executors. This is updated as executors are added and removed.
* This allows a performance optimization, of skipping levels that aren't relevant (eg., skip
* PROCESS_LOCAL if no tasks could be run PROCESS_LOCAL for the current set of executors).
*/
private[scheduler] var myLocalityLevels = computeValidLocalityLevels()
/**
* Compute the locality levels used in this TaskSet. Assumes that all tasks have already been
* added to queues using addPendingTask.
*
*/
private def computeValidLocalityLevels(): Array[TaskLocality.TaskLocality] = {
import TaskLocality.{PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY}
val levels = new ArrayBuffer[TaskLocality.TaskLocality]
if (!pendingTasksForExecutor.isEmpty &&
pendingTasksForExecutor.keySet.exists(sched.isExecutorAlive(_))) {
levels += PROCESS_LOCAL
}
if (!pendingTasksForHost.isEmpty &&
pendingTasksForHost.keySet.exists(sched.hasExecutorsAliveOnHost(_))) {
levels += NODE_LOCAL
}
if (!pendingTasksWithNoPrefs.isEmpty) {
levels += NO_PREF
}
if (!pendingTasksForRack.isEmpty &&
pendingTasksForRack.keySet.exists(sched.hasHostAliveOnRack(_))) {
levels += RACK_LOCAL
}
levels += ANY
logDebug("Valid locality levels for " + taskSet + ": " + levels.mkString(", "))
levels.toArray
}
从代码中可以看到,task的 locality levels 是根据当前所有计算资源和task的数据的物理位置匹配
的结果
这里说一点,我自己的疑惑,以前我一直认为 locality levels 是
task的数据物理位置和当前可用的计算资源的匹配结果
今天看代码,不是当前可用计算资源,是全部计算资源
比如一个数据在节点A上的executor中,但是节点A上已经没有cpu可用了,
那么partition对应的task的locality level依然是PROCESS_LOCAL
这样的话,locality levels 的计算简单很多
初始化好TaskSetManager之后,,提交到调度树schedulableBuilder中
这个调度结构是在sparkContext初始化的时候初始化的
这个submitTasks方法只是把task提交到了TaskScheduler的调度池中,并没有真正submit
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
如果运行spark on yarn的话,
这个backend其实是YarnClusterSchedulerBackend,
我们看下CoarseGrainedSchedulerBackend类中的这个reviveOffers方法,给driver发送一个消息
DriverEndpoint
backend.reviveOffers()
override def reviveOffers() {
driverEndpoint.send(ReviveOffers)
}
driver接收到消息以后
case ReviveOffers =>
makeOffers()
调用DriverEndpoint类中的makeOffers方法
// Make fake resource offers on all executors
private def makeOffers() {
// Make sure no executor is killed while some task is launching on it
val taskDescs = CoarseGrainedSchedulerBackend.this.synchronized {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map {
case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toIndexedSeq
scheduler.resourceOffers(workOffers)
}
if (!taskDescs.isEmpty) {
launchTasks(taskDescs)
}
}
决策哪个task发送到哪个executor,在下面代码中
scheduler.resourceOffers(workOffers)
代码中的workOffers是driver拿到的全部计算资源中剩余executor里的可用资源逻辑抽象表示,
scheduler是TaskSchedulerImpl
TaskSchedulerImpl.submitTasks -->
CoarseGrainedSchedulerBackend#reviveOffers -->
CoarseGrainedSchedulerBackend.DriverEndpoint#makeOffers–>
CoarseGrainedSchedulerBackend.DriverEndpoint#launchTasks
整个调用逻辑TaskSchedulerImpl到driver,并且driver上调用了TaskSchedulerImpl的方法
因为资源并不在TaskSchedulerImpl手中,而是在driver手中,TaskSchedulerImpl只管调度
/**
* Called by cluster manager to offer resources on slaves. We respond by asking our active task
* sets for tasks in order of priority. We fill each node with tasks in a round-robin manner so
* that tasks are balanced across the cluster.
*/
def resourceOffers(offers: IndexedSeq[WorkerOffer]): Seq[Seq[TaskDescription]] = synchronized {
// Mark each slave as alive and remember its hostname
// Also track if new executor is added
var newExecAvail = false
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// Before making any offers, remove any nodes from the blacklist whose blacklist has expired. Do
// this here to avoid a separate thread and added synchronization overhead, and also because
// updating the blacklist is only relevant when task offers are being made.
blacklistTrackerOpt.foreach(_.applyBlacklistTimeout())
val filteredOffers = blacklistTrackerOpt.map { blacklistTracker =>
offers.filter { offer =>
!blacklistTracker.isNodeBlacklisted(offer.host) &&
!blacklistTracker.isExecutorBlacklisted(offer.executorId)
}
}.getOrElse(offers)
val shuffledOffers = shuffleOffers(filteredOffers)
// Build a list of tasks to assign to each worker.
val tasks = shuffledOffers.map(o => new ArrayBuffer[TaskDescription](o.cores / CPUS_PER_TASK))
val availableCpus = shuffledOffers.map(o => o.cores).toArray
val sortedTaskSets = rootPool.getSortedTaskSetQueue
for (taskSet <- sortedTaskSets) {
logDebug("parentName: %s, name: %s, runningTasks: %s".format(
taskSet.parent.name, taskSet.name, taskSet.runningTasks))
if (newExecAvail) {
taskSet.executorAdded()
}
}
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
if (tasks.size > 0) {
hasLaunchedTask = true
}
return tasks
}
在这个方法中,重点代码如下
首先更新
for (o <- offers) {
if (!hostToExecutors.contains(o.host)) {
hostToExecutors(o.host) = new HashSet[String]()
}
if (!executorIdToRunningTaskIds.contains(o.executorId)) {
hostToExecutors(o.host) += o.executorId
executorAdded(o.executorId, o.host)
executorIdToHost(o.executorId) = o.host
executorIdToRunningTaskIds(o.executorId) = HashSet[Long]()
newExecAvail = true
}
for (rack <- getRackForHost(o.host)) {
hostsByRack.getOrElseUpdate(rack, new HashSet[String]()) += o.host
}
}
// IDs of the tasks running on each executor
private val executorIdToRunningTaskIds = new HashMap[String, HashSet[Long]]
// The set of executors we have on each host; this is used to compute hostsAlive, which
// in turn is used to decide when we can attain data locality on a given host
protected val hostToExecutors = new HashMap[String, HashSet[String]]
protected val hostsByRack = new HashMap[String, HashSet[String]]
protected val executorIdToHost = new HashMap[String, String]
资源在driver中,TaskSchedulerImpl中的这些Map一开始都是空的
在调度task的过程中慢慢更新,用于计算task的 locality levels
// Take each TaskSet in our scheduling order, and then offer it each node in increasing order
// of locality levels so that it gets a chance to launch local tasks on all of them.
// NOTE: the preferredLocality order: PROCESS_LOCAL, NODE_LOCAL, NO_PREF, RACK_LOCAL, ANY
for (taskSet <- sortedTaskSets) {
var launchedAnyTask = false
var launchedTaskAtCurrentMaxLocality = false
for (currentMaxLocality <- taskSet.myLocalityLevels) {
do {
launchedTaskAtCurrentMaxLocality = resourceOfferSingleTaskSet(
taskSet, currentMaxLocality, shuffledOffers, availableCpus, tasks)
launchedAnyTask |= launchedTaskAtCurrentMaxLocality
} while (launchedTaskAtCurrentMaxLocality)
}
if (!launchedAnyTask) {
taskSet.abortIfCompletelyBlacklisted(hostToExecutors)
}
}
调度池中的taskSet一般是FIFO
我们现在的代码中,计算资源是有的,数据物理位置也是有的
现在就是决策分配哪个task到哪个executor的时候了
我们可以思考一下
是一个task决定发送到哪个executor,还是一个executor决定哪个task在其上运行?
或者说,是task挑选executor,还是executor挑选task?
哪个是主动,哪个是被动?
这个问题很值得思考。
因为一般我们都说发送task到executor,但是到底是怎么样的,我自己也没思考过
这里边是2层循环,taskset一层循环,myLocalityLevels一层循环
private def resourceOfferSingleTaskSet(
taskSet: TaskSetManager,
maxLocality: TaskLocality,
shuffledOffers: Seq[WorkerOffer],
availableCpus: Array[Int],
tasks: IndexedSeq[ArrayBuffer[TaskDescription]]) : Boolean = {
var launchedTask = false
// nodes and executors that are blacklisted for the entire application have already been
// filtered out by this point
for (i <- 0 until shuffledOffers.size) {
val execId = shuffledOffers(i).executorId
val host = shuffledOffers(i).host
if (availableCpus(i) >= CPUS_PER_TASK) {
try {
for (task <- taskSet.resourceOffer(execId, host, maxLocality)) {
tasks(i) += task
val tid = task.taskId
taskIdToTaskSetManager.put(tid, taskSet)
taskIdToExecutorId(tid) = execId
executorIdToRunningTaskIds(execId).add(tid)
availableCpus(i) -= CPUS_PER_TASK
assert(availableCpus(i) >= 0)
launchedTask = true
}
} catch {
case e: TaskNotSerializableException =>
logError(s"Resource offer failed, task set ${taskSet.name} was not serializable")
// Do not offer resources for this task, but don't throw an error to allow other
// task sets to be submitted.
return launchedTask
}
}
}
return launchedTask
}
对于特定的一个LocalityLevels,在shuffledOffers遍历
for (i <- 0 until shuffledOffers.size)
在一个具体的execId上,taskSet寻找满足此本地性的task
taskSet.resourceOffer(execId, host, maxLocality)
这个过程很复杂,我自己目前没看懂,就不展开了,但是功能应该是很明确
我自己的观察, 既不是单纯的executor挑task,也不是task挑executor
而是在满足本地性要求的前提下,executor挑选task,
在这个过程中,executor选定Task之后,Task被序列化封装到TaskDescription中
我们看下一共序列化了几次
(stage.rdd, stage.func)或者(stage.rdd, stage.shuffleDep)序列化封装到Task中
Task序列化封装到TaskDescription中
TaskDescription序列化发送到executor
在driver端,一切都搞定以后,就可以提交到executor了
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = TaskDescription.encode(task)
if (serializedTask.limit() >= maxRpcMessageSize) {
Option(scheduler.taskIdToTaskSetManager.get(task.taskId)).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit(), maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logDebug(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
提交这个动作涉及到与executor端通信,所以是driver启动
CoarseGrainedSchedulerBackend.DriverEndpoint#launchTasks
任务就发送到了Executor上
Executor
org.apache.spark.executor.CoarseGrainedExecutorBackend#receive
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = TaskDescription.decode(data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskDesc)
}
接收到TaskDescription以后转交给Executor类的launchTask方法
def launchTask(context: ExecutorBackend, taskDescription: TaskDescription): Unit = {
val tr = new TaskRunner(context, taskDescription)
runningTasks.put(taskDescription.taskId, tr)
threadPool.execute(tr)
}
TaskRunner是一个Runnable,这个线程随着threadPool的调用,开始执行自己的run方法
这个run方法代码较长,这里不贴了,有兴趣可以看
org.apache.spark.executor.Executor.TaskRunner#run
我们看下关键代码
反序列化出Task类
task = ser.deserialize[Task[Any]](
taskDescription.serializedTask, Thread.currentThread.getContextClassLoader)
task执行自己的计算任务
val value = try {
val res = task.run(
taskAttemptId = taskId,
attemptNumber = taskDescription.attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
}
task.run运行Task子类实现的runTask(context)方法
/**
* Called by [[org.apache.spark.executor.Executor]] to run this task.
*
* @param taskAttemptId an identifier for this task attempt that is unique within a SparkContext.
* @param attemptNumber how many times this task has been attempted (0 for the first attempt)
* @return the result of the task along with updates of Accumulators.
*/
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem): T = {
SparkEnv.get.blockManager.registerTask(taskAttemptId)
context = new TaskContextImpl(
stageId,
stageAttemptId, // stageAttemptId and stageAttemptNumber are semantically equal
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
localProperties,
metricsSystem,
metrics)
TaskContext.setTaskContext(context)
taskThread = Thread.currentThread()
if (_reasonIfKilled != null) {
kill(interruptThread = false, _reasonIfKilled)
}
new CallerContext(
"TASK",
SparkEnv.get.conf.get(APP_CALLER_CONTEXT),
appId,
appAttemptId,
jobId,
Option(stageId),
Option(stageAttemptId),
Option(taskAttemptId),
Option(attemptNumber)).setCurrentContext()
try {
runTask(context)
} catch {
case e: Throwable =>
// Catch all errors; run task failure callbacks, and rethrow the exception.
try {
context.markTaskFailed(e)
} catch {
case t: Throwable =>
e.addSuppressed(t)
}
context.markTaskCompleted(Some(e))
throw e
} finally {
try {
// Call the task completion callbacks. If "markTaskCompleted" is called twice, the second
// one is no-op.
context.markTaskCompleted(None)
} finally {
try {
Utils.tryLogNonFatalError {
// Release memory used by this thread for unrolling blocks
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(MemoryMode.ON_HEAP)
SparkEnv.get.blockManager.memoryStore.releaseUnrollMemoryForThisTask(
MemoryMode.OFF_HEAP)
// Notify any tasks waiting for execution memory to be freed to wake up and try to
// acquire memory again. This makes impossible the scenario where a task sleeps forever
// because there are no other tasks left to notify it. Since this is safe to do but may
// not be strictly necessary, we should revisit whether we can remove this in the
// future.
val memoryManager = SparkEnv.get.memoryManager
memoryManager.synchronized { memoryManager.notifyAll() }
}
} finally {
// Though we unset the ThreadLocal here, the context member variable itself is still
// queried directly in the TaskRunner to check for FetchFailedExceptions.
TaskContext.unset()
}
}
}
}
我们分别看下ShuffleMapTask和ResultTask这两个Task子类的实现
ShuffleMapTask
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
几行关键代码
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])]
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
这里我们看到dep的作用是得到shuffleManager,rdd的作用是得到iterator
这里反序列化出来rdd,我们看到的只有一个
其实整个stage的rdd都被反序列化出来了,记住是整个stage
并且除了第一个ShuffleMapStage之外,其他的stage的第一个rdd一般是ShuffledRDD
ResultTask
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
func(context, rdd.iterator(partition, context))
}
这个里边关键代码的理解就比ShuffleMapTask简单多了
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)]
func(context, rdd.iterator(partition, context))
那么到此为止,整个job的流程就大致结束了,内部关于Shuffle的细节还需要一次思考。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









