



一. 引言
大型语言模型(Large Language Models,简称LLM)如GPT-4、Claude和LLaMA等近年来取得了突破性进展,能够生成流畅自然的文本、回答复杂问题、甚至编写代码。但这些模型究竟是如何理解人类语言的?它们如何表示和处理单词?本文将深入探讨大模型的基础机制——词嵌入向量,揭示AI是如何"理解"文字的。
二. 从符号到向量:语言表示的基础
2.1 词向量的概念
在传统自然语言处理中,单词通常被表示为独热编码(One-Hot Encoding)——一个只有一个元素为1,其余都为0的稀疏向量。例如,在一个有10000个单词的词汇表中,"苹果"这个词可能被表示为一个长度为10000的向量,其中只有第345位是1,其余都是0。
该方法虽然简单,并且适用于任意文本数据,但存在很多严重问题:
- 维度爆炸。由于每一个单词的词向量的维度都等于词汇表的长度,对于大规模语料训练的情况,词汇表将异常庞大,使模型的计算量剧增造成维数灾难。
- 矩阵稀疏。有用的信息零散地分布在大量数据中。这会导致结果异常稀疏,使其难以进行优化,对于神经网络来说尤其如此。
- 向量正交。由于两两向量正交,无法表达两词向量之间的其他信息,造成了“语义鸿沟”的 现象,此特点对于NLP任务是相当致命的。
2.2 词嵌入向量的基本原理
词嵌入向量(Word Embedding)解决了上述问题,它是"通过将离散空间向连续空间映射后得到的词向量"。每个单词被映射到一个低维度(通常为几百维)的稠密向量空间中,这些向量捕捉了单词的语义和句法特性。
词嵌入向量的核心优势在于:语义上相似的词在向量空间中的距离也相近。这种特性使得模型能够理解词与词之间的关系,从而更好地处理自然语言。
三. 词嵌入向量的实现方式
3.1 Word2Vec:CBOW与Skip-gram
Word2Vec是一种基于浅层神经网络的算法,输入是文本语料库,输出是一组词向量。一个著名的例子是:
vector(‘国王’) - vector(‘男人’) + vector(‘女人’) ≈ vector(‘女王’)。
这表明模型能捕捉到类比关系:“国王之于男人,如同女王之于女人”。
- CBOW (Continuous Bag of Words):使用上下文预测目标词。给定一个词的上下文(周围的词),预测这个词是什么。
- Skip-gram:与CBOW相反,使用目标词预测上下文。给定一个词,预测它周围可能出现的词。
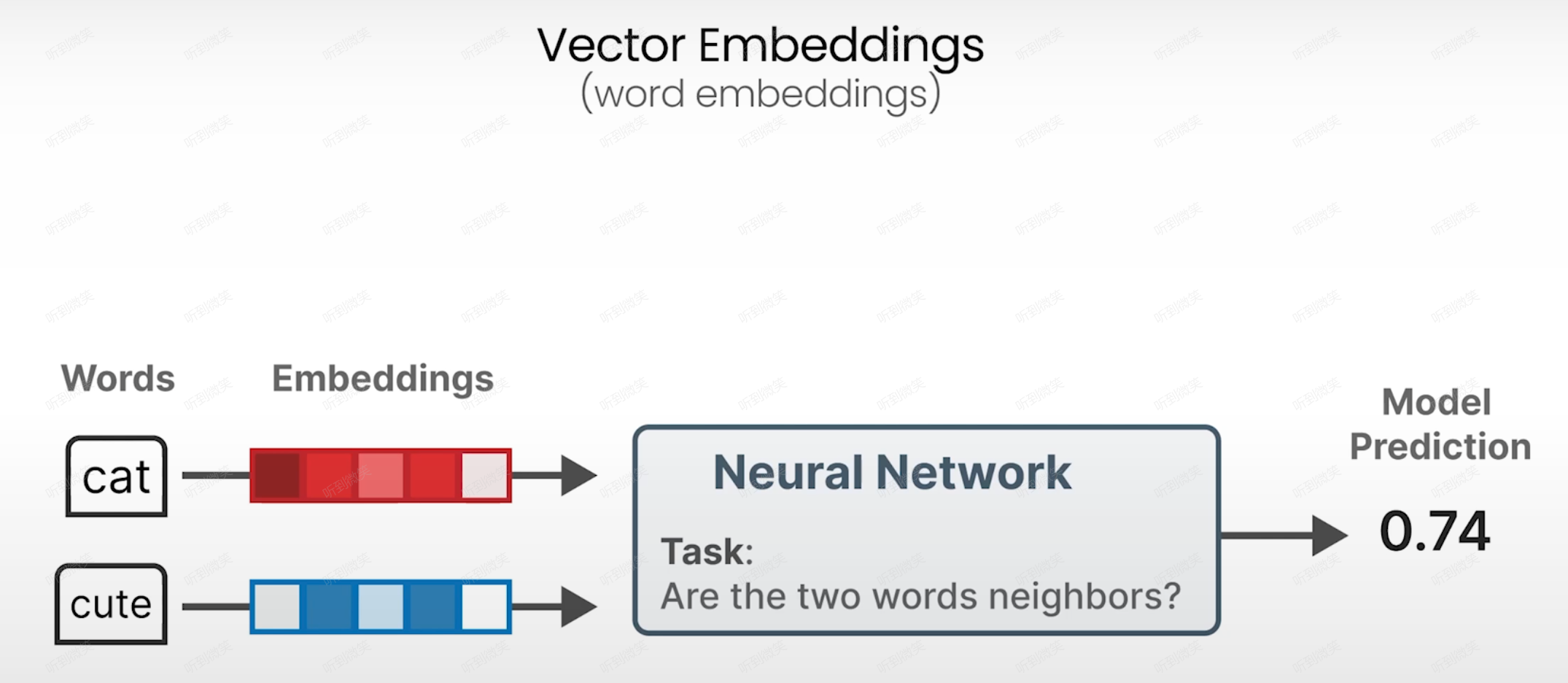
3.1.1 CBOW:上下文当 “线索”,猜中间的 “目标词”
CBOW 的 “Continuous Bag of Words” 里,“Bag(袋子)” 是关键:把上下文的词装进 “袋子” 里,不考虑词的顺序(比如 “今天 很” 和 “很 今天” 对 CBOW 来说完全一样),只看 “有哪些词”,再用这些词的集合预测中间词。简化步骤如下:
步骤一:给上下文词 “编码”
计算机不认识文字,先把每个上下文词转换成 “独一无二的身份证”——one-hot 向量(比如 “今天”= [0,1,0,0,…],“很”= [0,0,1,0,…],向量长度 = 词汇表总词数)。
步骤二:把上下文词的 “身份证” 变成 “浓缩版特征”
将所有上下文词的 one-hot 向量,输入到一个简单的神经网络隐藏层,做 “平均池化”(通俗说:把多个向量合并成一个,保留共同特征),得到 “上下文整体特征向量”(这一步就是在学习 “上下文组合起来代表什么”)。
步骤三:根据特征向量 “猜目标词”
把 “上下文整体特征向量” 输入输出层,输出层会计算 “词汇表中每个词是目标词的概率”,概率最高的词就是模型的预测结果。
举个例子:
-
输入上下文(窗口大小 = 3):[我, 喜欢] + [自然语言处理](中间空出目标词位置)
-
模型要做的:根据 “我” 和 “喜欢”“自然语言处理” 这三个上下文词,猜中间的词是什么?
-
可能的预测结果:也(完整句子:我 也 喜欢 自然语言处理)、很(我 很 喜欢 自然语言处理)
-
训练过程:如果实际目标词是 “也”,模型会调整参数,让下次再遇到这组上下文时,“也” 的概率更高。
3.1.2 Skip-gram:目标词当 “主角”,猜周围的 “配角”(上下文)
和 CBOW 完全相反:Skip-gram 是 “给定一个目标词,预测它周围可能出现的多个上下文词”。它不纠结 “上下文的顺序”,只关注 “目标词和哪些词经常一起出现”。简化步骤如下:
步骤一:给目标词 “编码”
把目标词转换成 one-hot 向量(比如目标词 “咖啡”= [0,0,0,1,…])。
步骤二:把目标词的 “身份证” 变成 “浓缩版特征”
将目标词的 one-hot 向量输入隐藏层,直接转换成 “目标词的特征向量”(这就是我们最终想要的 “词向量” 的雏形)。
步骤三:根据目标词特征,猜多个上下文词
把 “目标词特征向量” 输入输出层,输出层会同时计算 “词汇表中每个词是该目标词上下文的概率”,选出概率最高的 k 个词(k = 窗口大小 - 1),作为预测的上下文。
举个例子:
-
输入目标词:咖啡
-
模型要做的:猜 “咖啡” 周围最可能出现哪些词?
-
可能的预测结果:喝(喝 咖啡)、热(热 咖啡)、早晨(早晨 喝 咖啡)、提神(咖啡 提神)
-
训练过程:如果实际上下文是 “早晨”“喝”“热”,模型会调整参数,让下次再输入 “咖啡” 时,这三个词的概率更高。
3.1.3 CBOW vs Skip-gram 区别
| 对比维度 | CBOW(连续词袋) | Skip-gram(跳字模型) |
|---|---|---|
| 核心逻辑 | 上下文 → 目标词(多输入→单输出) | 目标词 → 上下文(单输入→多输出) |
| 对词序的态度 | 不敏感(只看词的集合) | 不敏感(只看词的关联) |
| 训练效率 | 快(一次预测 1 个目标词) | 慢(一次预测多个上下文词) |
| 适合场景 | 高频词、常用词(比如 “的”“是”) | 低频词、生僻词(比如 “国王”“女王”) |
| 语义捕捉能力 | 一般(侧重常见搭配) | 更强(侧重语义关联,比如 “国王 - 男人 = 女王 - 女人”) |
3.2 GloVe:全局统计信息的利用
GloVe (Global Vectors for Word Representation) 是由斯坦福大学开发的另一种流行的词嵌入模型。与Word2Vec不同,GloVe结合了全局矩阵分解和局部上下文窗口方法的优点。
GloVe基于共现矩阵——记录每个单词与其上下文词的共现频率,然后通过矩阵分解技术学习词向量。这使得GloVe能够更好地捕捉全局统计信息,在某些任务上表现优于Word2Vec。
3.3 FastText:子词单元的创新
FastText是Facebook AI Research开发的一种改进型词嵌入模型。它的主要创新在于将单词分解为子词(subword)单元,通常是字符n-gram。
例如,单词"apple"的3-gram表示为:<ap, app, ppl, ple, le>
FastText的优势:
- 能够处理词汇表外的词(OOV问题)
- 对拼写错误有一定的容忍度
- 特别适合处理形态丰富的语言(如芬兰语、土耳其语等)
四. 现代大模型中的词嵌入
4.1 上下文相关的词嵌入
在传统词嵌入模型(如Word2Vec)中,每个词只有一个固定的向量表示,无法区分多义词的不同含义。例如,"苹果"在"我喜欢吃苹果"和"苹果公司发布新产品"中含义不同。
现代大模型采用了上下文相关的词嵌入技术,根据词出现的上下文生成不同的表示:
- “我喜欢吃苹果” → vector(“苹果”) 表示水果意义
- “苹果公司发布新产品” → vector(“苹果”) 表示公司意义
这种动态表示极大地提高了模型理解语言的能力。
4.2 Transformer架构中的嵌入
在Transformer架构(现代大模型的基础)中,词嵌入通常包含三个部分:
- 词嵌入 (Token Embeddings):单词本身的向量表示
- 位置嵌入 (Positional Embeddings):表示单词在序列中的位置
- 段嵌入 (Segment Embeddings):用于区分不同段落或句子(主要用于BERT等模型)
这三种嵌入向量相加后,形成了输入Transformer各层的初始表示。位置嵌入特别重要,因为它使模型能够了解单词的顺序,这对于理解语言至关重要。
五. 词嵌入可视化
5.1 词向量空间可视化
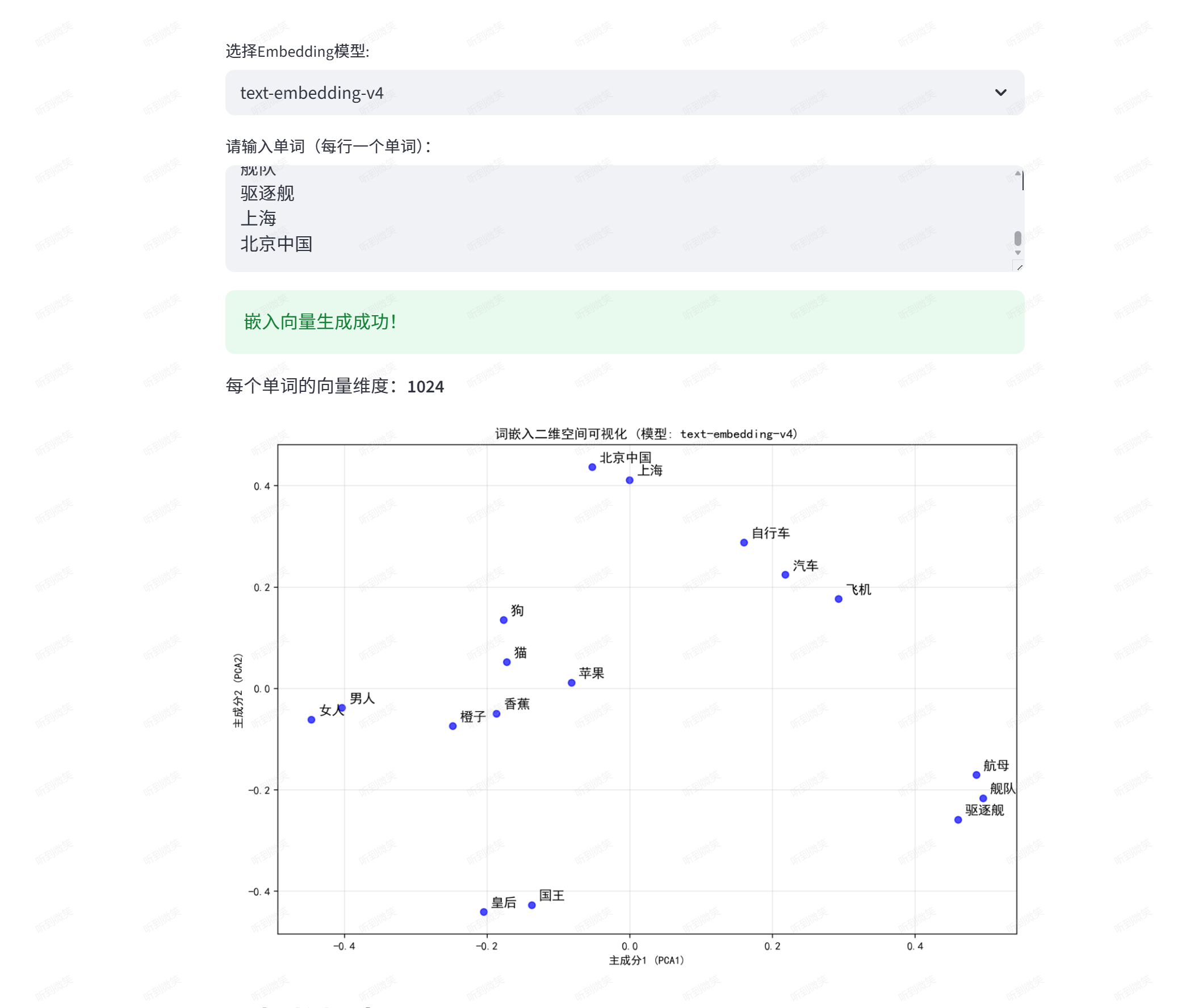
我们可以使用阿里百炼平台的embedding模型,输入一些单词,看看它们在二维空间里的分布:
第一步:引入依赖
streamlit>=1.28.0
pandas>=1.5.0
scikit-learn>=1.3.0
matplotlib>=3.7.0
python-dotenv>=1.0.0
requests>=2.31.0
numpy>=1.24.0
执行下列命令安装依赖:
pip install -r requirements.txt
第二步:编写代码
这段代码调用阿里百炼平台的 text-embedding 模型获取用户输入单词的词向量,通过 PCA 降维后使用 Matplotlib 绘制二维散点图,并借助 Streamlit 构建交互式界面展示词嵌入的空间分布及语义相似度分析。
import streamlit as st
import pandas as pd
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib
import os
from dotenv import load_dotenv
import requests
import json
# 加载环境变量
load_dotenv()
# 设置中文字体(Windows系统)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 'SimHei' 是黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 阿里百炼平台API配置
DASHSCOPE_API_KEY = os.getenv('DASHSCOPE_API_KEY')
def get_word_embeddings(words, model="text-embedding-v4"):
"""
使用阿里百炼平台的embedding模型获取词向量
Args:
words: 单词列表
model: embedding模型名称,默认使用text-embedding-v4
Returns:
词向量列表
"""
if not DASHSCOPE_API_KEY:
st.error("请设置DASHSCOPE_API_KEY环境变量")
return []
url = "https://dashscope.aliyuncs.com/api/v1/services/embeddings/text-embedding/text-embedding"
headers = {
'Authorization': f'Bearer {DASHSCOPE_API_KEY}',
'Content-Type': 'application/json'
}
embeddings = []
for word in words:
data = {
"model": model,
"input": {
"texts": [word]
},
"parameters": {
"text_type": "document"
}
}
try:
response = requests.post(url, headers=headers, json=data)
if response.status_code == 200:
result = response.json()
if "output" in result and "embeddings" in result["output"]:
embedding = result["output"]["embeddings"][0]["embedding"]
embeddings.append(embedding)
else:
st.error(f"API返回格式错误: {result}")
return []
else:
st.error(f"API请求失败,状态码: {response.status_code}, 错误信息: {response.text}")
return []
except Exception as e:
st.error(f"获取词向量时出错: {str(e)}")
return []
return embeddings
def main():
# 主界面
st.title("🧠 阿里百炼词嵌入向量空间可视化")
st.write("使用阿里百炼平台的embedding模型,输入一些单词,看看它们在二维空间里的分布!")
# 模型选择
model_options = ["text-embedding-v4", "text-embedding-v3", "text-embedding-v2"]
selected_model = st.selectbox("选择Embedding模型:", model_options)
# 文本输入
user_input = st.text_area(
"请输入单词(每行一个单词):",
"国王\n皇后\n男人\n女人\n猫\n狗\n苹果\n橙子\n香蕉\n汽车\n自行车\n飞机"
)
if user_input:
words = [w.strip() for w in user_input.split("\n") if w.strip()]
if len(words) < 2:
st.warning("请输入至少两个单词!")
else:
with st.spinner("正在使用阿里百炼平台生成词嵌入向量..."):
embeddings = get_word_embeddings(words, model=selected_model)
if embeddings:
st.success("嵌入向量生成成功!")
st.write(f"每个单词的向量维度:**{len(embeddings[0])}**")
# 用 PCA 降到 2D
pca = PCA(n_components=2)
reduced = pca.fit_transform(embeddings)
# 转成 DataFrame
df = pd.DataFrame(reduced, columns=["x", "y"])
df["word"] = words
# 画出散点图
fig, ax = plt.subplots(figsize=(12, 8))
scatter = ax.scatter(df["x"], df["y"], color="blue", alpha=0.7)
# 在点旁边标注单词
for i, word in enumerate(df["word"]):
ax.text(df["x"][i]+0.01, df["y"][i]+0.01, word, fontsize=12)
ax.set_title(f"词嵌入二维空间可视化 (模型: {selected_model})")
ax.set_xlabel("主成分1 (PCA1)")
ax.set_ylabel("主成分2 (PCA2)")
ax.grid(True, alpha=0.3)
st.pyplot(fig)
# 显示数据表格
st.subheader("坐标数据表")
st.dataframe(df)
# 图的解释
st.subheader("图表解释 🧠")
st.markdown(
f"""
- 每个点代表一个单词在嵌入空间中的位置。
- **相近的单词**,在二维平面上会靠得更近,表示语义相似。
- 方向和距离代表潜在的语义关系,比如"国王-男人+女人≈皇后"。
- 注意:因为是降维展示,实际高维特征被简化了,但依然可以直观感知单词间的语义结构。
- 本示例使用阿里百炼平台的 **{selected_model}** 模型生成词向量。
"""
)
# 添加相似度分析
st.subheader("语义相似度分析")
selected_words = st.multiselect("选择两个单词计算相似度:", words)
if len(selected_words) == 2:
idx1, idx2 = words.index(selected_words[0]), words.index(selected_words[1])
vec1, vec2 = embeddings[idx1], embeddings[idx2]
# 计算余弦相似度
import numpy as np
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
similarity = dot_product / (norm1 * norm2)
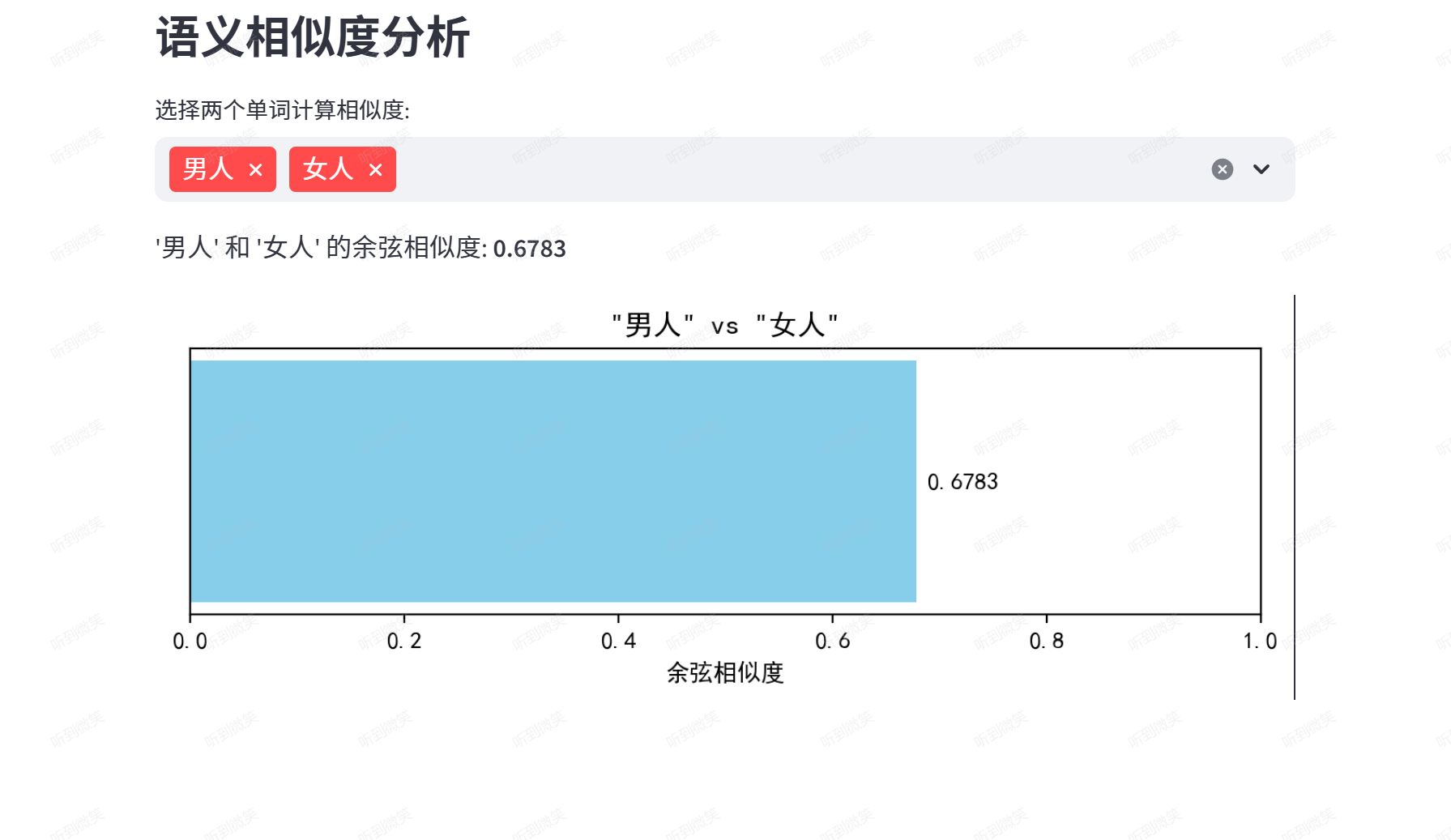
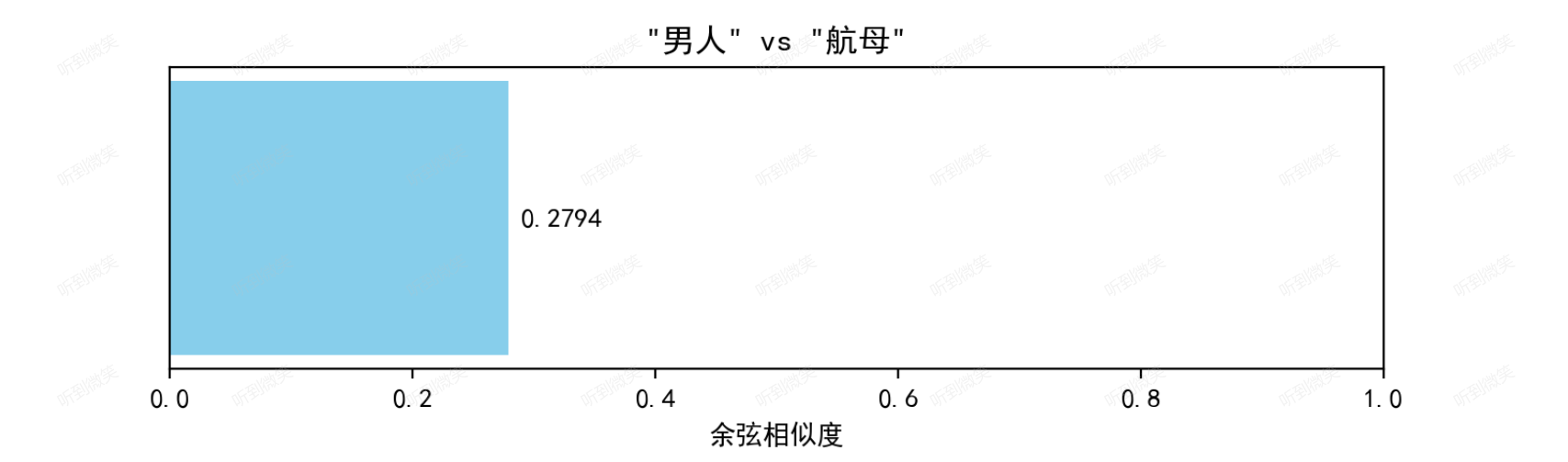
st.write(f"'{selected_words[0]}' 和 '{selected_words[1]}' 的余弦相似度: **{similarity:.4f}**")
# 可视化相似度
fig2, ax2 = plt.subplots(figsize=(8, 2))
ax2.barh([0], [similarity], color='skyblue')
ax2.set_xlim(0, 1)
ax2.set_yticks([])
ax2.set_xlabel('余弦相似度')
ax2.set_title(f'"{selected_words[0]}" vs "{selected_words[1]}"')
# 添加相似度数值
ax2.text(similarity + 0.01, 0, f'{similarity:.4f}', va='center')
st.pyplot(fig2)
if __name__ == "__main__":
main()
第三步:创建 .env 文件
创建 .env 文件,填写阿里云百炼平台API Key:大模型服务平台百炼控制台
DASHSCOPE_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx2d
第三步:运行代码
streamlit run word_embedding_visualization.py
运行成功后会自动打开页面,可以看到有语义联系的词汇聚集在一起:
5.2 语义相似度计算
词嵌入向量能够计算单词之间的语义相似度。余弦相似度是常用的计算方法:
import numpy as np
def cosine_similarity(vec1, vec2):
"""计算两个向量的余弦相似度"""
dot_product = np.dot(vec1, vec2)
norm1 = np.linalg.norm(vec1)
norm2 = np.linalg.norm(vec2)
return dot_product / (norm1 * norm2)
“男人”和“女人”相比于“男人”和“航母”相似度就会更高:
六. 词嵌入的优劣势
6.1 词嵌入的优势
- 低维度稠密表示
- 相比独热编码(如10000维稀疏向量),词嵌入通常用几十到几百维的稠密向量表示单词,显著减少存储和计算资源需求。
- 稠密向量能更高效地捕捉语义关系(如相似词距离更近,类比关系可通过向量运算实现)。
- 语义与句法建模能力
- 通过训练数据中的上下文关联,词嵌入能学习到单词的语义(如"国王-男人+女人≈女王")和句法特征(如动词时态、词性变化)。
- 改进语言模型的上下文理解能力,提升预测准确率(如预测下一个词时结合语义关联)。
- 预训练模型广泛可用
- 预训练词嵌入(如Word2Vec、GloVe、FastText)可直接用于下游任务(如分类、翻译),无需从零训练,节省时间和算力。
- 支持快速部署,降低开发门槛。
- 处理词汇表外词(OOV)
- FastText等模型通过子词单元(字符n-gram)分解单词,即使遇到未见过的词(如新造词、拼写错误),也能生成合理向量。
- 减少特征工程需求
- 词嵌入自动从数据中学习特征,避免人工设计特征的复杂性。模型可直接将向量输入神经网络作为输入特征。
- 跨语言与形态学适应性
- 对形态丰富的语言(如土耳其语、芬兰语)效果更好,子词模型能分解复杂词结构。
6.2 词嵌入的劣势
- 计算与存储成本高
- 训练高质量词嵌入需大量语料和计算资源(尤其是大规模模型或复杂架构)。
- 预训练模型的嵌入矩阵体积庞大(如百万级词汇的500维向量需存储5亿个数值)。
- 词汇覆盖有限
- 传统词嵌入(如Word2Vec、GloVe)仅能表示训练时出现的词,对**OOV(Out-of-Vocabulary)**词无能为力(FastText等改进模型可缓解此问题)。
- 对领域特定术语(如医学、编程词汇)适应性差,需额外训练或调整。
- 偏见与伦理风险
- 训练数据中的社会偏见(如性别、种族刻板印象)可能被编码到嵌入向量中。例如,“护士→女性”、"工程师→男性"等关联可能被强化。
- 黑盒特性与可解释性差
- 词嵌入的向量空间是高度纠缠的,单个维度通常没有明确语义,难以直观解释模型决策逻辑。
- 依赖训练数据质量
- 如果训练数据不充分或有噪声(如拼写错误、歧义文本),嵌入结果可能不准确或不稳定。
- 无法处理同形词与多义词
- 传统词嵌入为每个词分配单一固定向量,无法区分多义词的不同含义(如"苹果"指水果或公司)。
- 上下文无关的模型(如Word2Vec)无法解决此问题,需依赖上下文相关的嵌入(如BERT)。
- 忽略语言细微差别
- 词嵌入难以捕捉反讽、隐喻等复杂语言现象。例如,“这部电影太棒了!”(实际是讽刺)可能被误判为正面情感。
- 静态表示的局限性
- 传统词嵌入(如Word2Vec、GloVe)提供静态向量,无法动态适应上下文变化。现代模型(如Transformer)已通过上下文相关嵌入解决此问题。
七. 结语
词嵌入向量技术是大模型理解人类语言的基础。从最初的Word2Vec到现代Transformer架构中的上下文相关表示,词嵌入技术不断发展,使AI能够更精确地理解和生成自然语言。
通过深入理解词嵌入向量的原理,我们不仅能更好地应用大模型,也能洞察人工智能是如何"思考"的。正如文章中所展示的,词嵌入不仅是技术工具,更是理解AI如何"理解"语言的窗口。
关键认识:词嵌入向量并不直接表示语义,而是词与词之间语义的相似度。因此,不必去纠结每个向量值到底代表什么意思。词嵌入空间通常是高度纠缠的,单个维度很少有明确的语义解释。
在AI快速发展的今天,词嵌入技术将继续进化,为更智能、更理解人类语言的AI系统奠定基础。
参考文章:



















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











