




随笔,内容比较杂,持续更新中
- 访问文件方式: r, w, a, rb, wb
r是读取,w是写入,a是在末尾追加,rb是读取二进制,wb是写入二进制
- 保存,读取pkl文件
直接存为txt,文件读取速度比较慢,存为pkl可以加快速度
list,dict都可以直接保存为pkl文件:import pickle with open(save_path, 'wb') as f: pickle.dump(data, f)读取pkl文件:
with open(save_path, 'rb') as f: data = pickle.load(f) - re模块
这个模块内容相当多,这里只介绍如何删除特殊字符,正则表达式可以看另一篇笔记
例子:替换input前两个!或@或#或$为x#删除字符 import re input = '!@#$qwe!' num = 2 result = re.sub('[\!\@\#\$]', 'x', input, num) # result = 'xx#$qwe!'
re.sub()有五个参数:pattern,str_need_to_replace,replaced_str,string,replace_number
第一个是匹配的正则模块,这个我们这不需要考虑,第二个是需要去除的字符,用\隔开,'\!\#'等同于'!#',会替换所有!#,加['!#']等同于替换所有单个字符!和#,第三个是用什么去替换前面的字符,例子中是x,第四个是需要处理的字符串,第五个是需要替换多少次,如果不写则默认为整个字符串中出现的均替换。
- 字典value排序
两种方法,一种利用zip构建一个新的tuple,一种利用字典的items()
两者返回的都是一个list,通过index可以遍历得到排序。a = {'a':1, 'b':3, 'c':2} a_1 = sorted(a.items(), key=lambda item:item[1], reverse=False) a_2 = sorted(zip(a.values(),a.keys())) #result: #a_1 = [('a', 1), ('c', 2), ('b', 3)] #a_2 = [(1, 'a'), (2, 'c'), (3, 'b')]
a_1: items()返回字典(key, value)的tuple,sorted遍历这个元组,将每一个tuple()的第二个元素,即value,传入匿名函数lambda进行排序。
a_2: 用zip() 打包成(value, key)的tuple,sorted遍历,按第一个元素value排序。
需要注意的是python3中zip()函数返回的不再是一个list,而是一个生成器,即c = zip(a,b) 需要用next(c)读取。
- 列表拷贝
a = [1,2] b = a c = list(a) a.append(3) print(a,b,c) #[1,2,3] [1,2,3] [1,2] - 处理异常
https://www.cnblogs.com/Lival/p/6203111.html
- __new__和__init__
new用来初始化类别,一般用于改变一些不可改变的类,例如使int始终为正整数
init用来初始化参数
用一个网上的例子:class PositiveInteger(int): def __init__(self,value): super(PositiveInteger,self).__init__(self,abs(value)) def __new__(cls,value): return super(PositiveInteger,cls).__new__(cls,abs(value)) k = PositiveInteger(-3) print k #k = 3 - python定义函数,没有默认值的参数要放在有默认值的参数前面
第一个正确,第二个会报错def fun1(a,b=10): pass def fun2(a=10,b): passnon-default argument follows default argument - copy() deepcopy()区别
copy是浅复制,deepcopy是深复制,简单的来说前者得到的新个体与原来的还有一定关联,后者得到的是一个全新的个体,一般浅复制可能会有一些感觉奇怪的结果,机制如下所示
(1)a是不可变对象(数值,字符串,元组),则b和a的id值相同,和deepcoy一样,并等同于等于赋值import copy b = copy.copy(a)
(2)a是可改变对象(列表,字典),且不包含复杂子对象(比如说某个元素也是一个列表),那么b和a是完全独立的,此时也与深复制等同,但不等同于等于赋值a = '12345' b = copy.copy(a) c = copy.deepcopy(a) d = a a = a + '6' print(a,b,c,d) #123456 12345 12345 12345
等于赋值在此时相当于给同一个数据打上两个标签,改变数据两者都会变,除非给a赋一个新值,可以理解为将标签a撕下来贴到另一个新数据上
(3)a是可改变对象(列表,字典),且包含子复杂对象,那么在不改变复杂子对象的情况下,b和a独立,否则改变a中的复杂子对象会影响到ba = [1,2] b = copy.copy(a) c = copy.deepcopy(a) d = a a.append(4) print(a,b,c,d) #[1,2,4] [1,2] [1,2] [1,2,4]#不改变复杂子对象 a = [1,2,[3]] b = copy.copy(a) c = copy.deepcopy(a) d = a a.append(4) print(a,b,c,d) #[1, 2, [3], 4] [1, 2, [3]] [1, 2, [3]] [1, 2, [3], 4]
deepcopy()需要的时间会是copy()的十倍以上,当数据量大的时候,甚至会是100倍。原因是为了防止原对象的子对象相关对象指向自己,比如说双向链表,深拷贝会同时维护一个memo来储存已拷贝的对象,否则程序会陷入死循环,所以导致速度会很慢。#改变复杂子对象 a = [1,2,[3]] b = copy.copy(a) c = copy.deepcopy(a) d = a a[2].append(4) print(a,b,c,d) #[1, 2, [3, 4]] [1, 2, [3, 4]] [1, 2, [3]] [1, 2, [3, 4]]
这篇文章讲的很详细:http://www.sohu.com/a/146737840_487512
- utf8编码:
英文小写字母: u'\u0061' <= char <= u'\u007a' 英文大写字母: u'\u0041' <= char <= u'\u005a' 数字: u'\u0030' <= char <= u'\u0039' 汉字: u'\u4e00' <= char <= u'\u9fa5' - 二十六进制转十进制:ord()
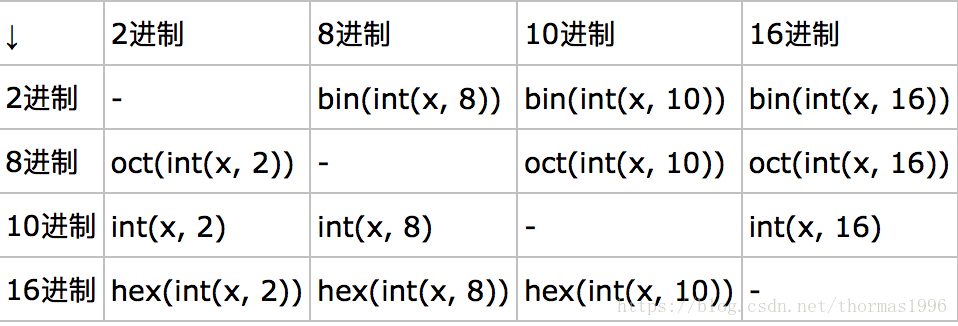
x为一个2或8或10或16进制数的字符串,用int(x, num)转化为十进制再转为相应需要的进制

















 2903
2903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









