





一、基本介绍
1. 项目背景
近期,Manus 以及 OpenAI 的 DeepSearch 产品热度飙升,顺势带火了一个名为 browser-use 的 Python 工具库。值得一提的是,该库获得了诸多资本的青睐,像 YC 等公司为其注入了 1700 万美元的融资,发展态势迅猛。据悉,创始人 Müller 仅用了一个周末便完成了想法验证。起初,他们采用开源方式助力社区,随后 browser-use 便声名大噪。由此可见,在 AI 社区中,快速迭代验证想法并开源共享是极为有效的开发模式。

此次进行技术分享,主要是面向可能会在智能体产品或团队中应用 browser-use 的相关人员,期望能对大家有所助益,同时也期待大家后续能开展更多相关技术分享。鉴于市场上已有众多类似 browser-use 的使用教程(文末参考资料中会附上相关链接),本次技术分享将重点聚焦于 browser-use 的技术原理解析,以及我个人发掘的一些有趣技术点。
2. 解决的问题
browser-use 工具主要是为了实现智能体轻松浏览网页
有人或许会问,为何不能直接使用 web search?其实,早在早期,AI 助手就能通过接入搜索引擎获取最新网络信息。
然而,web search 存在显著弊端:
- 信息获取受限:我们本质上调用的是搜索引擎 API,并非原始互联网数据。这就导致信息相对有限,像携程订票的最新价格、淘宝商品的最新信息等大量站内信息,搜索引擎往往无法获取,这类垂直站内信息需进入各站点内部方可获取。
- 功能单一:在实际操作场景中,如购买火车票等,web search 功能显得力不从心,它仅能用于搜索基本信息,而 browser-use 则更为便捷,通过模拟人类使用网页的方式,从而解锁更多的功能。
3. 问题解决途径

基于 playwright 库实现:playwright 原本用于网页端到端测试,是一个 Python 库,主要用于自动化 Web 浏览器测试与爬虫工作。
具体实现方式
- 纯文本方式:browser-use 库通过解析网页文件(如 html/css/javascript 代码),将获取的页面元素以文本形式提供给大语言模型(LLM)。这种方式通用性强,对模型要求不高,只要模型支持函数调用,或具备较强的指令跟随、格式遵守能力即可。例如,它能与包括 GPT-4、Claude 3 和 Llama 2 在内的所有 LangChain 大语言模型兼容。
- 文本 + 视觉方式:对于支持多模态的模型,同时提供图片与页面元素能显著提升效果,比如多模态 LLM 可以阅读网页中的图片数据,而纯文本的 LLM 无法做到。
4. 收费策略
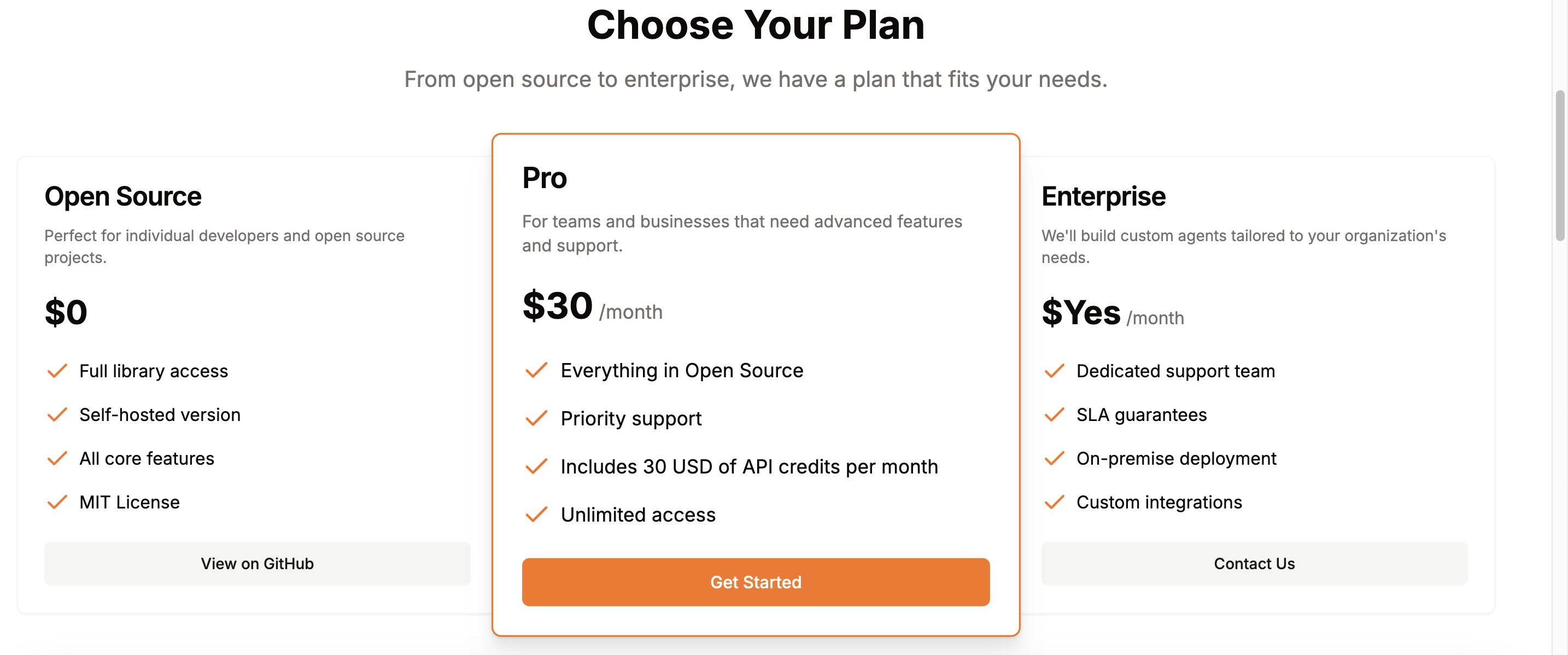
除了开源免费版本之外,官方还提供了付费服务,主要是提供一些技术咨询和私有化部署上的支持。对于大部分使用场景来说,开源免费版本已经完全满足我们的需求了。
二、效果实测
以下为 我改写过的测试代码,其主要任务是:访问 栋搞西搞-优快云博客,并浏览第一篇文章,将文章内容概要列出来
from langchain_openai import ChatOpenAI
from browser_use import Agent
import asyncio
from pydantic import SecretStr
from browser_use import BrowserConfig, Browser
import base64
import os
# Basic configuration
config = BrowserConfig(
# 如果希望使用无头浏览器,需要设置为 True
headless=False,
)
browser = Browser(config=config)
# 这里面我使用的是火山引擎的DeepSeek V3模型,你可以换成你需要希望使用的模型接口提供商,并替换 model name和 api key
llm=ChatOpenAI(base_url='https://ark.cn-beijing.volces.com/api/v3',
model='{your ark model endpoint ID}',
api_key=SecretStr('{your api key}'))
def save_base64_image(base64_data, output_path):
"""
将base64编码的图片保存到本地指定路径
参数:
base64_data (str): base64编码的图片数据,可以包含或不包含header (如 'data:image/jpeg;base64,')
output_path (str): 保存图片的完整路径,包括文件名和扩展名
返回:
bool: 保存成功返回True,否则返回False
"""
try:
# 如果base64_data包含header,则去除header
if ';base64,' in base64_data:
base64_data = base64_data.split(';base64,')[1]
# 确保输出目录存在
output_dir = os.path.dirname(output_path)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
# 解码base64数据并写入文件
with open(output_path, 'wb') as f:
f.write(base64.b64decode(base64_data))
return True
except Exception as e:
print(f"保存图片时出错: {e}")
return False
async def main():
agent = Agent(
browser=browser,
task="访问 https://blog.youkuaiyun.com/thomas20,并访问第一篇文章,将文章内容概要列出来",
llm=llm,
use_vision=False, # 如果使用的是非多模态模型,必须设置为False
save_conversation_path="
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章























 到【灌水乐园】发言
到【灌水乐园】发言







