




免费语音转字幕功能介绍
- 升级版(备案中) https://106.13.139.60 主站 https://thinktothings.com
- 功能介绍: https://thinktothings.github.io/speech_recognition/index.html
语音转字幕
- 免费的语音转字幕功能介绍,基于百度语音技术,识别率极高 无需注册 无语音时长限制 无文件大小限制 可在线对音频/视频文件进行自动语音识别
准备音频/视频文件
-
准备需要进行语音识别的音频/视频文件,格式支持wav m4a mp3 mka aac mp4 mov等
-
推荐使用wav格式,采样率不低于16000
上传音频/视频文件到网站进行处理
- 进入网站首页: https://thinktothings.com,点击上传音频按钮,进行音频/视频文件上传
在线编辑字幕
-
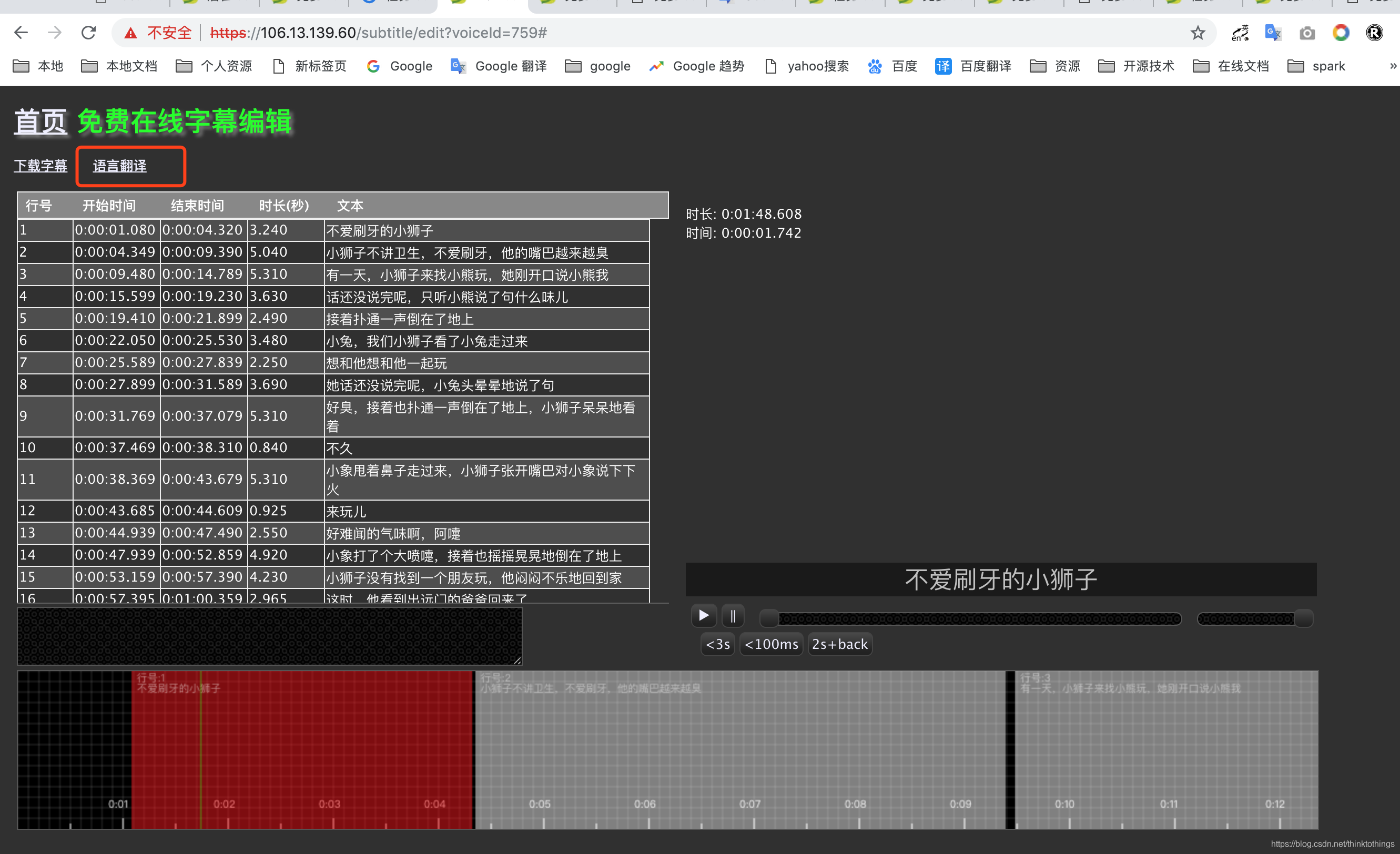
网站对音频/视频文件进行语音自动识别后,有极个别的同音字等识别错误,可在线进行字幕编辑,编辑好后,再下载,点下载时才会保存,如果编辑完成后没有点下载,是不会保存的
-
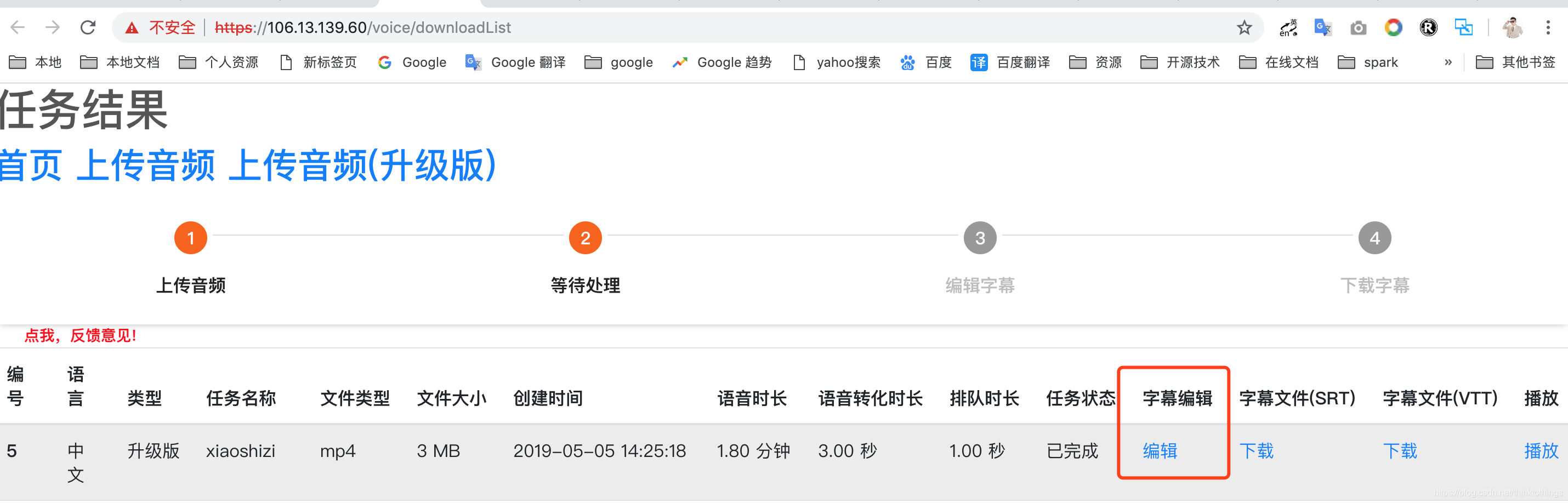
进入网站首页: https://thinktothings.com,点击任务结果按钮,可对已上传的音频/视频(状态为已完成)进行字幕编辑
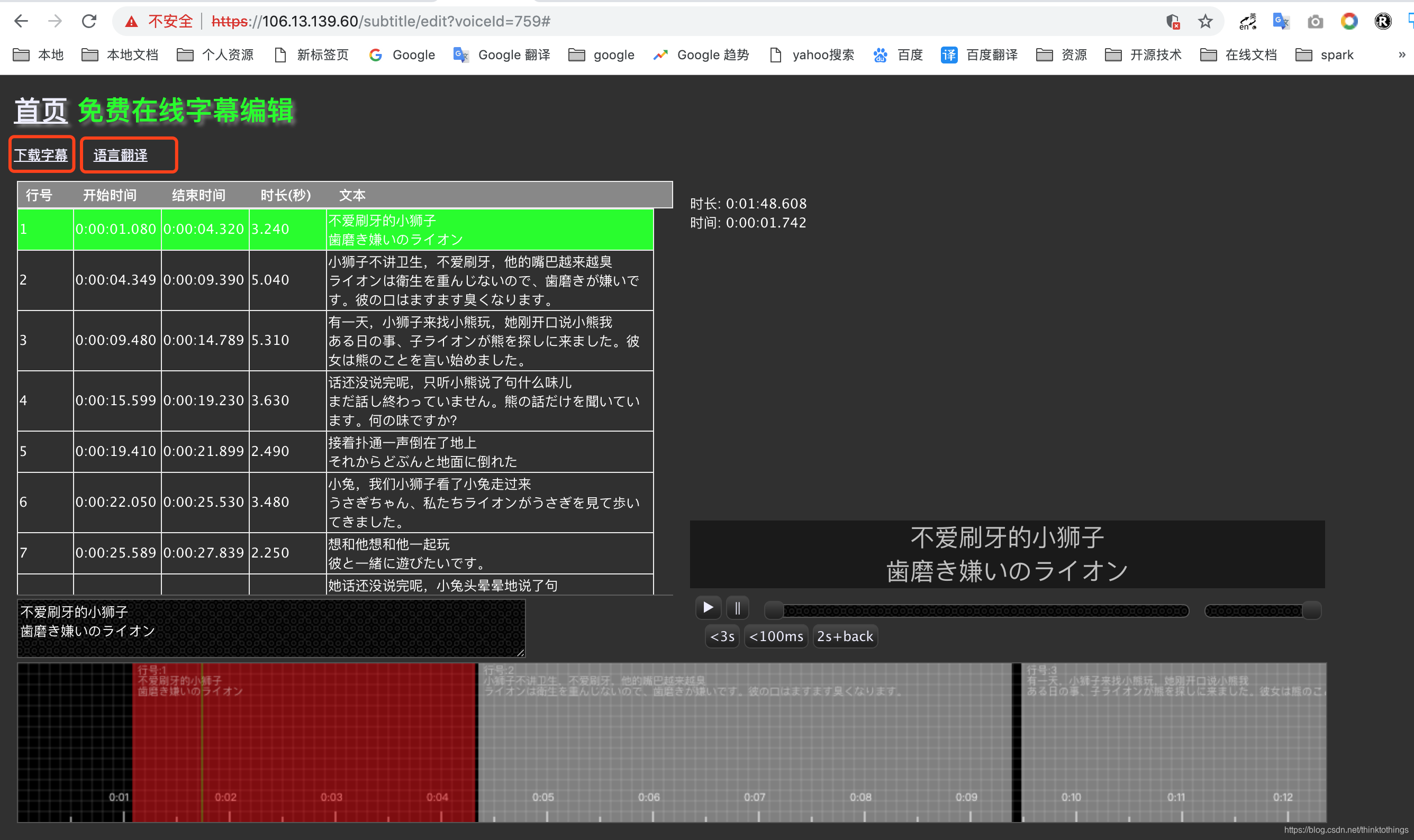
下载字幕
-
进入网站首页: https://thinktothings.com,点击任务结果按钮,可对已上传的音频/视频(状态为已完成)字幕下载
-
或在字幕编辑页面,编辑好后直接进行字幕下载
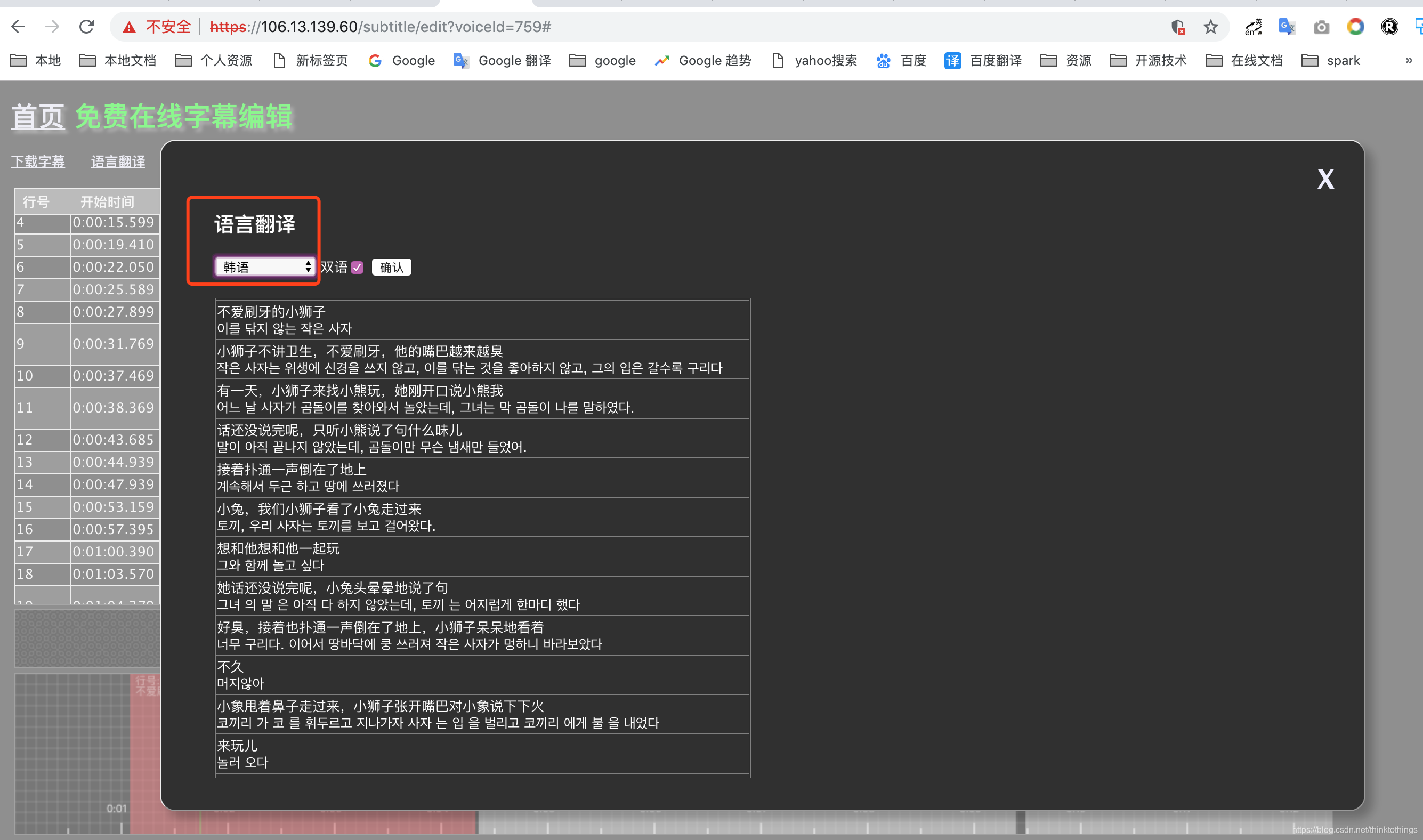
双语字幕自动生成
- 上传语音/视频文件翻译完成
- 任务结果页面 --> 选择字幕编辑 --> 进入字幕编辑页面
- 语言翻译 --> 从28种语言种选择需要翻译的语言 --> 选中双语/单语 复选框

实时语音转文字
-
可用电脑麦克风进行语音录制,并实时自动识别语音为文字
-
进入网站首页: https://thinktothings.com
-
找到实时语音识别
点击开始录制
- 自动调用电脑麦克风进行录制
视频录制
-
进入网站首页: https://thinktothings.com
-
菜单 -> 工具 -> 视频录制
-
可进行视频录制,并保存到本地
音频/视频/屏幕录制
-
进入网站首页: https://thinktothings.com
-
菜单 -> 工具 -> 音频/视频/屏幕 录制
-
可进行视频/音频/屏幕录制,并保存到本地
联系我们
微信: thinktothings
邮箱: thinktothings@163.com
示例
免费在线录音自动生成字幕介绍
https://www.bilibili.com/video/av51421703
免费在线录屏自动生成字幕介绍
https://www.bilibili.com/video/av51456675


















 2882
2882

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









