




 本文介绍了Java中数组和集合类的区别,特别是ArrayList和自定义泛型集合类的效率比较。接着,探讨了多线程的三种实现方式,包括继承Thread、实现Runnable接口和匿名类。最后,讲解了File类在文件处理中的应用,如文件读取和内容检索。
本文介绍了Java中数组和集合类的区别,特别是ArrayList和自定义泛型集合类的效率比较。接着,探讨了多线程的三种实现方式,包括继承Thread、实现Runnable接口和匿名类。最后,讲解了File类在文件处理中的应用,如文件读取和内容检索。
一、数组和集合类的区别
数组的长度是不可变的,如果初始长度过大,则会造成内存的浪费,降低性能,而数组初始长度过小时,又无法满足大量数据的存储。这时候就需要集合类(ArrayList)来进行数组扩容等操作,同时列表还可以包含批量删除、修改等便捷操作。
(一)Java数组的声明方式与C语言略有不同,有两种格式:
类型 数组名[]
类型 [] 数组名
int a[], b; 声明一个数组a和单个变量b
int[] a, b; 声明数组a和数组b
同时声明数组时也可以进行初始化:
静态初始化:public String musname[]={"coffee","tea"};
动态初始化:public String musname[]=new String[2];
数组声明时只能在动态、静态中选择一种方式进行初始化。数组属于引用型变量,数组变量中存放着数组的首元素的地址,通过数组变量的名字加索引使用数组元素。
(二)集合类List、ArrayList——封装数组的类
1、Java的列表是一个类,这个类中包含数组,也包含各种处理数组的方法,同时还有必要的get方法以取出保存的数组,Java自带了集合:java.util.ArrayList类(父类是List)。
为了更好理解底层原理,我们先自己定义一个集合类,集合类至少应包括添加元素、获取数组、获取长度等功能。在定义集合类之前,我们先考虑这样一个问题:对于不同的数据类型,如果我们想要使用集合,就需要创建不同数据类型的集合来存取,而如果我们使用Object类来创建初始数组,那么数据类型的元素都可以存进数组里,比如String、Integer等。
首先,自定义一个集合类:
/**
* Created by DYB on 2022/11/9.
* 自定义定义一个集合类
* 基本功能:集合类至少应包括添加元素、获取数组、获取长度等功能
* name:MyList
* Parameters:
* size:记录列表的长度
* array:类型为Object、长度为0的初始数组
* function:
* public Object[] getArray(){}:往列表中增加一个元素
* public int getSize(){}:获取集合的长度
*/
public class MyList {
private int size=0;
private Object[] arry=new Object[0];
//向列表中增加一个元素
public void add(Object obj){
Object[] newarry=new Object[arry.length+1];
for (int i=0;i<arry.length;i++){
newarry[i]=arry[i];
}
newarry[arry.length]=obj;
arry=newarry;
size++;
}
//获取数组
public Object[] getArray(){
return arry;
}
public int getSize(){
return size;
}
}
启动类中声明一个自定义集合类的对象,并模拟元素添加:
/**
* Created by DYB on 2022/11/4.
*/
public class TestSpring {
public static void main(String[] args) {
MyList list=new MyList();
System.out.println("list列表的长度为:"+list.getSize());
int a=10;
list.add(a);
list.add(a);
String b="abc";
list.add(b);
list.add(b);
System.out.println("list列表的长度为:"+list.getSize());
for (int i=0;i<list.getSize();i++){
System.out.print(list.getArray()[i] +" ");
}
}
}
运行结果:

从结果可以看到,我们声明了一个集合类,由于原始数组采用Object类,因此在一个集合中可以存放不同类型的数据。
2、泛型的出现:现在,我们考虑这样一个问题:实际工作中,我们往往需要一个数组里的元素都是同一个数据类型的,比如String,或者是我们定义的其他类。那么如何在集合类中实现对数据类型的控制呢?这就是泛型的作用了!
泛型:其符号是“<>”。我们可以在类名后加上< E >或者< T >等,其中的字母相当于将类型参数化,就是将类型作为参数传入到方法,这样我们创建List时可以通过泛型限制传入的元素,当出现不符合预期的元素时编译器便会报错。
自定义一个泛型集合类:
/**
* Created by DYB on 2022/11/10.
* 自定义一个泛型集合类
*/
public class FanList<T> {
private int size=0;
private Object[] array=new Object[0];
public void add(T element){
Object[] newarray=new Object[array.length+1];
for(int i=0;i<array.length;i++){
newarray[i]=array[i];
}
newarray[array.length]=element;
array=newarray;
size++;
}
public T GetArray(){
return (T)array;
}
public int GetSize(){
return size;
}
}
启动类:
/**
* Created by DYB on 2022/11/4.
*/
public class TestSpring {
public static void main(String[] args) {
FanList<String> list=new FanList<String>();
System.out.println("list列表的长度为:"+list.GetSize());
String a="abc";
list.add(a);
System.out.println("list列表的长度为:"+list.GetSize());
int b=32;
list.add(b);
System.out.println("list列表的长度为:"+list.GetSize());
}
}
在IDE中,编译器直接提示报错:FanList为String类型,不支持int类型数据。
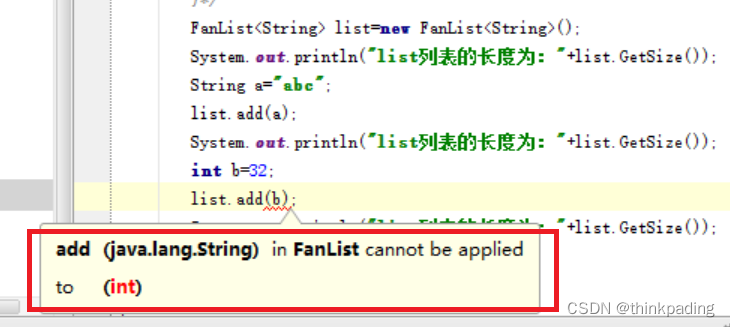
可以看到,我们通过泛型实现了集合类对数据类型的控制,即确保同一个集合中的数据都是同一种类型。
3、自定义泛型集合类(FanList)与系统自带泛型集合类(ArrayList)的效率比较
(1)FanList的扩容算法采用最基本的线性递增法
编写启动类:
import java.util.ArrayList;
/**
* Created by DYB on 2022/11/4.
*/
public class TestSpring {
public static void main(String[] args) {
//系统自带泛型集合类与自定义泛型集合类添加元素的效率比较
FanList<Integer> list01=new FanList<Integer>();
ArrayList<Integer> list02=new ArrayList<Integer>();
Long time01=System.currentTimeMillis(); //获取系统时间
for(int i=0;i<100000;i++){
list01.add(i);
}
Long time02=System.currentTimeMillis();
for(int i=0;i<100000;i++){
list02.add(i);
}
Long time03=System.currentTimeMillis();
System.out.println("FanList耗时:"+ (time02-time01));
System.out.println("ArrayList耗时:"+ (time03-time02));
System.out.println("Fanlist列表的长度为:"+list01.GetSize());
System.out.println("Arraylist列表的长度为:"+list02.size());
}
}
运行结果如下:
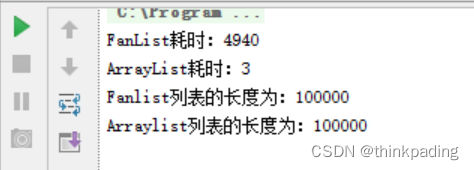
从运行结果可以看到,自定义泛型集合类的执行效率极为低下,因其采用线性扩容方法,即每次添加元素只扩容一个元素空间,而且此种算法随着数据的增加运行效率会越来越低!接下来,我们考虑对自定义泛型集合类进行算法优化,思路有二:
思路1:扩容算法改为按比例指数型扩容。
思路2:改进数组复制算法。(该思路暂时找不到比较好的实现方法,因此本文暂时仅对思路1进行实现分析)
(2)FanList的扩容算法改为按比例指数型扩容
//第二版,改进扩容算法:按1.5倍比例指数型扩容
private int size=0;
private Object[] array=new Object[0];
private Object[] newarray=new Object[array.length*3/2+1];
public void add(T element){
if(size>=newarray.length){
newarray=new Object[array.length*3/2+1];
for(int i=0;i<array.length;i++){
newarray[i]=array[i];
}
newarray[size]=element;
array=newarray;
}else {
newarray[size]=element;
array=newarray;
}
size++;
}
运行结果:
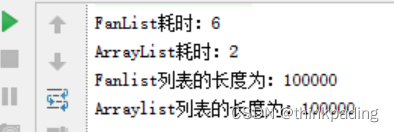
可见,与之前的结果相比,添加同样数量的元素,线性扩容法耗时4940ms,而改进后的按比例指数型扩容算法仅耗时6ms,效率显著改善。
二、多线程的三种实现方法
1、继承Thread类,并重写run()方法,通过start()启动线程。
定义一个hero类:
public class Hero {
public String name;
public float hp;
public int damage;
public void attackHero(Hero h){
//模拟攻击需要一定时间,暂停1s
try {
Thread.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
h.hp=h.hp-damage;
System.out.format("%s 正在攻击 %s,%s的值变成了%.0f%n",name,h.name,h.name,h.hp);
/* if(h.hp<=0){
System.out.format("%s is dead!%n", h.name);
}*/
if(h.isDead()){
System.out.format("%s is dead!%n", h.name);
}
}
public boolean isDead(){
return 0>=hp?true:false;
}
}
自定义一个KillThread类:
public class KillThread extends Thread {
private Hero H1;
private Hero H2;
//通过构造函数进行传参
public KillThread(Hero h1,Hero h2){
this.H1=h1;
this.H2=h2;
}
//重写run方法
public void run(){
while(!H2.isDead()){
H1.attackHero(H2);
}
}
}
入口程序:
public class TestMultiThread {
public static void main(String[] args){
//定义A对象
final Hero ALong=new Hero();
ALong.name="A";
ALong.hp=100;
ALong.damage=10;
//定义B对象
final Hero BLong=new Hero();
BLong.name="B";
BLong.hp=100;
//定义C对象
final Hero CLong=new Hero();
CLong.name="C";
CLong.hp=100;
CLong.damage=10;
//定义D对象
final Hero DLong=new Hero();
DLong.name="D";
DLong.hp=100;
KillThread killThread01=new KillThread(ALong,BLong);
new Thread(killThread01).start();
//killThread01.start(); //与上一句都可以
KillThread killThread02=new KillThread(CLong,DLong);
killThread02.start();
Battle battle01=new Battle(ALong,BLong);
new Thread(battle01).start();
Battle battle02=new Battle(CLong,DLong);
new Thread(battle02).start();
}
}
2、实现Runnable接口
public class Battle implements Runnable {
private Hero H1;
private Hero H2;
//通过构造函数进行传参
public Battle(Hero h1,Hero h2){
this.H1=h1;
this.H2=h2;
}
//重写run方法
public void run(){
while(!H2.isDead()){
H1.attackHero(H2);
}
}
}
3、匿名类
定义类不变,区别主要在于类的实现:
public class TestMultiThread {
public static void main(String[] args){
//定义A对象
final Hero ALong=new Hero();
ALong.name="A";
ALong.hp=100;
ALong.damage=10;
//定义B对象
final Hero BLong=new Hero();
BLong.name="B";
BLong.hp=100;
//定义C对象
final Hero CLong=new Hero();
CLong.name="C";
CLong.hp=100;
CLong.damage=10;
//定义D对象
final Hero DLong=new Hero();
DLong.name="D";
DLong.hp=100;
Thread t1=new Thread(){
public void run(){
while(!BLong.isDead()){
ALong.attackHero(BLong);
}
}
};
t1.start();
Thread t2=new Thread(){
public void run(){
while(!DLong.isDead()){
CLong.attackHero(DLong);
}
}
};
t2.start();
}
}
三、文件处理
1、File类
File类,通过带入一个文件路径,可以作为一个指向特定目录的引用型变量:
String baseDirStr="C:\\Users\\DYB\\Desktop\\TestSpring\\src";
File baseDir=new File(baseDirStr);
通过定义一个File类型的数组,可以实现对该目录的遍历:
File[] files=baseDir.listFiles();
for(File file:files){
}
通过InputStreamReader类可以实现对文件的读取:
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(new File(file.toString())), "UTF-8"));
通过readLine方法可以实现对文件内容每一行的读取:
String lineTxt = null;
while ((lineTxt = br.readLine()) != null){
//文本识别处理代码}
通过contains()方法可以实现对指定内容的检索:
lineTxt.contains(SearchStr)
下面是一个从.java文件中寻找匹配字符串并保存相应文件名的实现案例:
public static void processFile(File dir){
//获取子文件及目录
File[] files=dir.listFiles();
for(File file:files){
//是文件就判断后缀
if(file.isFile()){
if (file.getName().endsWith(".java")){
/* 读取数据 */
try {
BufferedReader br = new BufferedReader(
new InputStreamReader(new FileInputStream(new File(file.toString())), "UTF-8"));
String lineTxt = null;
while ((lineTxt = br.readLine()) != null) {
if (IngronCase) {
if (lineTxt.contains(SearchStr)) {
list.add("在【" + file.getAbsolutePath()+file.getName() + "】文件中找到了" + SearchStr );
break;
}
} else {
if (lineTxt.toLowerCase().contains(SearchStr.toLowerCase())) {
list.add("在【" + file.getAbsolutePath()+file.getName() + "】文件中找到了" + SearchStr );
break;
}
}
}
br.close();
} catch (Exception e) {
// TODO: handle exception
System.err.println("读取文件错误 :" + e);
}
//list.add(file.getAbsolutePath()+file.getName());
}
}else{
//是目录就继续遍历,形成递归
processFile(file);
}
/* end of 读取数据 */
}
}

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









