







Redis
数据类型及底层
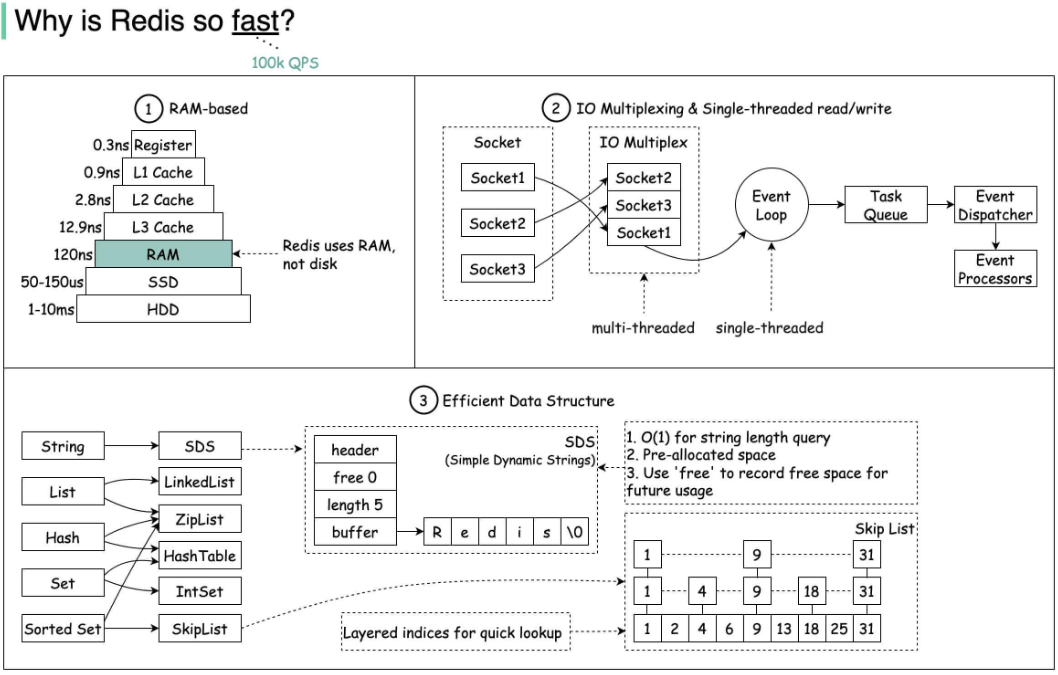
String:SDS(simple dynamic string)简单动态字符串
List:ziplist(压缩列表)和 linkedlist(双向链表)
Hash:ziplist(压缩列表)和 hashtable(字典,类似HashMap)
Set:intset(整数集合)和 hashtable(字典)
ZSet:ziplist(压缩列表)和 skipList(跳表)+hashtable(字典)
特殊数据类型
Bitmap:存储的是连续的二进制数字
HyperLogLog:一种有名的基数计数概率算法
Geospatial index:地理空间索引,简称 GEO
对于读写命令来说,Redis 一直是单线程模型。不过,在 Redis 4.0 版本之后引入了多线程来执行一些大键值对的异步删除操作, Redis 6.0 版本之后引入了多线程来处理网络请求(提高网络 IO 读写性能)。
不支持回滚,无法满足原子性、持久性。
延时双删策略
解决数据不一致问题:清除redis => update数据库 => 延迟N秒 => 清除redis
过期键的删除策略
定时过期删除:设置过期时间,过期后立即删除,内存友好,但占用CPU;
惰性过期删除:用到才判断是否过期,过期则删除,内存不友好;
定期过期删除:定期扫描删除过期的键,折中方案。
内存淘汰策略
全局的键空间选择性移除:
- noeviction:内存不足时,新写入会报错。
- allkeys-lru:内存不足时,在键空间中,移除最近最少使用的key。(最常用)
- allkeys-random:内存不足时,在键空间中,随机移除某个key。
设置过期时间的键空间选择性移除:
- volatile-lru:内存不足时,在设置了过期时间的键空间中,移除最近最少使用的key。
- volatile-random:内存不足时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:内存不足时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
4.0后新增了最不经常使用allkeys-lfu、volatile-lfu
PS:内存淘汰策略用于处理内存不足时的需要申请额外空间的数据;过期删除策略用于处理过期的缓存数据。
持久化方式
RDB(Redis DataBase)
在不同的时间点,将Redis 存储的数据生成快照副本并存储到磁盘等介质上。(高效、快,易丢失,不易实时)
AOF(Append Only File)
将Redis 执行过的所有写指令记录下来,在下次Redis重启时,把这些写指令从前到后再重复执行一遍,就可以实现数据恢复了。(数据恢复完整度更高,文件体积大)
缓存异常
1.缓存预热
缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统。避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
2.缓存雪崩
短时间范围内,大量key集中过期
解决方案:
1).原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件
2).设置多级缓存架构(redis以外的)
3).快速预热,缓存预热就是系统启动前,提前将相关的缓存数据直接加载到缓存系统
4).缓存失效后,通过加锁或者队列来控制读数据库写缓存的线程数量。比如对某个key只允许一个线程查询数据和写缓存,其他线程等待。
3.缓存击穿
单个key高热数据,key过期,未命中redis
解决方案:
缓存预热;
设置热点数据永远不过期;
加锁,当某个热点key过期时,大量的请求会进行资源竞争,当某个请求成功执行时,其它请求就需要等待。
4.缓存穿透
缓存和数据库中都没有的数据,导致所有的请求都落到数据库上(命中率低),造成数据库短时间内承受大量请求而崩掉。
解决:
比如某个请求需要的数据是不存在的,那么仍然将这个数据的key进行存储,这样下次请求时就可以从缓存中获取,但若是每次请求数据的key均不同,那么Redis中就会存储大量无用的key,所以应该为这些key设置一个指定的过期时间,到期自动删除即可。
消息队列
应用场景
1.解耦
eg:订单系统与库存系统耦合,在下单时库存系统不能正常使用,也不影响正常下单,因为下单后,订单系统写入消息队列就不再关心其他的后续操作了。实现订单系统与库存系统的应用解耦。
2.异步提升效率
3.流量削峰
参考百度安全验证
模式分类
1.PTP点对点方式
消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
消息被消费以后,queue中不再存储对一个消息而言,只会有一个消费者可以消费。即1对1
2.发布订阅方式
消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。即多对多
Zookeeper
zookeeper是一个分布式服务框架,用来解决分布式应用中遇到的数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
zookeeper=文件系统+监听通知机制
Dubbo
高性能RPC(一种远程调用)分布式服务框架。
| Provider | 暴露服务的服务提供方 |
| Consumer | 调用远程服务的服务消费方 |
| Registry | 服务注册与发现的注册中心(zookeeper 满足CP,Eureka满足AP) |
| Monitor | 统计服务的调用次数和调用时间的监控中心 |
| Container | 服务运行容器 |
1、服务容器负责启动,加载,运行服务提供者。
2、服务提供者在启动时,向注册中心注册自己提供的服务。
3、服务消费者在启动时,向注册中心订阅自己所需的服务。
4、注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
5、服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
6、服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
负载均衡方案:
Random LoadBalance(按权重随机)、RoundRobin LoadBalance(轮询 按公约后的权重设置轮询比率)、LeastActive LoadBalance(最少活跃调用数)、ConsistentHash LoadBalance(一致性Hash 相同参数的请求总是发到同一提供者)。
SpringCloud
五大组件:
服务注册与发现(Eureka):HTTP REST方式调用,满足AP
负载均衡(Ribbon服务名调用;Feign接口+注解调用,类似Controller调用Service)
断路器(Hystrix):限流、熔断(出错Fallback)、降级(无关服务降级)
网关(Zuul):对请求路由(安全访问,不暴露地址)、过滤
分布式配置(Config)
js
1. 函数:闭包()()
2. Dom(文档对象模型)
document
id,name,tag
create,remove
3. Bom(浏览器对象模型)
window
document、location、navigator、screen、history、frames


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









