







 本文详细介绍了顺序表的结构、初始化、插入、删除等关键算法,并展示了如何进行模块化设计,包括头文件声明、功能函数实现、主函数及Makefile。此外,还提出了一个关于班级花名册的编程作业,涉及结构体类型数据的操作。
本文详细介绍了顺序表的结构、初始化、插入、删除等关键算法,并展示了如何进行模块化设计,包括头文件声明、功能函数实现、主函数及Makefile。此外,还提出了一个关于班级花名册的编程作业,涉及结构体类型数据的操作。
目录
一、内容简介
定义:顺序表是一种数据元素间逻辑关系上一对一,且需要一片地址连续的存储空间存放的一种数据结构。
优点:1.顺序表支持随机存储;
2.按照索引查询速度快;
缺点:1.插入和删除元素不方便(会导致大量的数据元素移动);
2.内存空间利用率低;
适用场景:查询频繁,对空间使用要求不大(即数据量小),且删除和插入的操作尽量少。
二、关键算法理解
1.初始化
算法思想:
首先为了方便对顺序表进行统一的操作,我们可以将整个顺序表定义成结构体。因此此时,已经是声明了一整个顺序表(而链表及其他链式结构,都知识声明了一个结点而已,而非整个结构)
其次是明确数组的概念是跟顺序表类似的,为了方便后续功能函数的操作,我们可以在定义顺序表的结构体中,定义一个变量last,让其指向顺序表的最后一个最后一个元素。初始化时,last = -1。(为了方便后续的判断与操作)
最后一定要明确顺序表下标是从0开始的,而涉及到顺序表长度的时候不要将下标和长度弄乱!!
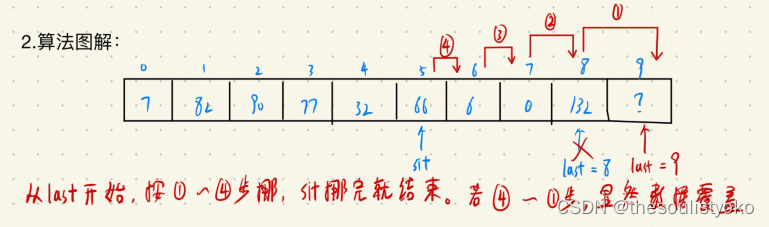
2.按位置插入
算法思想:先挪再插。若在下标为sit 的地方插入数据,意味着sit及其以后的数据都要往后移,最关键的是最后面的数据最先移,否则会产生数据覆盖的情况。
算法图解:
3.按位置删除
算法思想:挪动覆盖。要删除下标为sit 的地方的数据,使用sit后面的数据覆盖掉sit即可,后续同理,统一往前覆盖。
算法图解: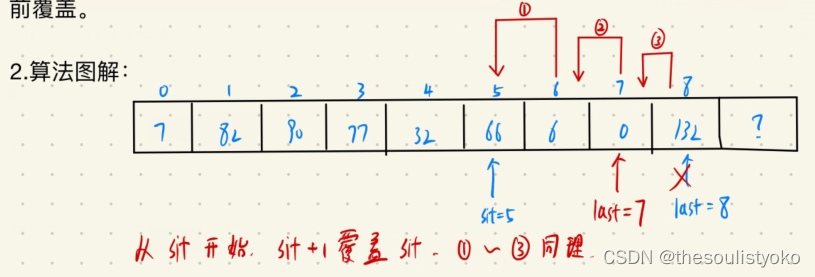
4.销毁
算法思想:
首先要明确,除了销毁的其他操作,都是得到了顺序表首地址后,对顺序表的后续地址进行操作,因此只需要这些操作的功能函数中,形参传一个一级指针即可。
但是,在销毁的时候,在主函数中定义的局部指针变量,得到了顺序表的首地址,需要对熟悉表表头,即该地址进行实质操作时,需要进行按地址传参,因此需要传&p,导致了销毁函数中的形参是二级指针。
进而,销毁函数中,调用的free()函数和赋值操作,都是对一级指针进行操作,所以需要对实参的二级指针进行降级操作,即*head(不要被名字迷惑,此时的head实质上是&p,而p是*类型的)。(具体参照指针运算,*和[ ]等价,而&和[ ] 是逆运算,因此可降级)
三、模块化
1. 头文件声明
#ifndef _SEQLIST_H_
#define _SEQLIST_H_
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 100
typedef int data_type;
typedef struct list{
data_type data[SIZE];
int last; //顺序表最后一个数据元素的下标
}seqlist; //此时已经定义好了一个完整的连续的顺序表(不是定义了一个结点)
/********************************************************
* *
* *
* 函数声明 *
* *
* *
* *
********************************************************/
//初始化
seqlist*Seqlist_creat();
//判空
int Seqlist_empty(seqlist *seq);
//判满
int Seqlist_full(seqlist *seq);
求表长(即顺序表有几个数据元素)
int Seqlist_length(seqlist *seq);
//按位置查找
int Seqlist_find_bysit(seqlist *seq,int sit);
//按位置插入
int Seqlist_insert_bysit(seqlist *seq,int sit,data_type data);
//按位置删除
int Seqlist_delete_bysit(seqlist *seq,int sit);
//按位置修改
int Seqlist_change_bysit(seqlist *seq,int sit,data_type data);
//按值查找
int Seqlist_find_bydata(seqlist *seq,data_type data);
//按值删除
int Seqlist_delete_bydata(seqlist *seq,data_type data);
//按值修改
int Seqlist_change_bydata(seqlist *seq,data_type old_data,data_type new_data);
//输出(即打印顺序表的内容)
void Seqlist_output(seqlist *seq);
//清空
void Seqlist_clear(seqlist *seq);
//销毁
void Seqlist_destroy(seqlist **seq);
//从大到小排序
void Seqlist_paixv(seqlist *seq);
#endif在头文件的声明中,关键是要用#ifndef判断一下是否会产生重复定义。如果多个文件都引用了该文件,会导致重复包含,比较“麻烦”。
 https://blog.youkuaiyun.com/weixin_42134466/article/details/103928854?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165589819016781818716833%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165589819016781818716833&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-103928854-null-null.142%5Ev20%5Econtrol,157%5Ev15%5Enew_3&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88c%E8%AF%AD%E8%A8%80%E5%A4%B4%E6%96%87%E4%BB%B6%E8%A6%81%E5%A3%B0%E6%98%8E%23ifndef&spm=1018.2226.3001.4187
https://blog.youkuaiyun.com/weixin_42134466/article/details/103928854?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522165589819016781818716833%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=165589819016781818716833&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-1-103928854-null-null.142%5Ev20%5Econtrol,157%5Ev15%5Enew_3&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88c%E8%AF%AD%E8%A8%80%E5%A4%B4%E6%96%87%E4%BB%B6%E8%A6%81%E5%A3%B0%E6%98%8E%23ifndef&spm=1018.2226.3001.4187以及这篇文章:
 https://blog.youkuaiyun.com/Dontla/article/details/123461937?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88c%E8%AF%AD%E8%A8%80%E5%A4%B4%E6%96%87%E4%BB%B6%E8%A6%81%E5%A3%B0%E6%98%8E?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88c%E8%AF%AD%E8%A8%80%E5%A4%B4%E6%96%87%E4%BB%B6%E8%A6%81%E5%A3%B0%E6%98%8E&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-123461937.nonecase&spm=1018.2226.3001.4187#ifndef&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-123461937.nonecase
https://blog.youkuaiyun.com/Dontla/article/details/123461937?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88c%E8%AF%AD%E8%A8%80%E5%A4%B4%E6%96%87%E4%BB%B6%E8%A6%81%E5%A3%B0%E6%98%8E?ops_request_misc=&request_id=&biz_id=102&utm_term=%E4%B8%BA%E4%BB%80%E4%B9%88c%E8%AF%AD%E8%A8%80%E5%A4%B4%E6%96%87%E4%BB%B6%E8%A6%81%E5%A3%B0%E6%98%8E&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-123461937.nonecase&spm=1018.2226.3001.4187#ifndef&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduweb~default-0-123461937.nonecase2. 功能函数
在功能函数的总文件中,声明只需要 #include "seqlist.h"即可。
初始化:
//初始化
seqlist *Seqlist_creat()
{
seqlist *seq = (seqlist *)malloc(sizeof(seqlist));
/*这里是用动态分配的方法声明,也可以静态分配,
具体在main函数中,直接seqlist seq = {{0},-1}即可*/
if(NULL == seq){
perror("malloc");
return NULL;
}
seq->last = -1; //因为last指向表尾元素,初始化时没元素,则-1刚刚好。注意last不是指针
memset(seq->data,0,sizeof(data_type)*SIZE);
//该函数作用是将该片连续的存储空间的数据都清空为0
return seq; //得到的只是顺序表的首地址
}判空:(为了代码的可维护性,其实应该判断 if(NULL == seq) 二次防止顺序表申请失败,以下功能函数模块均同理。同时NULL == 写在左边是为了增加容错率,防止敲代码的时候漏了一个'=',导致变成赋值,使判断一直成立,从而找不出判断时的错误)
//判空
int Seqlist_empty(seqlist *seq)
{
if(seq->last == -1)
return 1;
else
return 0;
}判满:
//判满
int Seqlist_full(seqlist *seq)
{
if(seq->last == SIZE - 1) //SIZE是顺序表最大长度,而下标从0开始,所以要-1
return 1;
else
return 0;
}
求表长:
//求表长
int Seqlist_length(seqlist *seq)
{
return seq->last + 1; //last是表尾元素下标,而下标从0开始,因此+1即可
}按位置查找:
//按位置查找
{
if(Seqlist_empty(seq) || sit < 0 || sit > seq-> last) //超过表尾肯定不行,但插入可以
return -1;
else
return seq->data[sit];
}
按位置插入:
//按位置插入
int Seqlist_insert_bysit(seqlist *seq,int sit,data_type data)
{
if(Seqlist_full(seq) || sit < 0 || sit > Seqlist_length(seq))
//length=last+1,因为可以在表尾后一个地方插入,length刚好
return -1;
else{
int i;
for(i = seq->last; i >= sit ; i--){ //最后面的最先动,不然会数据覆盖
seq->data[i+1] = seq->data[i];
}
seq->data[sit] = data; //先挪再插,此时挪完即可赋值
seq->last++;
}
return 0;
}按位置删除:
//按位置删除
int Seqlist_delete_bysit(seqlist *seq,int sit)
{
if(Seqlist_empty(seq) || sit < 0 || sit > seq->last)//表尾后没元素,没得删,所以是last
return -1;
else{
int i;
for(i = sit; i < seq->last; i++){ //从sit后一位开始覆盖即可
seq->data[i] = seq->data[i+1];
}
seq->last--;
}
return 0;
}按位置修改:
//按位置修改
int Seqlist_change_bysit(seqlist *seq,int sit,data_type data)
{
if(Seqlist_empty(seq) || sit < 0 || sit > seq->last)
return -1;
else{
seq->data[sit] = data;
return 0;
}
}
按值查找:
//按值查找
int Seqlist_find_bydata(seqlist *seq,data_type data)
{
if(Seqlist_empty(seq))
return -1;
else{
int i;
for(i = 0; i < Seqlist_length(seq); i++){
if(seq->data[i] == data)
return i; //返回该值的下标
}
return -1; //找不到即判错
}
}按值插入:(好像没有这个必要,因为不知道是在指定值的前面还是后面)
//按值插入
按值删除:
//按值删除
int Seqlist_delete_bydata(seqlist *seq,data_type data)
{
if(Seqlist_empty(seq))
return -1;
else{
int sit = Seqlist_find_bydata(seq,data); //直接调用之前写的函数即可
Seqlist_delete_bysit(seq,sit); //先找到该值的位置,再按位置删除即可
return 0;
}
return -1;
}按值修改:
//按值修改
int Seqlist_change_bydata(seqlist *seq,data_type old_data,data_type new_data)
{
if(Seqlist_empty(seq))
return -1;
else{
int sit = Seqlist_find_bydata(seq,old_data);
Seqlist_change_bysit(seq,sit,new_data); //同理,注意各个函数的形参形式即可
return 0;
}
return -1;
}清空:
//清空
void Seqlist_clear(seqlist *seq)
{
seq->last = -1;
}销毁:
//销毁
void Seqlist_destroy(seqlist **seq)
//因为销毁free的是main里面的seq指定的空间,要按地址传递
{
free(*seq);
*seq = NULL;
}
遍历:
//遍历
void Seqlist_output(seqlist *seq)
{
if(Seqlist_empty(seq))
printf("printf error\n");
else{
int i;
for(i = 0; i < Seqlist_length(seq); i++){
printf("%d ",seq->data[i]);
}
printf("\n");
}
}3. 主函数
#include "seqlist.h"
#include <stdio.h>
int main(int argc, char *argv[])
{
seqlist *p = Seqlist_creat();
if(NULL == p){
printf("申请顺序表空间失败!\n");
return -1;
}
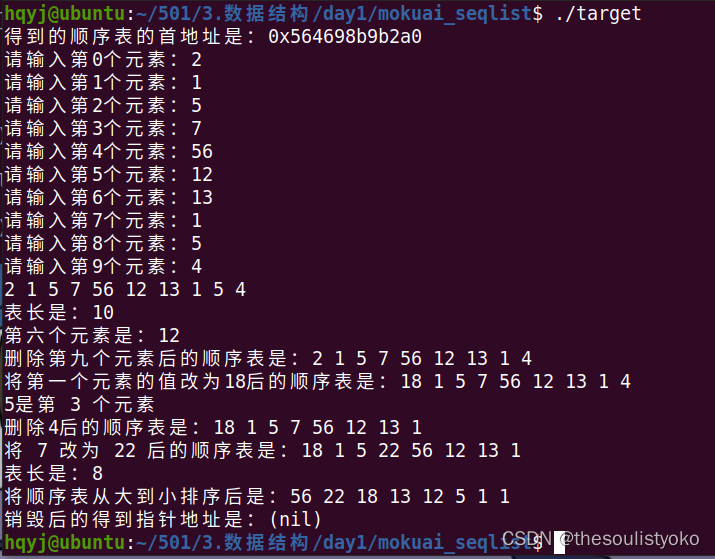
printf("得到的顺序表的首地址是:%p\n",p);
for(int i = 0; i < 10; i++){
int n;
printf("请输入第%d个元素:",i);
scanf("%d",&n);
Seqlist_insert_bysit(p,i,n);
}
Seqlist_output(p);
printf("表长是:%d\n",Seqlist_length(p));
printf("第六个元素是:%d\n",Seqlist_find_bysit(p,5));
Seqlist_delete_bysit(p,8);
printf("删除第九个元素后的顺序表是:");
Seqlist_output(p);
Seqlist_change_bysit(p,0,18);
printf("将第一个元素的值改为18后的顺序表是:");
Seqlist_output(p);
printf("5是第 %d 个元素\n",Seqlist_find_bydata(p,5)+1);
Seqlist_delete_bydata(p,4);
printf("删除4后的顺序表是:");
Seqlist_output(p);
Seqlist_change_bydata(p,7,22);
printf("将 7 改为 22 后的顺序表是:");
Seqlist_output(p);
printf("表长是:%d\n",Seqlist_length(p));
Seqlist_paixv(p);
printf("将顺序表从大到小排序后是:");
Seqlist_output(p);
Seqlist_destroy(&p);
printf("销毁后的得到指针地址是:%p\n",p);
} 4.Makefile
#!/bin/bash
target:main.o seqlist.o
@$(CC) $^ -o target
main.o:main.c
@gcc -c main.c -o main.o
seqlist.o:seqlist.c
@$(CC) -c $^ -o $@
.PHONY:clean
clean:
@$(RM) *.o
$^是所有依赖文件,$@是指目标文件?
@的作用是make的时候不在终端显示命令的执行过程,
而.PHONY是的具体作用可参照以下文章
5.实现效果
四、小作业
1.题目描述
2.具体实现
首先明确,因为数据类型的转变,由以上的int类型转成了一个结构体,所以部分模块函数可不变,则以下只展示了部分模块代码,且模拟的环境是人为想象,具有主观性。
具体的规则是:
按位置查找:返回值是学生的名字;
按位置修改:通过顺序表下标 修改 对应 学生结构体 中的成绩一栏;
按值查找:这里规定的是通过成绩找人,即输入成绩,输出学生名字;
按值删除:这里规定通过输入学生名字开除该学生;
按值修改:这里规定通过学生的名字,修改其对应的成绩;
以下代码未展示的模块说明与上面的代码一样,其余见代码部分后的解释。
部分代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define SIZE 100
typedef struct stu{
char xuehao[20];
char name[20];
float score;
}data_type;
typedef struct{
data_type data[SIZE];
int last;
}seqlist;
//初始化
//判空
//判满
//求表长
//按位置查找(可以规定为返回学生的名字)
char *Seqlist_find_bysit(seqlist *seq,int sit)
{
if(Seqlist_empty(seq) || sit < 0 || sit > seq-> last)
return "error";
else
return seq->data[sit].name;
}
//按位置插入
//按位置删除
//按位置修改(这里可规定修改的是成绩)
int Seqlist_change_bysit(seqlist *seq,int sit,float score)
{
if(Seqlist_empty(seq) || sit < 0 || sit > seq->last)
return -1;
else{
seq->data[sit].score = score;
return 0;
}
}
//按值查找(这里可以规定通过成绩找人)
char *Seqlist_find_bydata(seqlist *seq,float score)
{
if(Seqlist_empty(seq))
return "error";
else{
int i;
for(i = 0; i < Seqlist_length(seq); i++){
if(seq->data[i].score == score)
return seq->data[i].name;
}
return "nobody";
}
}
//按值删除(可以规定通过名字删除)
int Seqlist_delete_bydata(seqlist *seq,char *name)
{
if(Seqlist_empty(seq))
return -1;
else{
for(int i = 0; i < Seqlist_length(seq); i++){
if(strcmp(seq->data[i].name,name) == 0)
Seqlist_delete_bysit(seq,i);
}
return 0;
}
return -1;
}
//按值修改(可以规定通过找名字修改该学生的成绩)
int Seqlist_change_bydata(seqlist *seq,char *name,float score)
{
if(Seqlist_empty(seq))
return -1;
else{
for(int i = 0; i < Seqlist_length(seq); i++){
if(strcmp(seq->data[i].name,name) == 0){
Seqlist_change_bysit(seq,i,score);
}
}
}
return 0;
}
//输出
void Seqlist_output(seqlist *seq)
{
if(Seqlist_empty(seq))
printf("printf error\n");
else{
int i;
for(i = 0; i < Seqlist_length(seq); i++){
printf("%s %s %.2f\n",seq->data[i].xuehao,seq->data[i].name,seq->data[i].score);
}
}
}
int main(int argc, char *argv[])
{
seqlist *p = Seqlist_creat();
if(NULL == p){
printf("申请顺序表空间失败!\n");
return -1;
}
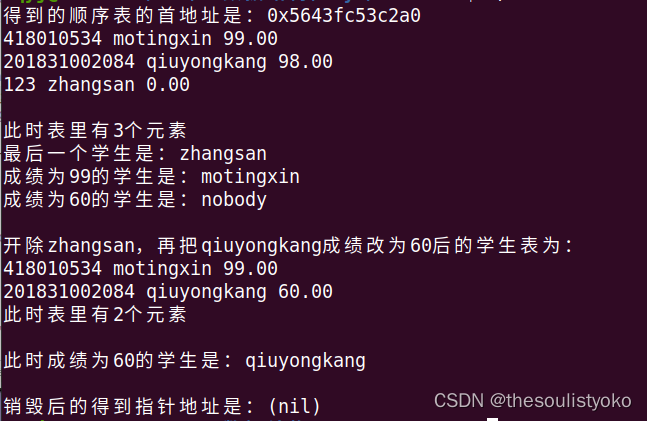
printf("得到的顺序表的首地址是:%p\n",p);
data_type stu1 = {{"418010534"},{"motingxin"},99};
data_type stu2 = {{"201831002084"},{"qiuyongkang"},98};
data_type stu3 = {"123","zhangsan",0};
Seqlist_insert_bysit(p,0,stu1);
Seqlist_insert_bysit(p,1,stu2);
Seqlist_insert_bysit(p,2,stu3);
Seqlist_output(p);
puts("");
printf("此时表里有%d个元素\n",Seqlist_length(p));
printf("最后一个学生是:");
fputs(Seqlist_find_bysit(p,p->last),stdout);
puts("");
printf("成绩为99的学生是:");
fputs(Seqlist_find_bydata(p,99),stdout);
puts("");
printf("成绩为60的学生是:");
fputs(Seqlist_find_bydata(p,60),stdout);
puts("");
puts("");
printf("开除zhangsan,再把qiuyongkang成绩改为60后的学生表为:\n");
Seqlist_delete_bydata(p,"zhangsan");
Seqlist_change_bydata(p,"qiuyongkang",60);
Seqlist_output(p);
printf("此时表里有%d个元素\n",Seqlist_length(p));
puts("");
printf("此时成绩为60的学生是:");
fputs(Seqlist_find_bydata(p,60),stdout);
puts("");
puts("");
Seqlist_destroy(&p);
printf("销毁后的得到指针地址是:%p\n",p);
} 当数据类型不再是简单的数据类型,而是结构体的时候,主函数调用上述函数模块的时候有以下要注意的点:
首先是将每个数据元素插入到顺序表中时,由于我自己定义的“按位置插入”的函数的形参是一个结构体,所以写的时候不能简单的传一个数据项(比如说只传成绩),而是传整个数据元素才行。
其次是返回值为char *类型的函数。要明确返回的只是一个字符串的首地址,直接printf是无法打印字符串的,但是接受首地址后可以用其他函数讲该字符串打印出来,因为字符串是存放在内存的常量区内的。但是这样为了返回需要打印的字符串,本身就失去了函数返回值的意义(不应该这么写代码)。
效果:

















 6595
6595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









