







python2和pythn3的区别
| python2 | python3 |
|---|---|
| input接收的是输入的类型 | input接收的都是字符串 |
| ASCII | UNICODE |
| 相对路径进行import | 绝对路径的方式进行 import |
| 旧式类 | 新式类(object) |
| 1 个 tab 和 8 个 space 是等价的 | 不可互相替代 |
python列表,元组,集合,字典的区别
列表:
支持索引切片成员操作符重复遍历
列表值类型可以不同
增删改查:
li.append('a')
service.extend(["b','c'])
service.insert(1,'d')
删:
li.pop()
li.pop(1)
li.remove('a')
改:
li[0] = 'e'
li[:2] = ['f','g']
元组:
支持索引切片成员操作符重复遍历
元组值类型可以不同
元祖的内容不支持更改,当元祖中有列表的时候支持更改。
只有一个值时,必须加‘,’才可以成为元组,
可以通过元组给多个变量赋值
元组没有排序,可以先变为列表,在排序
增:
a=(1,2,3)
b=(4,5)
print(a+b) #(1, 2, 3, 4, 5)
print(a*3) #(1, 2, 3, 1, 2, 3, 1, 2, 3)
删:
a=(1,2,3)
del a
print(a) #name ‘a’ is not defined 会报错
#***********
del a[1]
print(a) #报错,元组不支持元素单独项删除
集合:
集合里的元素不可重复。并且从小到大排列。
空集类型就变为了字典。
集合不支持,索引、切片、重复、连接,只支持成员操作符,遍历和枚举。
增删改查:
s.add(1)
s.update({5,3,2})
s.pop()
s.remove(6)
字典:
字典是一个键值对,他的key不是不可变的,如数字字符串,元组
只支持成员操作符和遍历
可以对多个key设置同一个值
增删改查:
services = {
'http':80,
'ftp':21,
'ssh':22
}
services['mysql'] = 3306
print(services)
services['http'] = 443
print(services)
批量更新:
services = {
'http':80,
'ftp':21,
'ssh':22
}
services_backup = {
'https':443,
'tomcat':8080,
'http':8080
}
services.update(services_backup)
services.pop('https')
services.popitem() 删除最后一个
查:
print(services.keys())
print(services.values())
print(services.items())
print(services['http'])
python 垃圾回收机制
- 引用计数:
- 标记删除
- 分代收集
小数据池和代码块
代码块
Python程序是由代码块构造的。块是一个python程序的文本,他是作为一个单元执行的。
代码块:一个模块,一个函数,一个类,一个文件等都是一个代码块。
而作为交互方式输入的每个命令都是一个代码块。
执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。
代码块的缓存机制:
- int(float):任何数字在同一代码块下都会复用。
- bool:True和False在字典中会以1,0方式存在,并且复用。
- str:几乎所有的字符串都会符合缓存机制,
- 非乘法得到的字符串都满足代码块的缓存机制:
- 乘数为1时,任何字符串满足代码块的缓存机制:
- 乘数>=2时:仅含大小写字母,数字,下划线,总长度<=20,满足代码块的缓存机制:
小数据池
目的:缓存我们字符串,整数,布尔值.在使用的时候不需要创建更多的对象,避免频繁的创建和销毁,提升效率,节约内存
不同代码块的缓存机制,也称为小整数缓存机制,前提是不在同一个代码块
缓存:int,str,bool
就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个池。
str:
1.长度小于等于1,直接缓存
2.长度大于1.字符串中如果只有数字,字母,下划线,就会缓存
3.乘于1.同上,乘于大于1的数.仅包含数字,字母,下划线,最终长度小于20会缓存
4.使用sys模块中的intern()缓存字符串来指定驻留。
int数字:
-5 ~ 256
布尔值:
True
False
a = 1000
b = 1000
print(id(a)) 利用id可以获得数据对象的内存地址
print(id(b))
print(a == b) == 是比较的两边的数值是否相等
print(a is b) is 是比较的两边的内存地址是否相等
输出:
2524884227984
2524884227984
True
True
看出内存地址相同。但是整型不是只有 -4~256才可以吗,就是代码块的功劳。因为两行在同一个文件中,属于同一个代码块,数字相同,所以代码块机制就将他们的id指向同一个。
小结
如果在同一代码块下,则采用同一代码块下的换缓存机制。
如果是不同代码块,则采用小数据池的驻留机制。
/pycharm 通过运行文件的方式执行下列代码: 这是在同一个文件下也就是同一代码块下,采用同一代码块下的缓存机制。
i1 = 1000
i2 = 1000
print(i1 is i2) /结果为True 因为代码块下的缓存机制适用于所有数字
通过交互方式中执行下面代码: /这是不同代码块下,则采用小数据池的驻留机制。
>>> i1 = 1000
>>> i2 = 1000
>>> print(i1 is i2)
False /不同代码块下的小数据池驻留机制 数字的范围只是-5~256.
/虽然在同一个文件中,但是函数本身就是代码块,
所以这是在两个不同的代码块下,不满足小数据池(驻存机制),则指向两个不同的地址。
def func():
i1 = 1000
print(id(i1)) # 2288555806672
def func2():
i1 = 1000
print(id(i1)) # 2288557317392
func()
func2()
range 和 xrange的区别
range 其实就是创建了一个list,需要在内存中保存所有的数据
xrange则是一个对象,它并没有保存这个list,而是计算出来的,他是一个生成器。
在范围不是很大时,二者的效率差不多,但当范围很大,或者经常break时,则使用xrange更合适
生成器,迭代器和装饰器
在python中,内部含有__Iter__方法并且含有__next__方法的对象就是迭代器。
话说py2时代,range()返回的是list,但如果range(10000000)的话,会消耗大量内存资源,所以,py2又搞了一个xrange()来解决这个问题。py3则只保留了xrange(),但写作range()。xrange()返回的就是一个迭代器,它可以像list那样被遍历,但又不占用多少内存。
generator(生成器)是一种特殊的迭代器,只能被遍历一次,遍历结束,就自动消失了。
总之,不管是迭代器还是生成器,都是为了避免使用list,从而节省内存。那么,如何得到迭代器和生成器呢?
python内置了迭代函数 iter,用于生成迭代器,用法如下:
str list tuple dic set range 为可迭代对象,因为他们的内部含有iter方法的对象,都是可迭代对象。
>>> a = [1,2,3]
>>> a_iter = iter(a)
>>> a_iter
<list_iterator object at 0x000001B2DE434BA8>
>>> for i in a_iter:
print(i, end=', ')
1, 2, 3,
yield 则是用于构造生成器的。比如,我们要写一个函数,返回从0到某正整数的所有整数的平方,传统的代码写法是这样的:
>>> def get_square(n):
result = list()
for i in range(n):
result.append(pow(i,2))
return result
>>> print(get_square(5))
[0, 1, 4, 9, 16]
但是如果计算1亿以内的所有整数的平方,这个函数的内存开销会非常大,这是 yield 就可以大显身手了:
>>> def get_square(n):
for i in range(n):
yield(pow(i,2))
>>> a = get_square(5)
>>> a
<generator object get_square at 0x000001B2DE5CACF0>
>>> for i in a:
print(i, end=', ')
0, 1, 4, 9, 16,
如果再次遍历,则不会有输出了。
“”"
装饰器:
把一个函数当作参数,返回一个替代版的函数
本质上就是一个返回函数的函数
“在不改变原函数的基础上,给函数增加功能”
放置于函数的上方,以@开头,加上定义的装饰器函数,就可以直接调用装饰器的函数,先运行装饰器函数,在运行已经定义的函数。
“”"
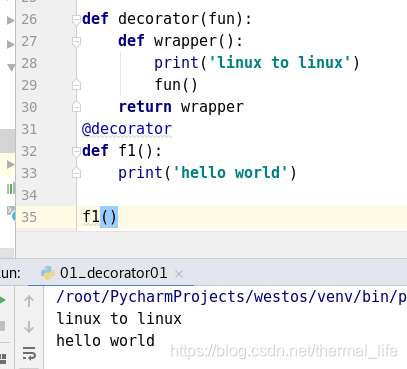
def decorator(fun):
def wrapper():
print('linux to linux')
fun()
return wrapper
@decorator #装饰器
def f1():
print('hello world')
f1()
三目运算
一般支持三目运算符的语言(如C语言)的语法格式一般是这样的:
判断条件(返回布尔值)?为真时的结果:为假时的结果
比如:
x = x%2==1 ? x+1:x;
python并不支持? :这种符号所表达的先判断再选择的含义,但仍然有相应的语法支持:
- Python 的语法支持
为真时的结果 if 判断条件 else 为假时的结果(注意,没有冒号)
顺序略有不同,
x = x+1 if x%2==1 else x
深拷贝和浅拷贝
首先,我们知道Python3中,有6个标准的数据类型,他们又分为可以变和不可变。
不可变:Number(数字)、String(字符串)、Tuple(元组)。
可以变:List(列表)、Dictionary(字典)、Set(集合)。
1、浅拷贝
使用copy模块里面的copy方法实现。对象地址改变,但里面的所有值地址不变。
改变原始对象中为可变类型的元素的值,会同时影响拷贝对象;
改变原始对象中为不可变类型的元素的值,不会响拷贝对象。
2、深拷贝
copy模块里面的deepcopy方法实现。
深拷贝,除了顶层拷贝,还对子元素也进行了拷贝。
原始对象和拷贝对象所有的可变元素地址都不一样了。但不可变元素地址仍相同
改变原始对象中所有类型的值,都不会影响拷贝对象。
断言assert
在测试用例中,执行完测试用例后,最后一步是判断测试结果是pass还是fail,自动化测试脚本里面一般把这种生成测试结果的方法称为断言(assert)。
常用的断言方法:
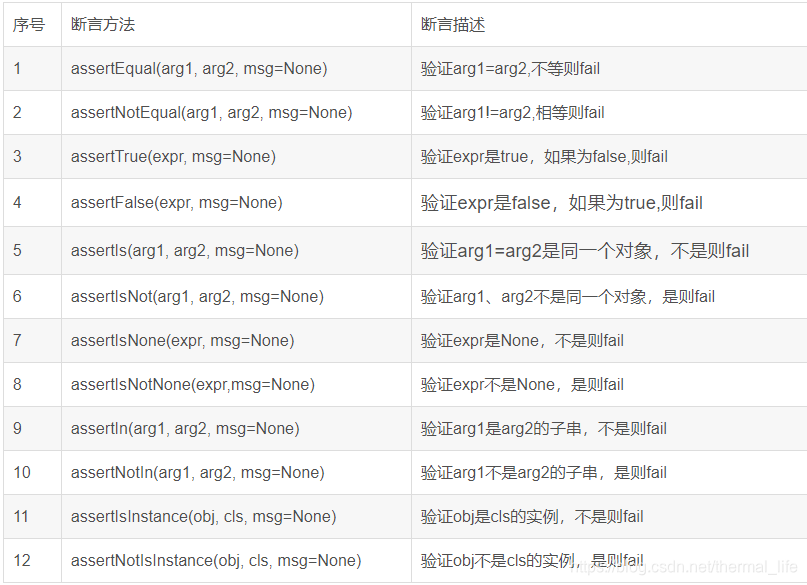
assert作用:断言函数是对表达式布尔值的判断,要求表达式计算值必须为真。可用于自动调试。如果表达式为假,触发异常;如果表达式为真,不执行任何操作。
assert(1==1)
输出:
可以看出什么都没有输出。
assert(1==1)
# assert(1==2)
assert(1>100)
输出:

就报错了。
对列表的断言:
a = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
b = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
assert(a == b)
正常,无输出。
python 抛出异常 raise Exception
一旦执行了raise语句,raise后面的语句将不能执行。
def printError(v):
if v == 2:
print('yes')
else:
raise Exception('Not exiests `V`.')
printError(2)
输出:
C:\Users\Administrator\PycharmProjects\pythonProject\venv\Scripts\python.exe C:/Users/Administrator/PycharmProjects/pythonProject/12-5/raise.py
yes
def printError(v):
if v == 2:
print('yes')
else:
raise Exception('Not exiests `V`.')
printError(3)
输出:

就会抛出异常。
time模块中的不同时间类型
元组类型:time.localtime()
时间戳类型:time.mktime() os.path.getctime(’/etc/shadow’) #unix的计算时间方式
字符串时间:time.strftime time.ctime
python中的 if __name__ == ‘__main__’ 的作用
对于很多编程语言来说,程序都必须要有一个入口,C 和 C++ 都需要有一个 main 函数来作为程序的入口,也就是程序的运行会从 main 函数开始。而 Python 则有不同,它属于脚本语言,不像编译型语言那样先将程序编译成二进制再运行,而是动态的逐行解释运行。也就是从脚本第一行开始运行,没有统一的入口。
一个 Python 源码文件除了可以被直接运行外,还可以作为模块(也就是库)被导入。不管是导入还是直接运行,最顶层的代码都会被运行(Python 用缩进来区分代码层次)。而实际上在导入的时候,有一部分代码我们是不希望被运行的。
我们就可以使用if __name__ == '__main__来实现。
通俗的理解__name__ == ‘__main__’:假如你叫小明.py,在朋友眼中,你是小明(__name__ == ‘小明’);在你自己眼中,你是你自己(__name__ == ‘__main__’)。
if name == 'main’的意思是:当.py文件被直接运行时,if name == 'main’之下的代码块将被运行;当.py文件以模块形式被导入时(from test import PI ,test是一个python文件,PI是这个文件中的一个变量),if name == 'main’之下的代码块不被运行。
python的内存池机制
Python提供了对内存的垃圾收集机制,但是它将不用的内存放到内存池而不是返回给操作系统。
1,Pymalloc机制。为了加速Python的执行效率,Python引入了一个内存池机制,用于管理对小块内存的申请和释放。
2,Python中所有小于256个字节的对象都使用pymalloc实现的分配器,而大的对象则使用系统的malloc。
3,对于Python对象,如整数,浮点数和List,都有其独立的私有内存池,对象间不共享他们的内存池。也就是说如果你分配又释放了大量的整数,用于缓存这些整数的内存就不能再分配给浮点数。
python多线程
threading模块
python多线程详解
Python中的编码
ASCII : 最早的编码. ⾥⾯有英⽂⼤写字⺟, ⼩写字⺟, 数字, ⼀些特殊字符. 没有中⽂, 8个01代码, 8个bit, 1个byte
GBK: 中⽂国标码, ⾥⾯包含了ASCII编码和中⽂常⽤编码. 16个bit, 2个byte
UNICODE: 万国码, ⾥⾯包含了全世界所有国家⽂字的编码. 32个bit, 4个byte, 包含了 ASCII
UTF-8: 可变⻓度的万国码. 是unicode的⼀种实现. 最⼩字符占8位 1.英⽂: 8bit 1byte 2.欧洲⽂字:16bit 2byte 3.中⽂:24bit 3byte
综上, 除了ASCII码以外, 其他信息不能直接转换. 在python3的内存中. 在程序运⾏阶段. 使⽤的是unicode编码. 因为unicode是万国码. 什么内容都可以进⾏显⽰. 那么在数据传输和存储的时候由于unicode比较浪费空间和资源. 需要把 unicode转存成UTF-8或者GBK进⾏存储. 怎么转换呢. 在python中可以把⽂字信息进⾏编码. 编码之后的内容就可以进⾏传输了. 编码之后的数据是bytes类型的数据.其实啊. 还是原来的 数据只是经过编码之后表现形式发⽣了改变⽽已.
s = "alex"
print(s.encode("utf-8")) # 将字符串编码成UTF-8
print(s.encode("GBK")) # 将字符串编码成GBK
s = "中"
print(s.encode("UTF-8")) # 中⽂编码成UTF-8
print(s.encode("GBK")) # 中⽂编码成GBK
结果:
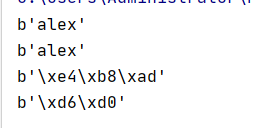
可见,英⽂编码之后的结果和源字符串⼀致. 中⽂编码之后的结果根据编码的不同. 编码结果也不同。
⼀个中⽂的UTF-8编码是3个字节. ⼀个GBK的中⽂编码是2个字节.
编码之后的类型就是bytes类型. 在⽹络传输和存储的时候我们python是发送和存储的bytes 类型.
那么在对⽅接收的时候. 也是接收的bytes类型的数据.
我们可以使⽤decode()来进⾏解码操作.
s = "我叫李嘉诚"
print(s.encode("utf-8")) #
b'\xe6\x88\x91\xe5\x8f\xab\xe6\x9d\x8e\xe5\x98\x89\xe8\xaf\x9a'
print(b'\xe6\x88\x91\xe5\x8f\xab\xe6\x9d\x8e\xe5\x98\x89\xe8\xaf\x9a'.decode("utf-8")) # 解码
结果:

可以使用decode进行解码,编码和解码的时候都需要制定编码格式.
s = "我是⽂字"
bs = s.encode("GBK") #编码
s = bs.decode("GBK") # 解码,把GBK解码为unicode格式
bss = s.encode("UTF-8") # 重新编码
print(bss)
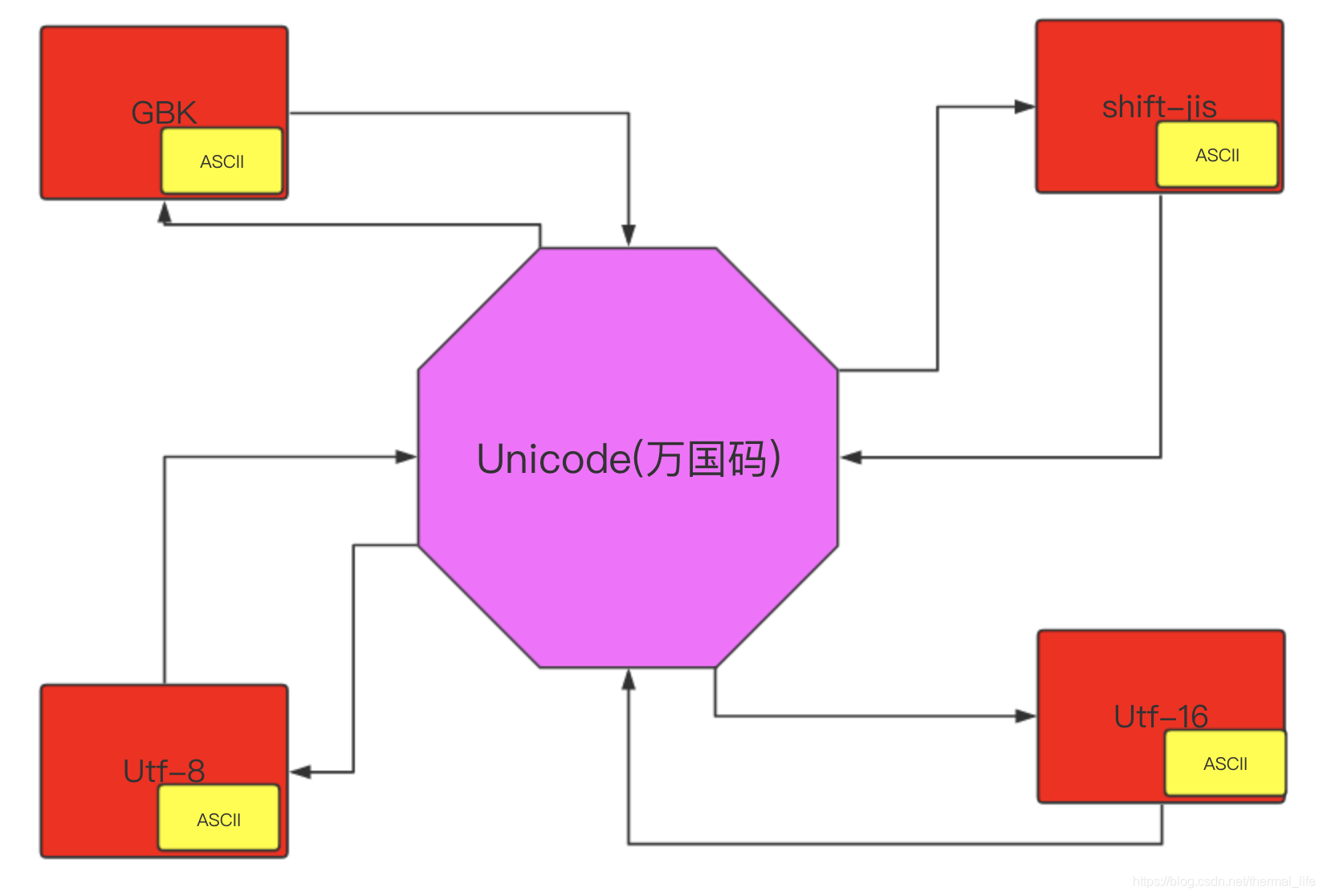
Unicode就相当于他们之间的桥梁,可以实现他们之前相互编码,但是我们在编码和解码的时候必须使用同一个密码本.
Python中读取文件的绝对路径和相对路径
相对路径:同一个文件夹下面的文件,直接写文件名就可以。
f = open('护士少妇萝莉',mode='rb')
绝对路径:从根目录下开始一直到文件名。
我们在使用绝对路径的时候因为有\这样程序是不能识别的,解决方法:
open('C:\Users\Meet') /这样程序是不识别的
解决方法一:
open('C:\\Users\\Meet') /这样就成功的将\进行转义 两个\\代表一个\
解决方法二:
open(r'C:\Users\Meet') /这样相比上边的还要省事,在字符串的前面加个小r也是转义的意思 推荐使用这种
Python中读取文件的各种模式
| 模式 | 描述 |
|---|---|
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。 |
| w | 打开一个文件只用于写入。如果该文件已存在则将其覆盖(等于清空文件内容在重写)。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。 |
可以看出b模式是只读字节的模式,以二进制的方式显示。
f = open('护士少妇萝莉',mode='rb') /rb 读出来的数据是bytes类型,在rb模式下,不能encoding字符集
f = open(联系方式.txt',mode='r',encoding='utf-8') /不加b的模式就可以指定字符集
我们可以用with open 来打开,这样更安全。
with open(r'C:\Users\Administrator\Desktop\新建文本文档.txt','r') as f:
print(f.read())
with open(r'C:\Users\Administrator\Desktop\新建文本文档.txt','r',encoding='UTF-8') as f:
print(f.read())
结果:

为windows系统中记事本中写的内容编码是GBK,所以打开会有问题,我们可以通过参数进行修改。
with open(r'C:\Users\Administrator\Desktop\新建文本文档.txt','rb') as f: /rb以二进制方式显示
print(f.read())

python中的格式化输出
wo = '曹源'
age = 18
addr = '刘妍市临潼区'
print('我叫%s,今年%d岁了,我来自%s' %(wo,age,addr)) /第一种方式
msg = f'我叫{wo},今年{age}岁了,我来自{addr}' /第二种方式
// msg = F'我叫{wo},今年{age}岁了,我来自{addr}' /用大F也可以
print(msg)

可见输出的结果都是一样的。
第二种方式是python3.6引入的标准库的格式化输出新的写法,f-strings字符串格式化,这个格式化输出比之前的%s 或者 format 效率高并且更加简化,非常的好用。
其他用法:
print(f'计算3*21:{3*21}')
name = 'barry'
print(f'全部大写:{name.upper()}')
# 字典也可以
teacher = {'name': '宝元', 'age': 18}
msg = f"The teacher is {teacher['name']}, aged {teacher['age']}"
print(msg)
# 列表也行
l1 = ['宝元', 18]
msg = f'姓名:{l1[0]},年龄:{l1[1]}.'
print(msg)

多行F:
name = 'barry'
age = 18
ajd = 'handsome'
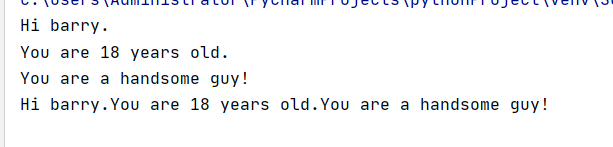
speaker1 = f'''Hi {name}.
You are {age} years old.
You are a {ajd} guy!'''
speaker2 = f'Hi {name}.'\
f'You are {age} years old.'\
f'You are a {ajd} guy!'
print(speaker1)
print(speaker2)
其他细节:
print(f"{{73}}") # {73}
print(f"{{{73}}}") # {73}
print(f"{{{{73}}}}") # {{73}}
m = 21
/ ! , : { } ;这些标点不能出现在{} 这里面。
/ print(f'{;12}') # 报错
/ 所以使用lambda 表达式会出现一些问题。
/ 解决方式:可将lambda嵌套在圆括号里面解决此问题。
x = 5
print(f'{(lambda x: x*2) (x)}') # 10


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









