







聚集函数可用来汇总数据,如果我们要对这些数据进行分组处理的话,就需要我们进行数据的分组。
数据分组group by
MariaDB [test]> select * from linux ;
+-------+--------+------+------+-------+------------+
| user | passwd | sex | age | price | math_price |
+-------+--------+------+------+-------+------------+
| user2 | 222 | girl | 23 | 155 | 36 |
| user3 | 333 | boy | 12 | 78 | 66 |
| user4 | 444 | boy | 22 | NULL | NULL |
| user5 | 555 | boy | 30 | NULL | 43 |
| a | passa | boy | 22 | NULL | NULL |
| 1 | pass1 | girl | 30 | NULL | NULL |
| user1 | 111 | boy | -18 | 35 | 88 |
| user6 | 666 | girl | 16 | 35 | 43 |
+-------+--------+------+------+-------+------------+
8 rows in set (0.00 sec)
MariaDB [test]> select count(*) from linux;
+----------+
| count(*) |
+----------+
| 8 |
+----------+
1 row in set (0.00 sec)
MariaDB [test]> select count(*),sex from linux group by sex;
+----------+------+
| count(*) | sex |
+----------+------+
| 5 | boy |
| 3 | girl |
+----------+------+
2 rows in set (0.00 sec)
这样就统计出了总人数中男女分别的数量
MariaDB [test]> select count(*),sex from linux group by sex with rollup;
+----------+------+
| count(*) | sex |
+----------+------+
| 5 | boy |
| 3 | girl |
| 8 | NULL |
+----------+------+
3 rows in set (0.00 sec)
使用WITH ROLLUP关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值。
过滤分组HAVING子句。
WHERE子句并没有分组的概念
学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
MariaDB [test]> select count(*),sex from linux group by sex where conut(*) > 3;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MariaDB server version for the right syntax to use near 'where conut(*) > 3' at line 1
MariaDB [test]> select count(*),sex from linux group by sex having count(*) > 3;
+----------+-----+
| count(*) | sex |
+----------+-----+
| 5 | boy |
+----------+-----+
1 row in set (0.04 sec)
MariaDB [test]> select count(*),sex from linux group by sex having count(*) > 2;
+----------+------+
| count(*) | sex |
+----------+------+
| 5 | boy |
| 3 | girl |
+----------+------+
2 rows in set (0.00 sec)
我们可以看到用where进行过滤的时候会报错,但是我们用having的时候则可以过滤,就说明having是用于过滤分组的。
HAVING和WHERE的差别:
WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重
要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
MariaDB [test]> select count(*),sex from linux where age> 22 group by sex ;
+----------+------+
| count(*) | sex |
+----------+------+
| 1 | boy |
| 2 | girl | /WHERE排除的行不包括在分组中
+----------+------+
2 rows in set (0.00 sec)
MariaDB [test]> select count(*),sex from linux where age> 22 group by sex having count(*)>2;
Empty set (0.00 sec)
MariaDB [test]> select count(*),sex from linux where age> 22 group by sex having count(*)>1;
+----------+------+
| count(*) | sex |
+----------+------+
| 2 | girl |
+----------+------+
1 row in set (0.00 sec)
分组和排序

一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。
MariaDB [test]> select sum(age),sex from linux group by sex having sum(age) >= 68;
+----------+------+
| sum(age) | sex |
+----------+------+
| 104 | boy |
| 69 | girl |
+----------+------+
2 rows in set (0.00 sec)
MariaDB [test]> select sum(age),sex from linux group by sex having sum(age) >= 68 order by sum(age);
+----------+------+
| sum(age) | sex |
+----------+------+
| 69 | girl |
| 104 | boy |
+----------+------+
2 rows in set (0.00 sec)
SELECT子句使用顺序
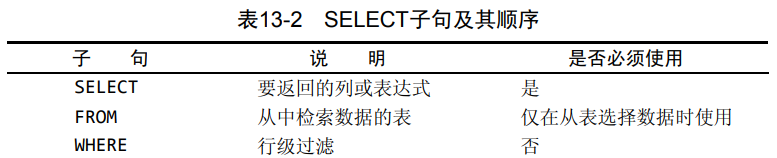

select _ from _ where _ group by _ habing _ order by _ limit


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









