




 本文详细介绍了Hive中的Join操作,包括内连接、外连接、半连接的不同应用场景及语法结构,同时提供了实例演示,帮助读者深入理解Hive的连接机制。
本文详细介绍了Hive中的Join操作,包括内连接、外连接、半连接的不同应用场景及语法结构,同时提供了实例演示,帮助读者深入理解Hive的连接机制。
Hive的Join操作
1,语法结构
join_table:
table_reference JOIN table_factor [join_condition]| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition| table_reference LEFT SEMI JOIN table_reference join_condition
(1)Hive 支持等值连接(equality join)、外连接(outer join)和 左半连接(left semi join)。
(2)Hive 不支持非等值的连接,因为非等值连接非常难转化到 Map/Reduce 任务。
(3)另外, Hive 支持多于 2 个表的连接。
2,写查询时要注意以下几点:
1,Hive 只支持等值连接,不支持非等值的连接
- 等值连接示例:SELECT a.* FROM a JOIN b ON (a.id = b.id);
- 非等值连接示例:SELECT a.* FROM a JOIN b ON (a.id > b.id); <错误>
2,Hive 支持多于 2 个表的连接
若是Join中多个表的join key 为同一个,则Join 会被转化为单个 Map/Reduce 任务。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1);
#被转化为单个 Map/Reduce 任务,因为 Join 中只使用了 b.key1 作为 join key
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);
#Join 被转化为 2 个 Map/Reduce 任务。因为 b.key1 用于第一次 Join 条件,而 b.key2 用于第二次 Join
3,Join 时应把最大表放在最后
Reducer 会缓存 Join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在 Reduce 端减少内存的使用量。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1);
#所有表都使用同一个 join key,单个 M/R 任务,Reduce 端会缓存 a、b 表的记录,然后每次取得一个 c 表的记录就计算一次 Join 结果
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);
#2个 M/R 任务,第一次缓存 a 表,用 b 表序列化;第二次缓存第一次 M/R 任务的结果,用 c 表序列化
2,数据准备
1,创建两张表
studenta
CREATE TABLE studenta(
id INT,
name STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
字段id、name
列分隔符“\t”
studentb
CREATE TABLE studentb(
id INT,
age INT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t';
字段id、age
列分隔符“\t”
2,准备数据
vim studenta.txt
10001 shiny
10002 mark
10003 angel
10005 ella
10009 jack
10014 eva
10018 judy
10020 cendy
vim studentb.txt
10001 23
10004 22
10007 24
10008 21
10009 25
10012 25
10015 20
10018 19
10020 26
3,导入数据
LOAD DATA LOCAL INPATH '/home/shiny/Desktop/test/studenta.txt' INTO TABLE studenta;
LOAD DATA LOCAL INPATH '/home/shiny/Desktop/test/studentb.txt' INTO TABLE studentb;
4,查看表中数据
select * from studenta;
select * from studentb;
4,Join详解
1,内连接(INNER JOIN)
JOIN(内连接)
-
作用
把符合两边连接条件的数据查询出来 -
示例
SELECT * FROM studenta a JOIN studentb b
ON a.id=b.id;
2,外连接(OUTER JOIN)
LEFT JOIN(左外连接)
-
作用
(1)以左表数据为匹配标准,左大右小;
(2)匹配不上的就是 null;
(3)返回的数据条数与左表相同。 -
示例
SELECT * FROM studenta a LEFT JOIN studentb b ON a.id=b.id;
RIGHT JOIN(右外连接)
-
作用
(1)以右表数据为匹配标准,左小右大;
(2)匹配不上的就是 null;
(3)返回的数据条数与右表相同。 -
示例
SELECT * FROM studenta a RIGHT JOIN studentb b ON a.id=b.id;
FULL JOIN(全外连接)
-
作用
(1)以两个表的数据为匹配标准;
(2)匹配不上的就是 null;
(3)返回的数据条数等于两表数据去重之和。 -
示例
SELECT * FROM studenta a FULL JOIN studentb b ON a.id=b.id;
3,半连接( SEMIN JOIN)
LEFT SEMI JOIN(左半连接)
-
作用
(1)把符合两边连接条件的左表的数据显示出来。
(2)右表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行。因为如果连接语句中有WHERE子句,会先执行JOIN子句,再执行WHERE子句。 -
示例
SELECT * FROM studenta a LEFT SEMI JOIN studentb b ON a.id=b.id;
Hive的数据类型
原子数据类型
1,数值类型
- (1)整数类型
与Java中的数据类型相对应数据类型 大小 TINYINT Byte,1字节 SMALLINT Short,2字节 INT Int,4字节 BIGINT Long,8字节
-(2)浮点数据类型
与Java中的数据类型相对应数据类型 大小 LOAT Float,4字节 OUBLE Double,8字节
2,布尔类型
| BOOLEAN | Boolean,true/false |
|---|
3,字符串类型
| STRING | Varchar,可变的字符串,不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数 |
|---|---|
| VARCHAR | Varchar,可变的字符串,长度上只允许在1-65355之间 |
| CHAR | Char,固定长度字符串,最大长度为255 |
与数据库中的数据类型相对应
4,日期时间类型
- TIMESTAMP
时间戳 - DATE
- 描述特定的年月日,以YYYY-MM-DD格式表示,例如2015-05-29
- DATE类型不包含时间,所表示日期的范围为0000-01-01 to 9999-12-31
- DATE类型仅可与DATE、TIMESTAMP、STRING类型相互转化
复杂数据类型
1简介
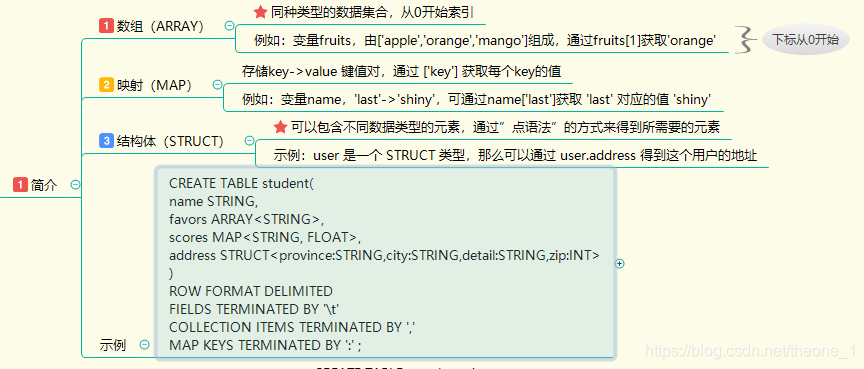
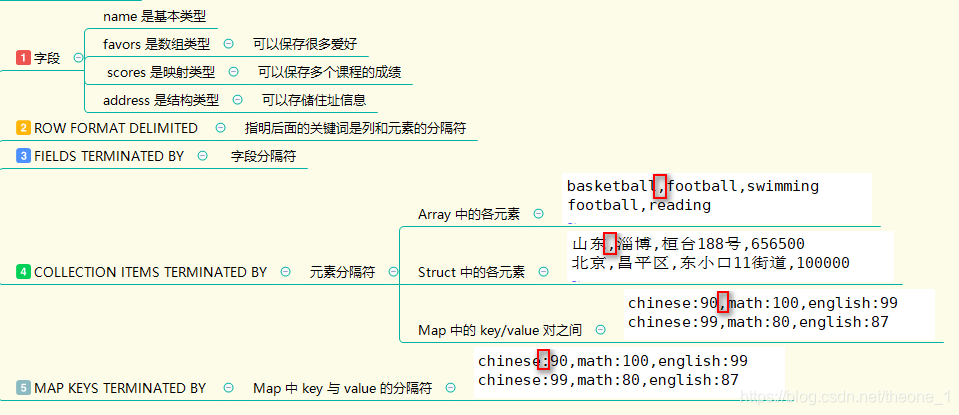
2操作
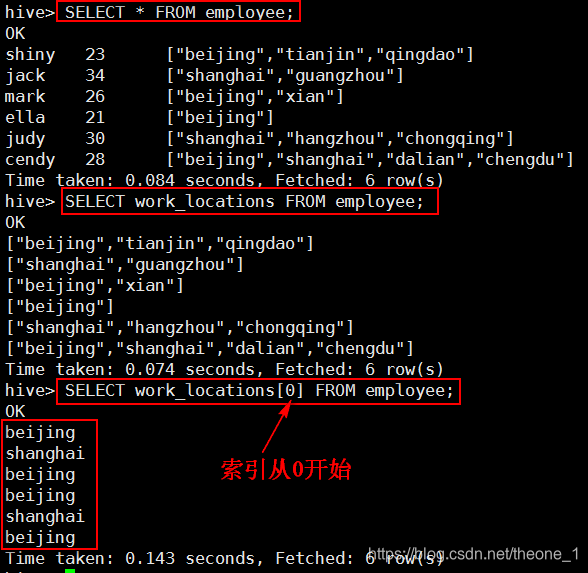
- ARRAY
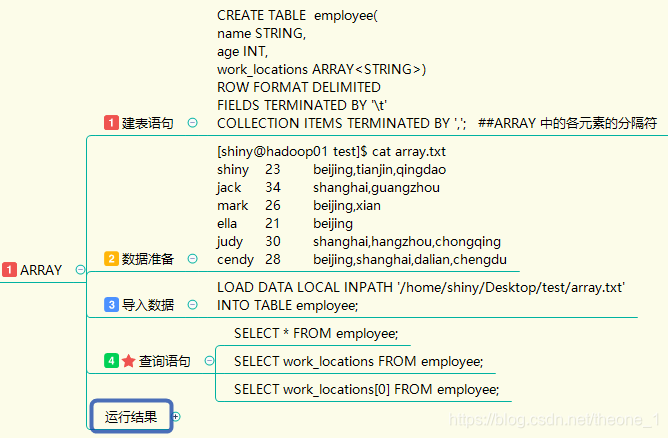
运行结果:
-MAP
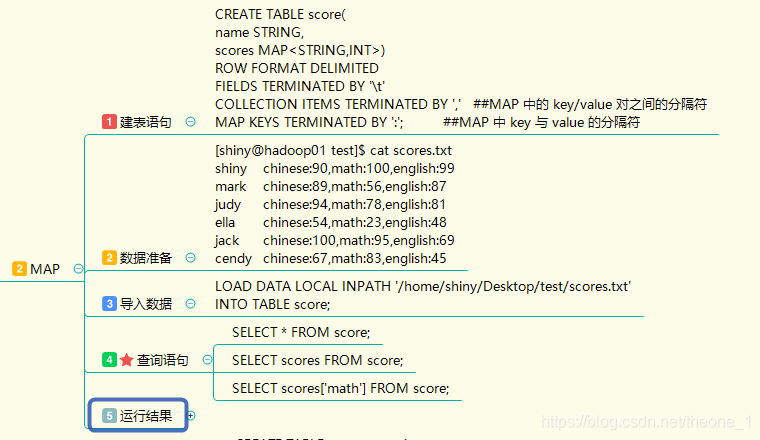
运行结果:
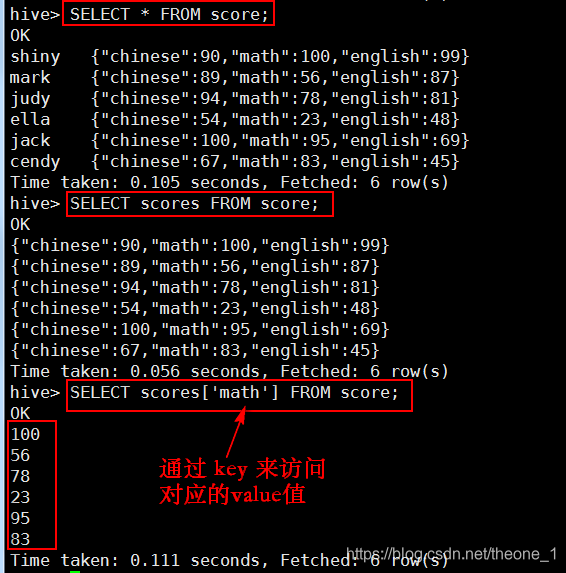
- STRUCT

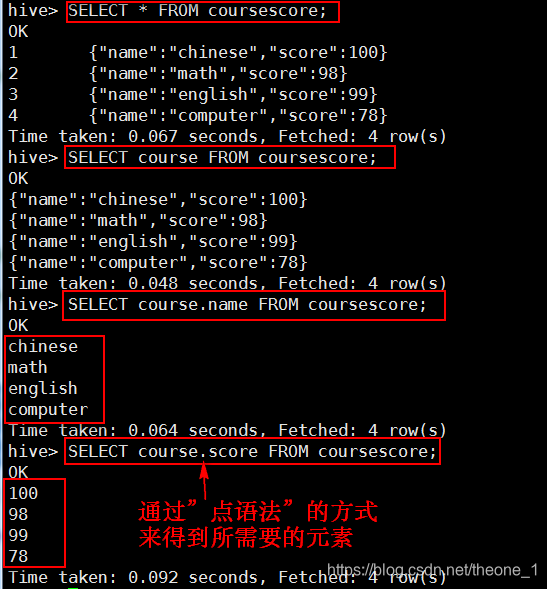
3,Hive函数
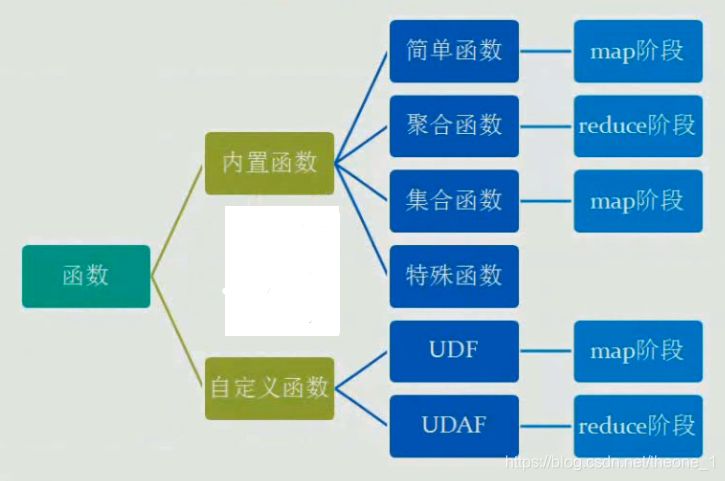
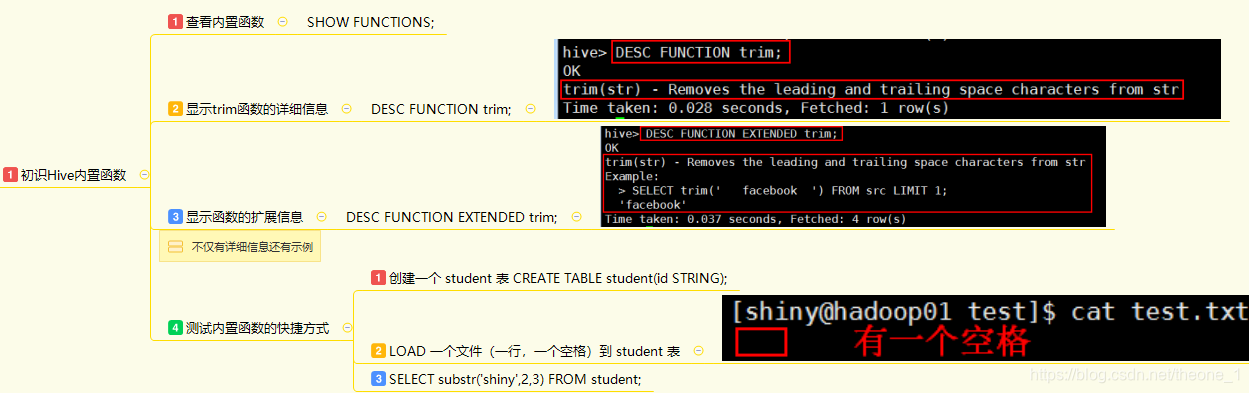
Hive内置函数
内置函数
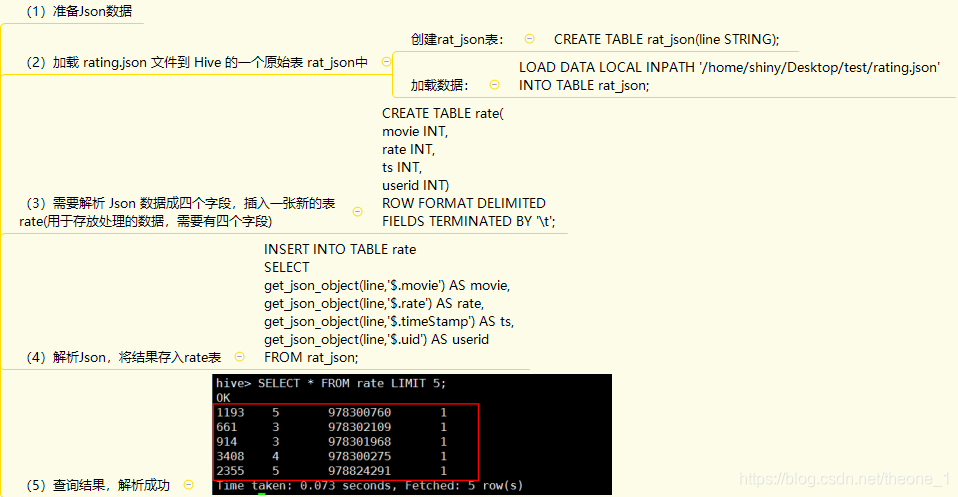
Json数据解析
- 原始数据样例
{“movie”:“1193”,“rate”:“5”,“timeStamp”:“978300760”,“uid”:“1”} - 将数据导入Hive,最终展现结果:

具体实现
1.内置函数:get_json_object实现
2.自定义函数UDF
(1)新建一个项目HiveDemo,导入%HVIE_HOME%/lib下的jar包
(2)开发 Java 类,继承 org.apache.hadoop.hive.ql.exec.UDF,重载 evaluate 方法
//解析Json格式数据
public class JsonUDF extends UDF{
//使用evaluate方法来实现特定的功能,必须要返回类型值,空的话返回null,不能为void类型。
public String evaluate(String jsonStr,String field) throws JSONException{
//将字符串转换成JSONObject对象
JSONObject json=new JSONObject(jsonStr);
//get(String key) :获取与某个键关联的值对象
String result=(String) json.get(field);
return result;
}
}
evaluate 方法必须有返回值
(3)打 jar 包,上传至 Linux 服务器
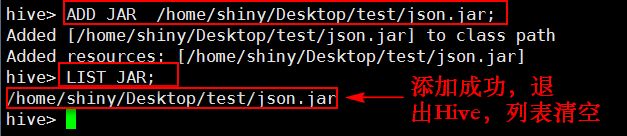
(4)将jar包添加到Hive的classpath下
hive> ADD JAR /home/shiny/Desktop/test/json.jar;
hive> LIST JAR; ##查看jar包是否加入成功
(5)创建临时函数与开发好的 class 关联起来
hive> CREATE TEMPORARY FUNCTION jsontostring AS 'com.shiny.hive.udf.JsonUDF';
jsontostring :临时函数的名字
com.shiny.hive.udf.JsonUDF:包名.类名
(6)解析 Json 数据,将结果存入rates表
CREATE TABLE rates
AS SELECT
jsontostring(line,'movie') AS movie,
jsontostring(line,'rate') AS rate,
jsontostring(line,'timeStamp') AS ts,
jsontostring(line,'uid') AS userid
FROM rat_json;
通过键 ‘movie’ 获取其对应的值
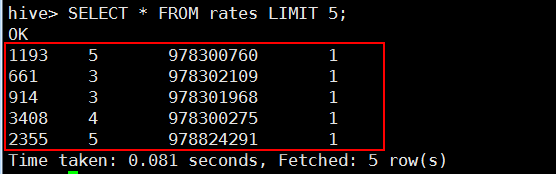
(7)查询验证
SELECT * FROM rates LIMIT 5;
Hive自定义函数

4,Hive Shell 操作
1,交互模式
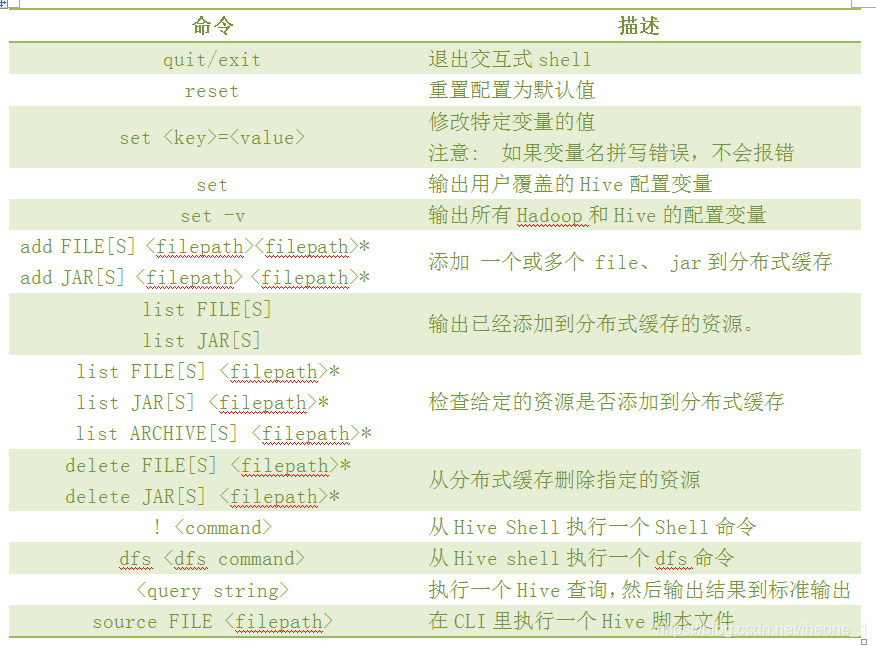
- Hive 交互模式下支持的一些命令
quit / exit、reset、set、create、add、delete等
2,非交互模式
(1)语法结构
hive [-hiveconf x=y]* [<-i filename>]* [<-f filename>|<-e query-string>] [-S]
(2)语法说明
- (1)-i:从文件初始化 HQL
- (2)-e:从命令行执行指定的 HQL
- (3)-f:执行 HQL 脚本
- (4)-v:输出执行的 HQL 语句到控制台
- (5)-p: connect to Hive Server on port number
- (6)-hiveconf x=y(Use this to set hive/hadoop configuration variables)
- (7)-S:表示以不打印日志的形式执行命名操作
(3)示例
-
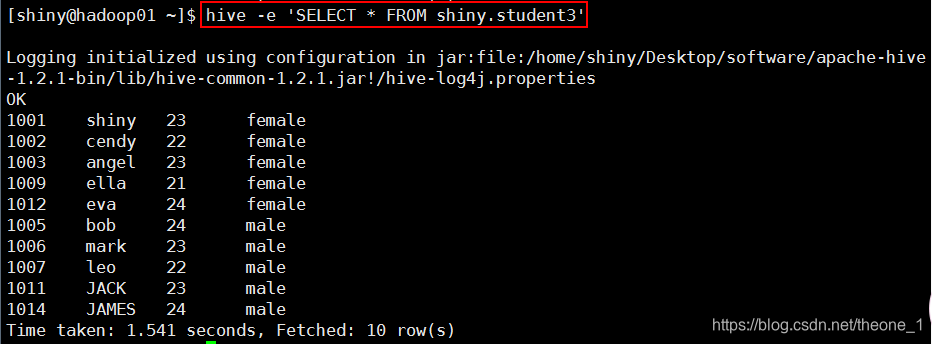
(1)从命令行执行一个 HQL 查询
hive -e 'SELECT * FROM shiny.student3' -
-
(2)从命令行执行一个查询命令脚本
新建 hive.sql,内容为 SELECT * FROM shiny.student3
执行 HQL 脚本:hive -f hive.sql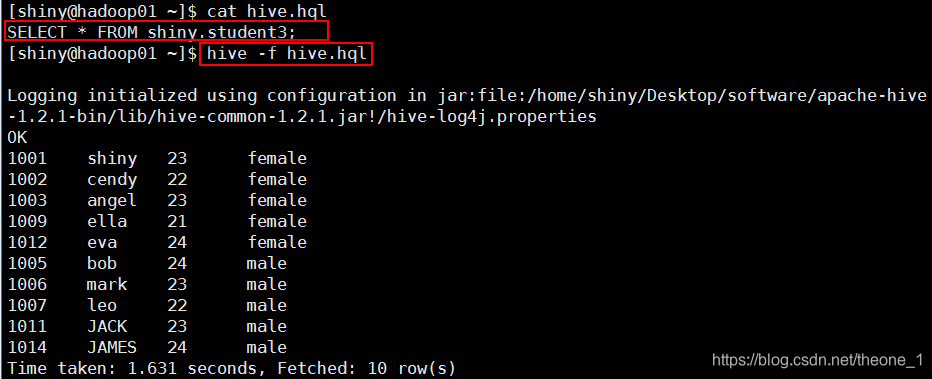
-
(3)从命令行执行一个参数脚本
新建 inithive.conf,内容为 SET mapreduce.job.reduces=3;
执行 HQL 脚本:hive -i inithive.conf

















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









