




本文目录
一、HTTP协议介绍
HTTP协议:超文本传输协议(Hypertext Transfer Protocol)。超文本协议就是传输多种数据在网络上(比如图片、视频等)。是一种用于分布式、协作式超媒体信息系统的应用层协议,主要用于在互联网上实现客户端与服务器之间的通信。以下是关于HTTP协议的详细介绍:
前后端分离的时候比较经典的是HTTP协议及框架。
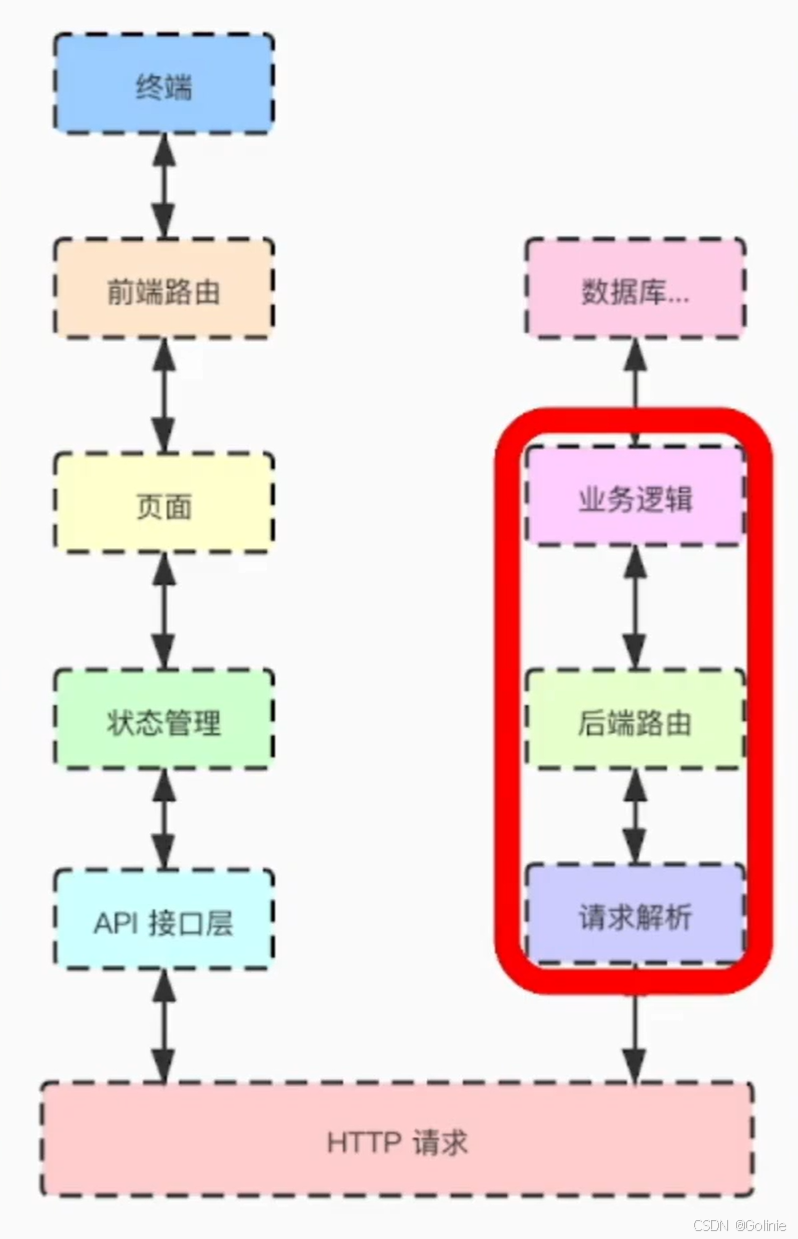
为什么需要协议呢,因为首先传输的时候,需要知道一个明确的边界,也就是信息Text是什么时候开始的,又是什么时候结束的。
另外就是需要明确这个协议能够携带什么信息:消息类型、什么消息等。

HTTP1.1协议
在HTTP/1.1中,队头阻塞是一个关键问题。由于HTTP/1.1是基于TCP协议的,每个请求和响应都需要在TCP连接上按顺序处理。如果一个请求被阻塞(例如,由于服务器处理延迟或网络问题),后续的所有请求也会被延迟。这种现象称为“队头阻塞”。也就是HTTP/1.1的请求和响应是基于文本的,且每个请求必须等待前一个请求完成才能发送。
另外就是传输效率低。请求头冗余:每个请求都包含大量的重复信息(如Host、User-Agent等),这些信息在多个请求中重复传输,浪费了带宽。连接管理:尽管HTTP/1.1引入了持久连接(Keep-Alive),但仍然无法避免连接的频繁建立和关闭,增加了开销。串行处理:由于队头阻塞,多个请求无法并行处理,导致资源加载时间延长。
HTTP/1.1默认使用明文传输,这意味着数据在传输过程中可能会被窃听或篡改(数据泄露、中间人攻击等安全问题。)。虽然可以通过HTTPS(HTTP + TLS)来解决安全问题,但HTTP/1.1本身并不支持加密。
HTTP/1.1不支持多路复用,即一个TCP连接在同一时间内只能处理一个请求。这导致了多个请求需要排队等待处理,进一步加剧了队头阻塞问题。
HTTP2协议
HTTP/2引入了多路复用技术,允许在同一个TCP连接上并行传输多个请求和响应。这意味着多个资源可以同时加载,而不会相互阻塞。HTTP/2将数据分割成多个帧(Frame),每个帧可以独立传输,从而实现并行处理。
HTTP/2采用了HPACK算法对请求和响应头进行压缩,减少了头信息的冗余传输。
HTTP/2使用二进制格式而不是文本格式来传输数据。二进制协议的解析更加高效,减少了解析错误的可能性。相比HTTP/1.1的文本协议,二进制协议更加紧凑,解析速度更快。
但是依然存在下面的这些问题:
队头阻塞:虽然HTTP/2在应用层解决了队头阻塞问题,但TCP协议本身的队头阻塞问题依然存在。
握手开销:TCP的三次握手和TLS的握手过程仍然会引入延迟,尤其是在高延迟网络环境下。
HTTP3与QUIC
HTTP/3 是基于 QUIC 协议实现的下一代HTTP协议。
它继承了HTTP/2的多路复用、头部压缩等特性,并通过QUIC解决了TCP的队头阻塞和握手延迟问题。
HTTP/3的目标是进一步提升网络传输效率和用户体验,尤其是在高延迟和不稳定的网络环境中。
QUIC在协议层面集成了TLS加密,减少了握手的开销。它通过预共享密钥(PSK)等机制,实现了快速连接建立。QUIC支持零往返时间(0-RTT)连接,这意味着客户端可以在第一次发送请求时就携带数据,而无需等待服务器的响应。
二、一个常见的POST请求
这里我们可以看看常见的POST请求在协议层到底做了什么?
POST /sis HTTP/1.1
Who:Alex
Content-Type:text/plain
HOST:127.0.0.1:8888
Content-Length:28
This is Content.
简单来说,POST代表了HTTP请求方法。
/sis表示的是URL请求路径,表示客户端请求的资源位置。服务器会根据这个路径找到对应的资源或者处理逻辑,也就是可以理解成一个特定的接口或者页面路径。
HTTP1.1是目前比较广泛的版本,支持持久连接、管道化等特性。
协议元数据就是从Who开始的这一行到Content-Length这一行结束,协议元数据结束后加一个换行,就到了真正的传输内容,传输内容结束之后,再加一个换行,就代表POST请求结束。
据此得到的回复可以如下:
HTTP/1.1 200 OK
Server:hertz
Data:Thu,21,Apr 2022 11:46 GMT
Content-Type:text/plain;charset=utf-8
Content-Length:2
Upstream-Caught:165052492834329
OK
所以可以总结就是,第一行是 请求行/状态行,然后就是对应的请求头/响应头。最后就是 请求体/响应体。
- 请求行:方法名(POST、GET、HEAD、PUT、DELETE、CONTENT、OPTIONS、TRACE、PATCH等)、URL、协议版本。
PATCH是HTTP1.1后新增的,PUT请求通常用于完全替换目标资源的内容。客户端需要提供完整的资源表示,而不是部分更新。PUT是幂等的,即多次执行相同的操作结果相同。例如,多次发送相同的PUT请求,资源的最终状态是相同的。PATCH请求用于对资源进行部分更新。客户端只需要发送需要修改的部分数据,而不是完整的资源表示。PATCH通常是非幂等的,因为多次执行相同的操作可能会导致不同的结果。例如,多次对一个字段进行增量更新可能会导致不同的最终值。
- 状态码:1xx: 信息类、2xx:成功、3xx:重定向、4xx:客户端错误、5xx:服务端错误。
三、简单demo实现
package main
import (
"context"
"github.com/cloudwego/hertz/pkg/app"
"github.com/cloudwego/hertz/pkg/app/server"
)
func main() {
h := server.New()
h.POST("/sis", func(c context.Context, ctx *app.RequestContext) {
ctx.Data(200, "text/plain;charset=UTF-8", []byte("ok"))
})
h.Spin()
}
- github.com/cloudwego/hertz/pkg/app/server: 提供创建服务器实例的功能,允许开发者定义路由规则并启动HTTP服务
- github.com/cloudwego/hertz/pkg/app: 定义了处理请求上下文的核心接口 RequestContext 和 Context 接口,用于访问 HTTP 请求/响应对象以及操作头部信息等。
然后我们run这个go代码,并用apipost接口工具进行请求,可以完成请求并得到对应的返回内容ok。
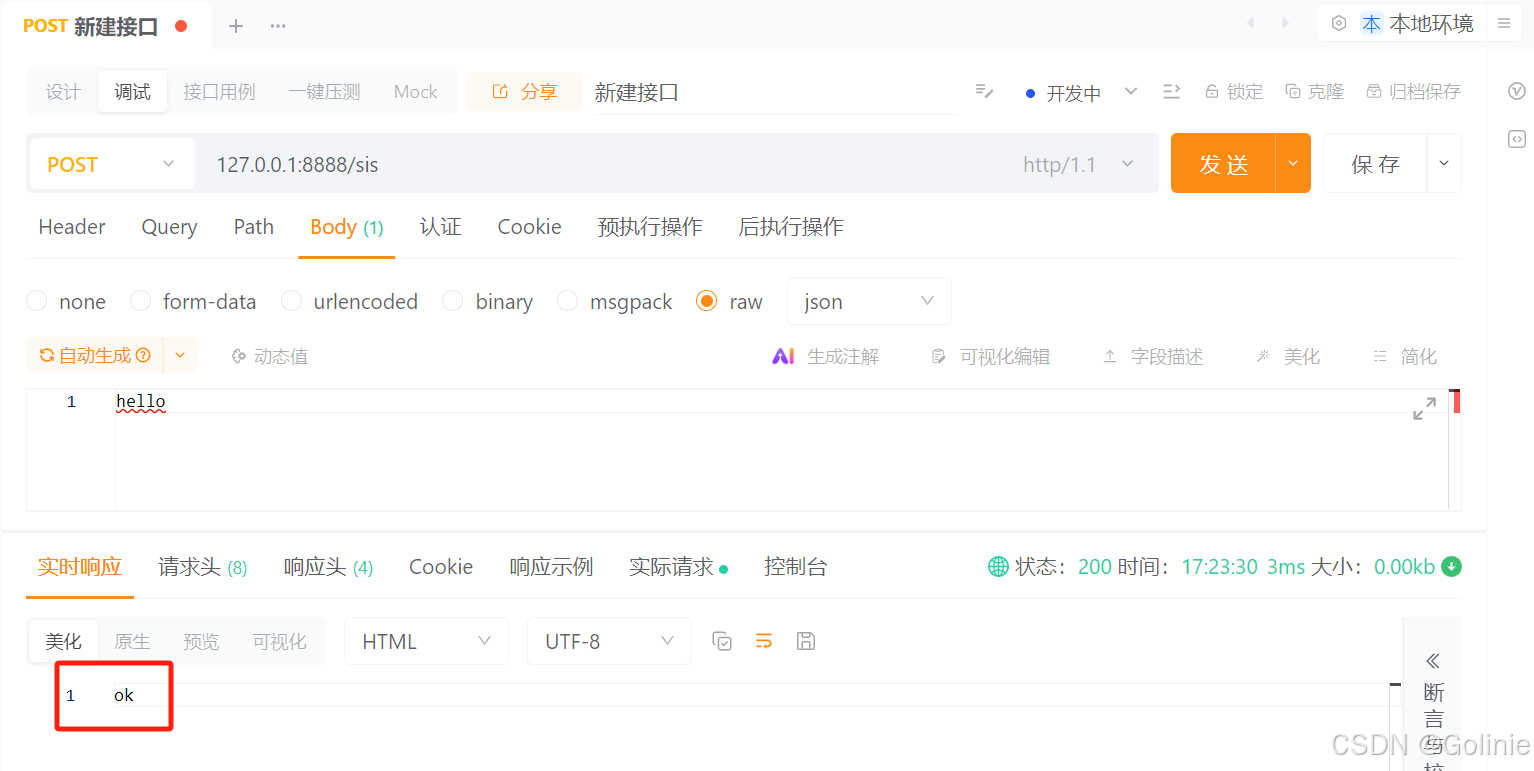
接下来我们详细看看请求流程。
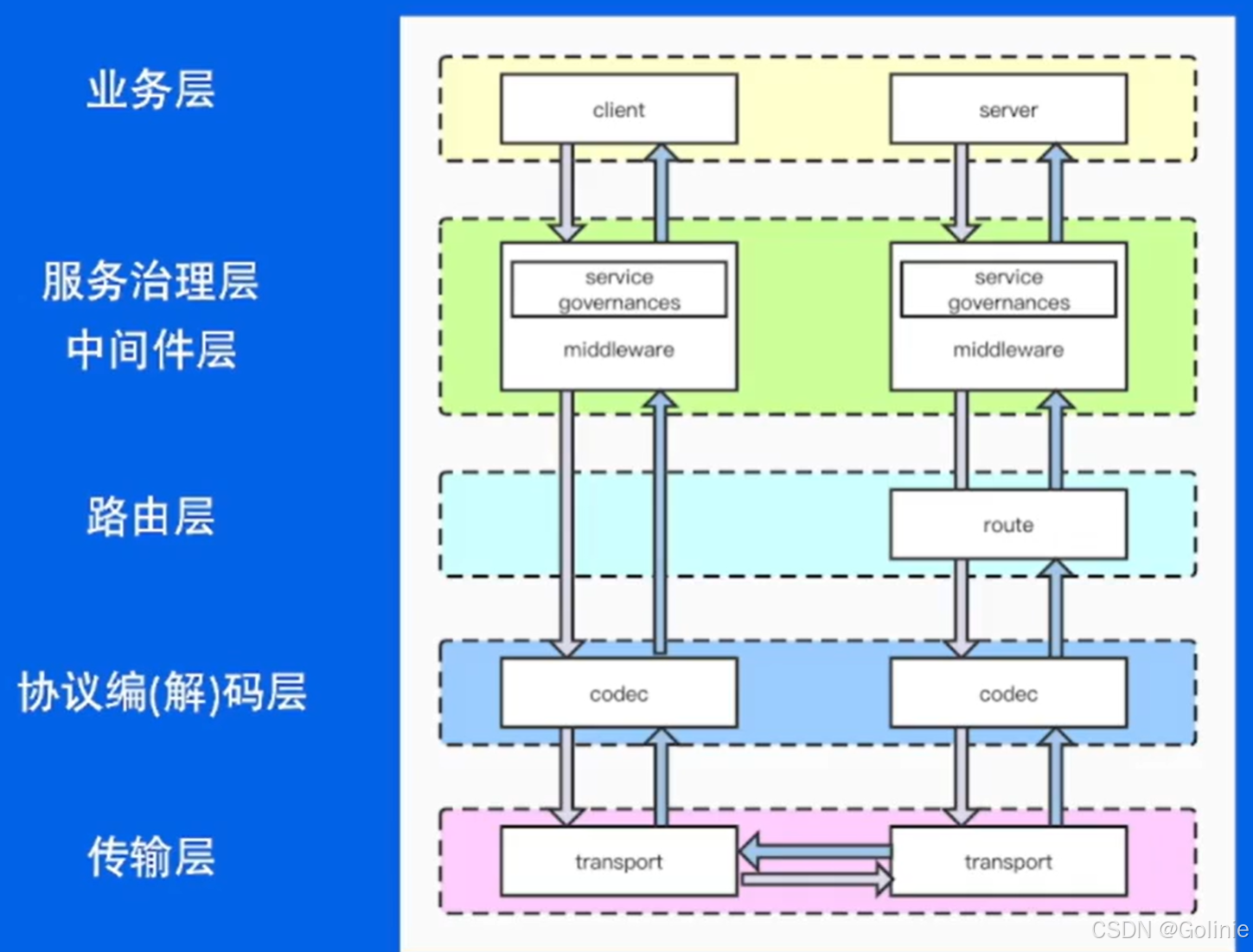
首先在业务层,业务方使用提供的框架去完成业务逻辑,(比如定义好返回什么东西之类的)。然后接着就会进入服务治理逻辑与中间件层,这一层就是熔断、限流,这一层对于请求可以有先处理或者后处理的逻辑,和请求的优先级。
在服务端server会多一个路由层,也就是根据url去决定一个对应的处理。
四、分层设计
分层设计的时候需要注意三个特性:专注性、拓展性、复用性。
下面是OSI七层模型、TCP\IP四层模型。
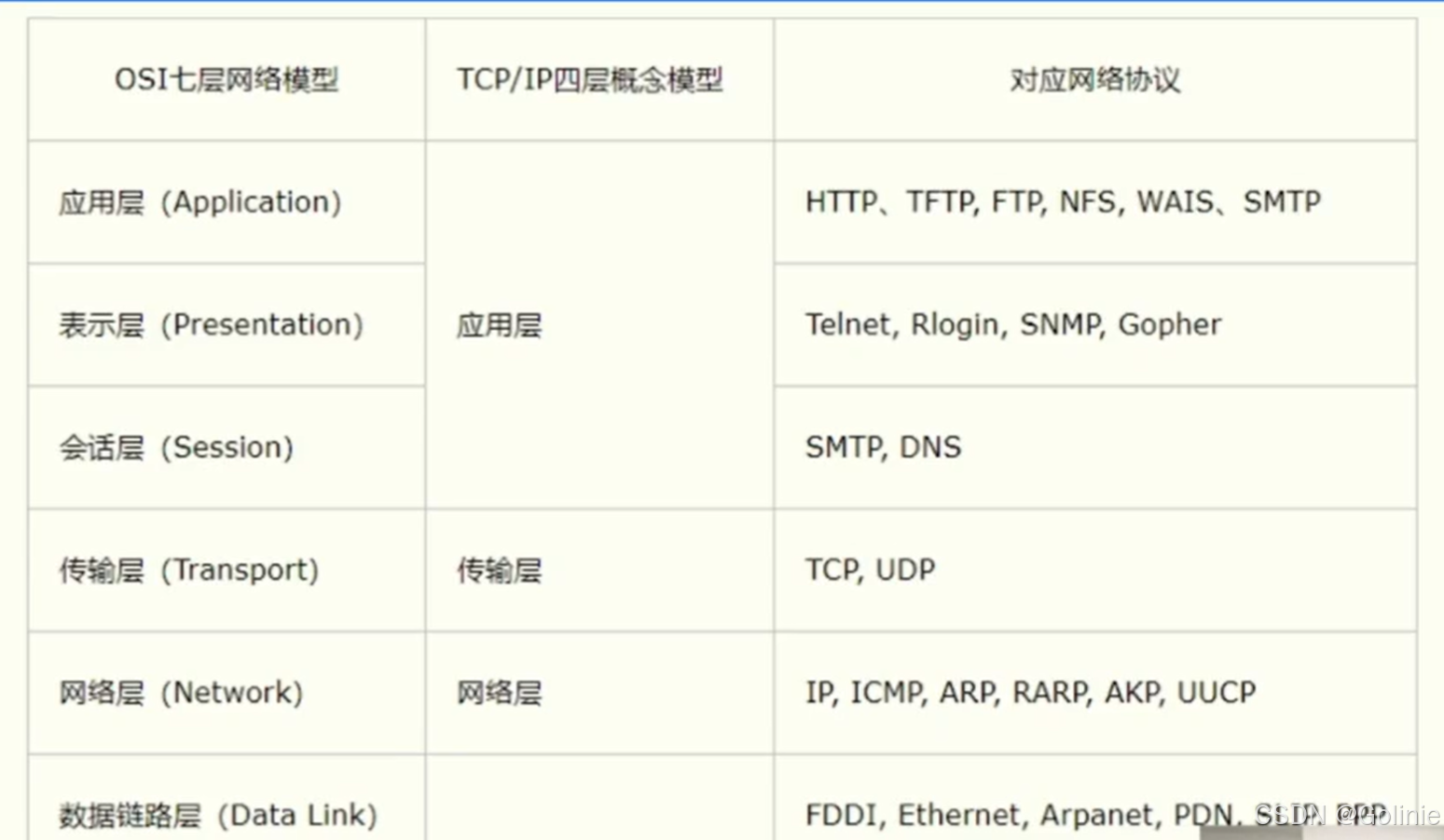

对应到框架设计的时候就转化为几个对应的点:高内聚、低耦合、易复用、高拓展性等。
从上到下依次是应用层、中间件层、路由层、协议层、网络层,在最右边时Common,放每一层公共使用的逻辑。
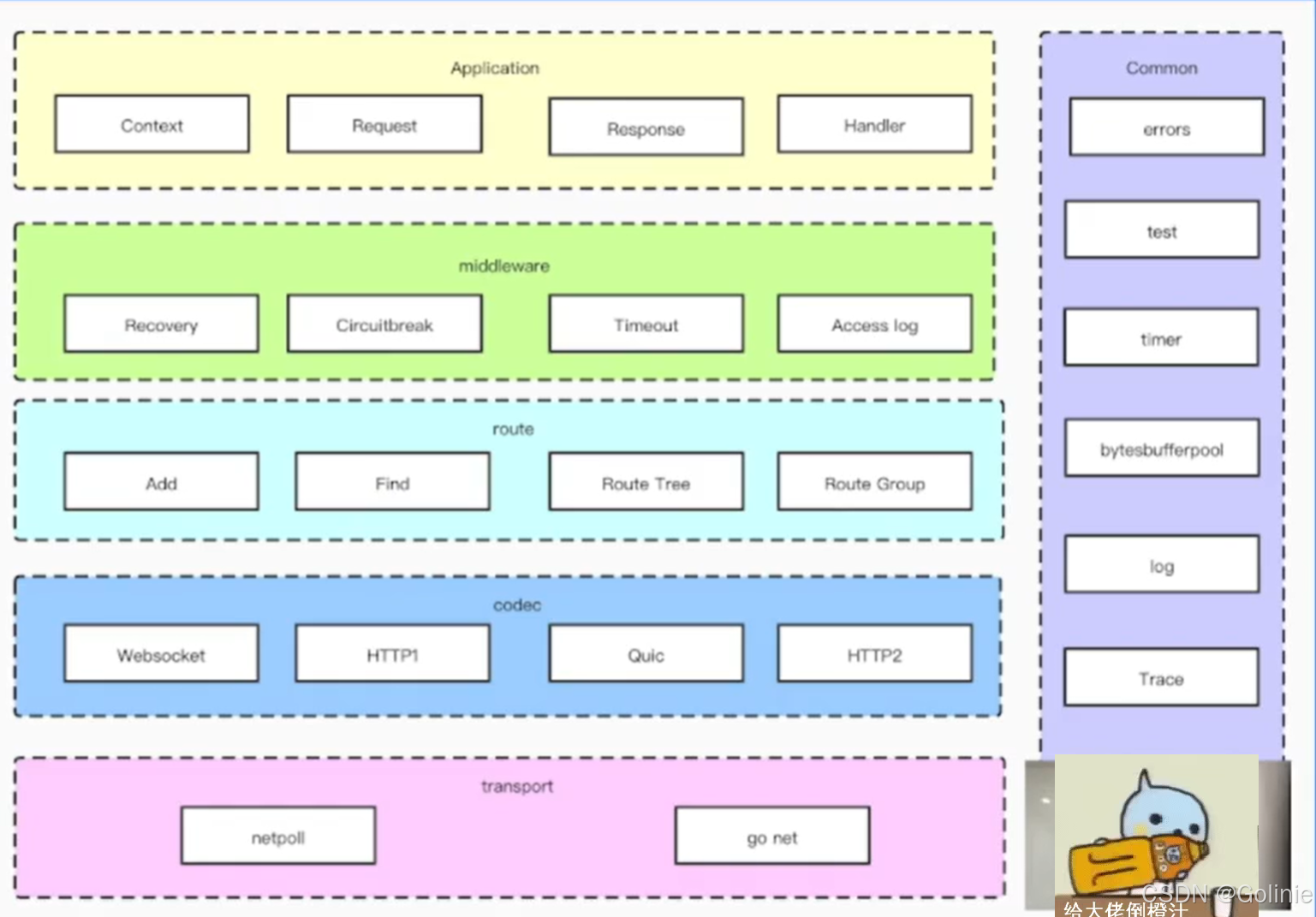
4.1 Application应用层设计
应用层是直接和用户打交道的,需要提供合理的API,这也就需要满足“可理解性”,比如ctx.Body()、ctx.GetBody(),不要用ctx.BodyA()这样的命名方式进行提供API,要让大家一眼知道这个接口是干什么的。
第二个是简单性,比如ctx.Request.Header,Peek(key) -> ctx.GetHeader(key)。
第三个是冗余性,就是做同样的事情的话,不要有两个接口,或者说一个功能需要两个接口拼起来完成。
后面还有兼容性、可测性、可见性(主要是安全方面、还有接口的使用难度,比如某种说法“不要试图在文档中进行说明,很多用户不看文档”)等。
4.2 middleware中间件层设计
中间件层的需求如下:
1、配合Handler实现一个完整的请求处理生命周期(在Web开发中,请求处理器Request Handler是处理HTTP请求的函数或模块。它接收请求、处理逻辑,并返回响应)。
2、用于预处理逻辑和后处理逻辑。
3、可以注册多中间件。
4、对上层模块用户逻辑模块易用。
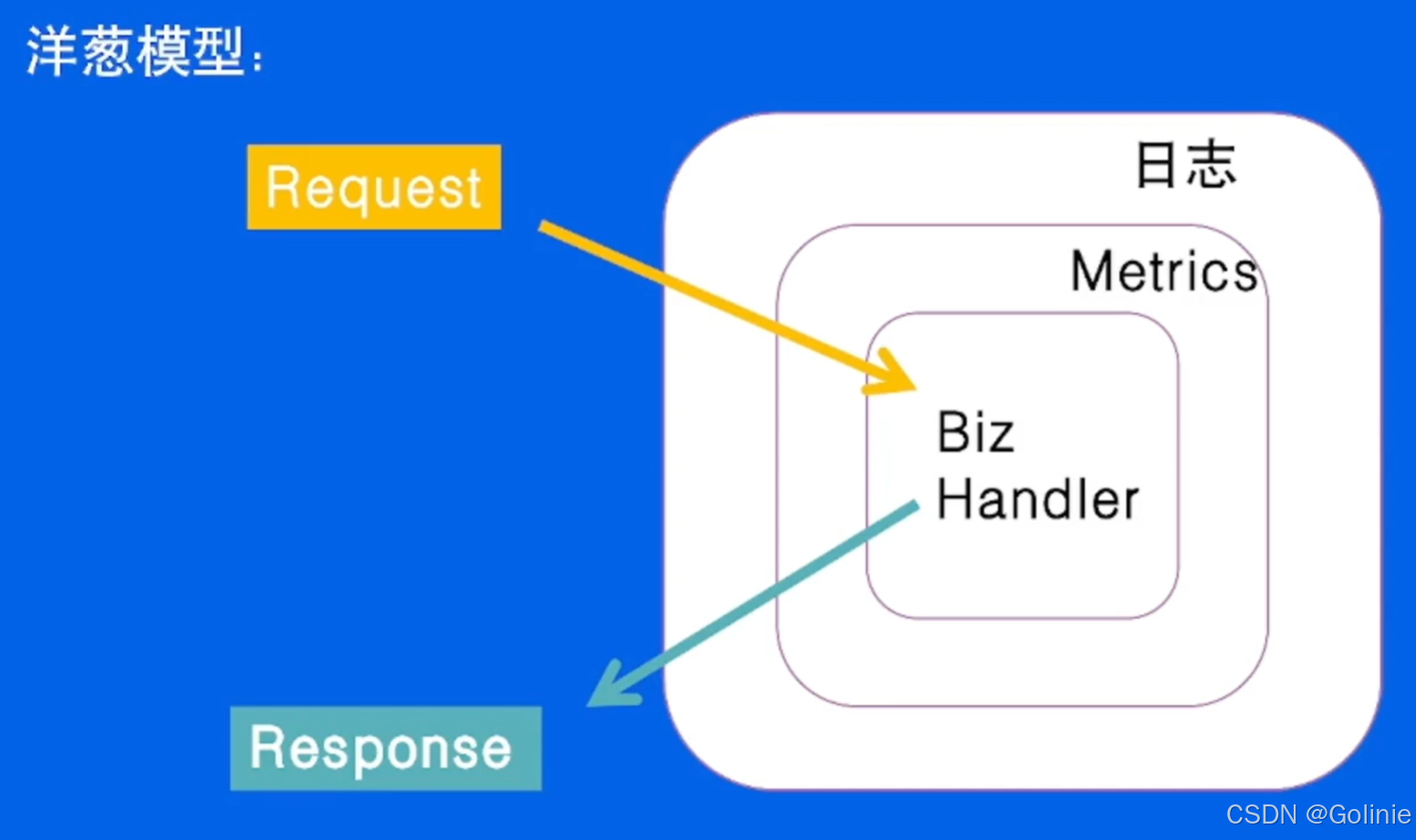
中间件设计:
这里我们可以看看洋葱模型。当一个Request请求进来之后,首先经过日志中间件预处理,然后经过Metrics中间件预处理,最后再去执行业务逻辑,然后经过Metrics的后处理,还有日志的后处理,然后把一个真正的response响应返回给用户。
这个使用场景是:日志记录、性能统计、安全控制、事务处理、异常处理等。
接下来我们看看一个代码案例的说明:
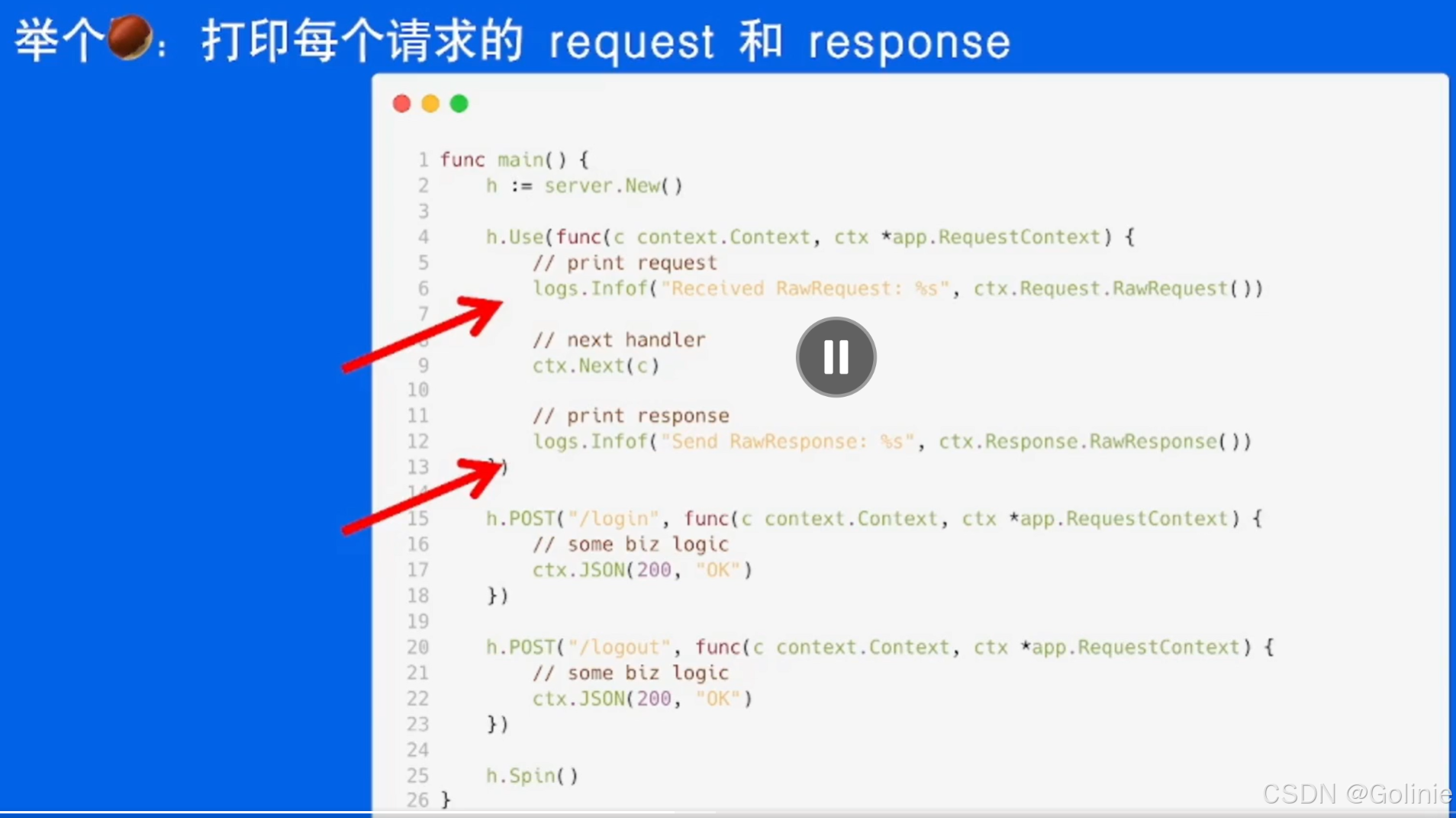
既然我们需要实现预处理还有后处理,这个就很像调用一个函数。
func Middleware(some param){
// some logic for pre-handle
//比如日志记录、身份验证、性能监控等
...
//将请求传递给下一个中间件或者最终的业务
next Middleware() /bizlogic()
//等同于
Next()
// some logic after-handle
//包括日志记录、清理资源、错误捕捉等
...
}
路由上可以注册多Middleware,同时也可以满足请求级别有效,只需要将Middleware设计为和业务、和Handler相同即可,也就是统一调用下一个函数。
package main
import (
"log"
"net/http"
"time"
)
// Middleware 是一个中间件函数,接收一个 http.Handler 并返回一个新的 http.Handler
func Middleware(next http.Handler) http.Handler {
return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {
// 预处理逻辑
start := time.Now()
log.Printf("Request received: %s %s", r.Method, r.URL.Path)
// 调用下一个中间件或业务逻辑
next.ServeHTTP(w, r)
// 后处理逻辑
duration := time.Since(start)
log.Printf("Request completed in %v", duration)
})
}
// BizLogic 是一个简单的业务逻辑处理函数
func BizLogic(w http.ResponseWriter, r *http.Request) {
w.Write([]byte("Hello, Middleware!"))
}
func main() {
// 创建一个业务逻辑处理器
bizLogic := http.HandlerFunc(BizLogic)
// 将中间件包装到业务逻辑处理器上
handler := Middleware(bizLogic)
// 启动HTTP服务器
http.ListenAndServe(":8080", handler)
}
但是需要考虑一个问题,如果用户不主动调用下一个处理函数怎么办。比方说用户只调用了中间件,那就只能我们帮助用户去实现这样一个逻辑。核心就是保证index在任何场景递增。
中间件框架的核心逻辑,用于确保中间件链中的每个处理器(handler)都能被正确调用。
//RequestContext 是一个上下文对象,用于管理中间件链的执行。
func (ctx *RequestContext) Next() {
ctx.index++
for ctx.index< int8(len(ctx.handlers)){
ctx.handlers[ctx.index]()
ctx.index++
}
}
当中间件出现异常,可以通过这样进行处理
func (ctx *RequestContext) Abort(){
ctx.index = IndexMax
//让index为最大值跳出最大值。
}
可以看看下面的调用链,但是存在一个问题,就是不在一个调用栈上。
比如某中间件,只能捕获自己协程的panic或者自己调用栈上的panic,不能捕获别人协程的。
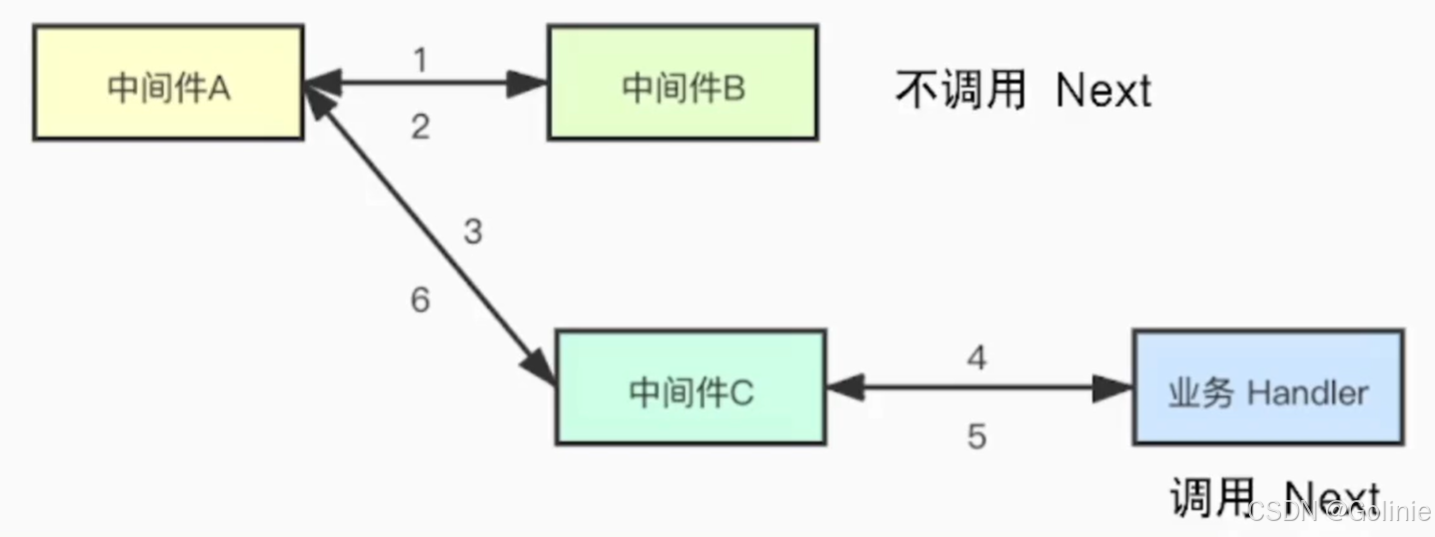
为了解决这个问题,一般有以下几种方法进行对应的解决:
1、在协程内捕获panic,比如用defer和recover。
2、避免在中间件启动新的协程。
3、使用上下文context传递错误,
4.3 Route路由设计
框架路由实际上是位URL匹配对应的处理函数(Handlers):
1、静态路由:/ab/c
2、参数路由:/a/:id/c、/*all
3、路由修复:/a/b <-> /a/b/ (也就是最后一个/要不要敲)
4 、冲突路由以及优先级:/a/b 、 /:id/c
5、匹配HTTP方法
6、多处理函数:方便添加中间件
最开始设计路由,可能会联想到map,比如说:map[string]handlers,但是这种只对静态路由有效,优势就是比较快、比较简单。
进阶的话可以用前缀匹配树,一层一层匹配。
对于参数路由,也可以构建路由树,同时需要结合fullpath来标记自己到底是进入的哪个路由。
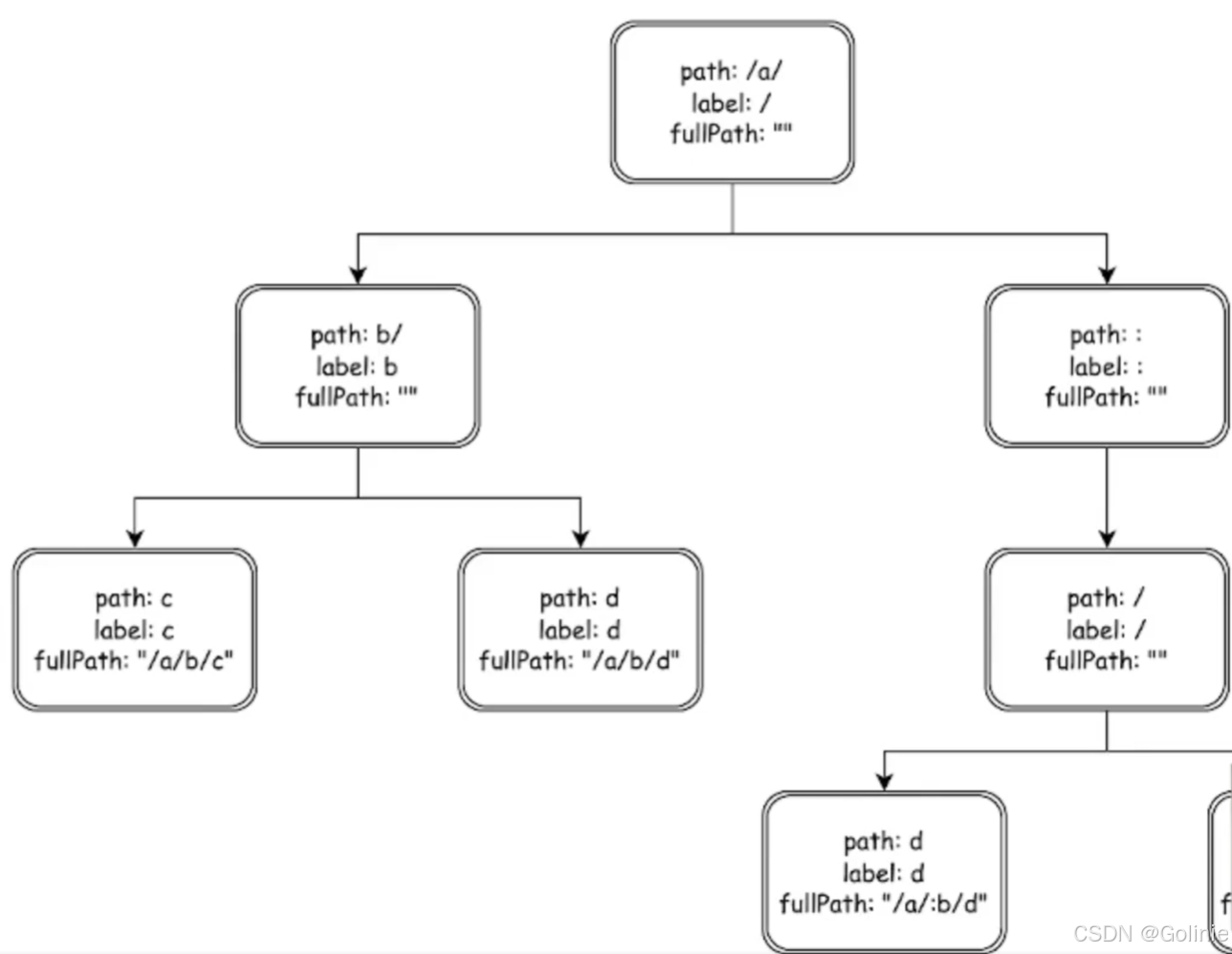 所以总的来说,应该如何匹配HTTP方法?我们构建很多个路由树,比如下面的路由映射表。
所以总的来说,应该如何匹配HTTP方法?我们构建很多个路由树,比如下面的路由映射表。

外层是map,根据method进行初步筛选,然后再进行前缀树的匹配。
那么进一步如何实现多处理函数?也就是在某个节点上使用一个list存储handler。
node struct {
prefix string
parent *node
children children
handlers app.HandlersChain
...
}
4.5 codec协议层设计
首先抽象出合适的接口,这里需要遵循一个Go语言社区的设计原则:
不要将Context存储在结构体中;相反,应该将Context显式地传递给每一个需要它的函数,并且Context应该是函数的第一个参数。(许多标准库函数,比如http.Handler也遵循了这种约定,将Context作为第一个参数。)
type Server interface {
serve(c context.Context,conn network.Conn) error
//第一个是context
//第二个是conn,因为可能需要在连接上读写数据
//返回error,就是感知到error之后抛给上层进行解决
}
一旦Context被存储在结构体中,它就很难被动态更新或替换。例如,你可能需要在运行时更改超时时间或取消信号,但存储在结构体中的Context很难做到这一点。同时多个协程可能会共享同一个结构体实例,从而导致对Context的竞争条件或状态不一致。最后就是如果Context被隐藏在结构体中,外部代码很难对其进行控制或模拟,这会给单元测试带来困难。
显式传递Context有以下好处:
明确性:通过将Context作为函数参数传递,可以清晰地表明哪些函数需要Context,以及Context的用途。这使得代码的可读性和可维护性更高。
灵活性:显式传递Context允许在调用函数时动态地提供不同的Context实例,例如在某些情况下使用超时Context,而在其他情况下使用无超时的Context。
易于测试:在单元测试中,可以轻松地传递一个模拟的Context,从而更好地控制测试环境。
4.6 transport网络层设计
首先我们要明确两种IO方式,分别是BIO,即Block IO阻塞IO和NIO,非阻塞IO。
BIO的示例代码如下:
go func(){
for{
conn,_ := listener.Accpet()
go func(){
conn.Read(request)
handle...
conn.Write(response)
}()
}
}()
NIO示例代码如下:
go func(){
for {
readbleconns,_:=Monitor(conns)
//监听器,当监听到有足够的数据之后,才去唤醒func
for conn := range readbleConns{
go func() {
conn.Read(request)
handle...
conn,Write(response)
}()
}
}
}()
golang中的标准库是go net,也就是“BIO”,有两个关键的接口,这两个都是用户态去传入buffer进行操作。
type Conn interface{
Read(b []type)(n int,err error)
Write(b[] type)(n int,err error)
...
}
字节自研了网络库netpoll,是NIO的,https://github.com/cloudwego/netpoll
type Reader interface{
//peek传入的n是表示期望底层能够给我们传输这么多的数据
//当底层有这么多数据的时候,才会唤醒func
Peek(n int)([]byte,error)
...
}
type Writer interface{
// Malloc 分配一个大小为 n 的缓冲区,然后把数据提交到底层空间里面,后面再调用flush把数据发送出去,因此需要对buffer进行管理。
// 如果分配成功,返回一个缓冲区和 nil 错误。
Malloc(n int)(buf []byte,err error)
// Flush 将缓冲区中的数据刷新到目标存储中。
Flush() error
...
}
由于采用NIO的方式,并不知道数据什么时候被发出去。
因此需要将数据写入底层(或者说保证数据不变),所以需要网络库对buffer进行管理。
type Conn interface{
net.Conn
Reader
Writer
}

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









