




准备数据
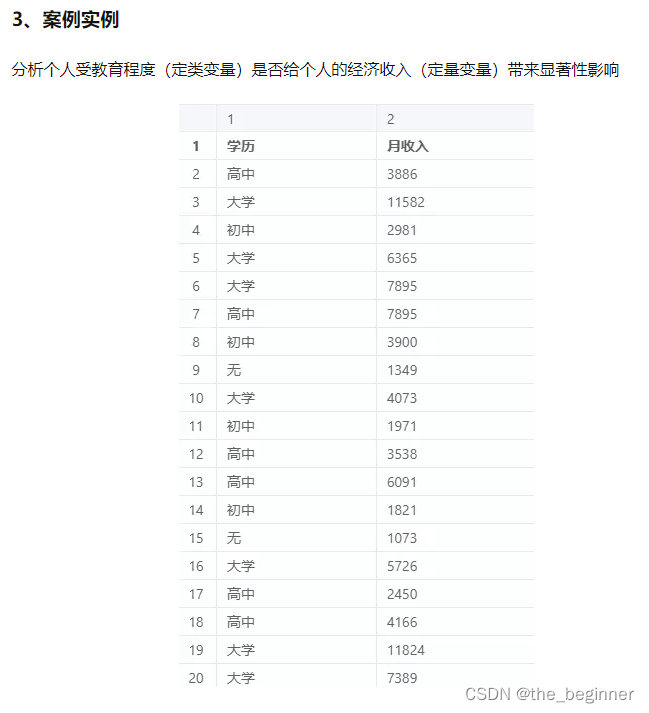
将数据格式调整为以下格式:
jupyter处理过程
#读取数据
import numpy as np
import pandas as pd
# 创建一个空的DataFrame
t1 = pd.DataFrame()
t2 = pd.DataFrame()
t3 = pd.DataFrame()
T1=pd.read_excel('./数据/抑郁_T1.xlsx')
T1.columns=T1.iloc[0]
T1=T1.drop(T1.index[0])
T1.head(2)
t1['姓名']=T1['姓名:']
t1['抑郁总分']=T1['抑郁总分']
t1.columns=['姓名', 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 907
907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









