



前言
本小节介绍的是OpenACC,原书中写到的介绍是:OpenACC is a complementary programming model to CUDA that uses a compiler directives-based API designed for high performance, programmability, and portability across many platforms. 通篇读下来后,博主认为该工具主要的作用在于使用简单的语法实现CUDA底层调用gpu硬件的加速,可以理解为对CUDA编程的封装(?
想要具体学习OpenACC可以去官网查看他的文档及API说明:https://www.openacc.org/resources,博主仅针对原书的介绍进行简单的总结
所有涉及到的代码可从博主的代码仓库中查看:https://github.com/palLiHua/cuda
第八章 CUDA相关库及OpenACC
8.4 OpenACC介绍
概述
OpenACC的线程模型包括gang,worker,vector,类比于CUDA编程中的blocks,warp,thread.与CUDA最大的区别是OpenACC显示暴露了warp,而在CUDA编程中代码逻辑层面是看不到warp的。博主这里说明得可能不够清晰,但学过前面前三章的童鞋应该能明白我在说什么,原书中的介绍是:OpenACC exposes the concept of workers (that is, warps) directly in the programming model, whereas in CUDA you do not explicitly create warps of threads.
OpenACC执行的模式主要有三种,假设有G个gangs,W个workers,每个vector有V个elements,三种模式及其运行情况如下:
1. gang-redundant mode
这种模式下每一个gang中只有一个worker工作,每一个worker又只有一个element工作,即共有G个线程在同时运行。类比于CUDA编程的话,就是创建了G个block,但每个block只有一个thread工作,等价于如下代码:
__global__ void kernel(...) {
if (threadIdx.x == 0)
{
foo();
}
}2. gang-partitioned mode
这种模式下线程工作模式同gang-redundant相同,即同时有G个线程并行运行,那就有疑问了,和gang-redundant有什么区别呢?原文解释是:In gang-partitioned mode, there is still only one active vector element and one active worker in each gang, but each active vector element is executing a different piece of the parallel region.
给出的代码示例是:
__global__ void kernel(int *in1, int *in2, int *out, int N)
{
if (threadIdx.x == 0)
{
int i;
for (i = blockIdx.x; i < N; i += gridDim.x)
{
out[i] = in1[i] + in2[i];
}
}
}
查了一下资料以及问询GPT,个人认为和gang-redundant的区别体现在gang-redundant是所有线程做着同样的工作及处理同样的数据,换句话说就是在重复性工作,没有任何意义(可能?),而gang-partitioned则是每个gang在处理着不同的数据。
3. worker-single mode
在该模式下又可以分为worker-partitioned mode和vector-partitioned mode。有了上面的了解,不难理解worker-partitioned mode就是每个gang下所有worker都开始并行运行了,因此总共会有G*W个线程同时工作,等价于:
__global__ void kernel(int *in1, int *in2, int *out, int N)
{
if (threadIdx.x % warpSize == 0)
{
int warpId = threadIdx.x / warpSize;
int warpsPerBlock = blockDim.x / warpSize;
int i;
for (i = blockIdx.x * warpsPerBlock + warpId; i < N;
i += gridDim.x * warpsPerBlock)
{
out[i] = in1[i] + in2[i];
}
}
}
那么在vector-partitioned mode下就会有G*W*V个线程同时执行。
使用OpenACC计算指令
主要可以使用#pragma acc kernels和#pragma acc parallel两种方式以启用gpu加速。
#pragma acc kernels
使用该指令通常会使coder更轻松,包括数据传输、并行程度均有编译器自行决定,但代价自然就是性能的下降。具体的使用方法可以参考acc.c,相较于CUDA需要自己手写核函数,OpenACC仅需要一行代码就可以实现gpu加速,非常便捷。使用的编译器是PGI,博主下载的是英伟达提供的HPC,可从https://developer.nvidia.com/hpc-sdk处下载,使用指令pgcc -acc -Minfo=accel acc.c -o test进行编译,其中-Minfo=accel可以用于查看编译的一些细节,顺利的话你会得到类似于如下的输出:
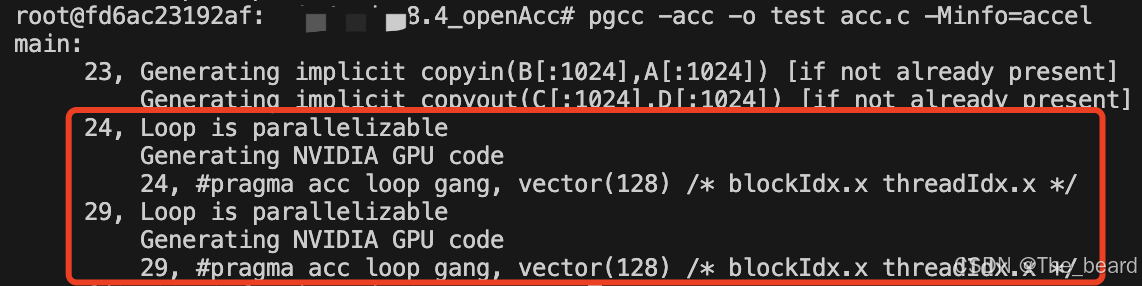
从红框圈出部分不难看出,两处循环使用了gpu进行加速,前两行代码也不难猜出,要在gpu上运行的话,它自动帮我们完成了数据host to device以及device to host传输的工作。
使用这种方式还可以加上if条件语句以及async(id)用于异步运行,具体用法参考官方文档及例子。需要值得注意的一点是,if条件不满足情况下,使用pgcc -acc -Minfo=accel编译仍会有上图中的输出,但具体有没有使用gpu加速其实是在运行过程中才决定的。
#pragma acc parallel
使用parallel的好处是你可以决定程序运行的并发程度,例如使用num_gangs(int)指定gang的数量,同样也可以加入if、async、wait等指令,与kernels最大的区别就是你能控制的部分更多了。在执行循环时需要加上#pragma acc loop,默认情况下是gang-redundant mode,如果要增加并发度,那么就要再加上gang用以表明使用gang-partitioned mode,代码如下:
#pragma acc parallel {
int b = a + c;
#pragma acc loop gang
for (i = 0; i < N; i++)
{
...
}
}那么同理加上worker/vector就能切换至worker-partitioned mode或vector-partitioned mode
使用OpenACC数据指令
上面介绍的过程中,我们都默认数据传输是自动进行的,该小节介绍的就是我们如何手工控制数据的传输。有两种方式,第一种是使用data copyin/ data copyout,具体如何使用可参考data.c,这里仅贴出核心代码
#pragma acc data copyin(A[0:N], B[0:N]) copyout(C[0:N], D[0:N])
{
#pragma acc parallel
{
#pragma acc loop
for (i = 0; i < N; i++)
{
C[i] = A[i] + B[i];
}
#pragma acc loop
for (i = 0; i < N; i++)
{
D[i] = C[i] * A[i];
}
}
}
这里要提到的一点是,为写代码方便,上述代码等价于:
#pragma acc parallel copyin(A[0:N], B[0:N]) copyout(C[0:N], D[0:N])
{
#pragma acc loop
for (i = 0; i < N; i++)
{
C[i] = A[i] + B[i];
}
#pragma acc loop
for (i = 0; i < N; i++)
{
D[i] = C[i] * A[i];
}
}这种方式存在的一个问题是,数据传输会block程序的进行,即不能异步进行,那么这时候就需要第二种方式闪亮登场。
在第二种方式下,仅需要把指令改为#pragma acc enter data和#pragma acc exit data,如果需要异步进行,则仅需要加上async(int),可以参考原书中的这段代码:
#pragma acc enter data copyin(B[0:N]) async(0)
do_some_heavy_work(C);
#pragma acc kernels async(1) wait(0)
{
for (i = 0; i < N; i++)
{
A[i] = do_work(B[i]);
}
}
#pragma acc exit data copyout(A[0:N]) async(2) wait(1)
#pragma wait(2)OpenACC Runtime API
除了上述介绍的compiler directives,OpenACC还提供了一系列函数指令,包含在openacc.h头文件中,这里不作解释,可自行查看文档
OpenACC和CUDA一同使用
CUDA编程的优势在于能自主控制的部分更多,而OpenACC自然在于其编程的便利性,这里就以一个例子来介绍下如何同时使用这两个工具,代码可参考cuda_openacc.cu,这个例子中使用curand产生随机的两个矩阵,然后使用3个for循环进行矩阵相乘操作(使用OpenACC),最后将生成的矩阵进行每个元素加和的操作(使用cublas库的cublasSasum先进行每行求和,最后再将vector加和)
在编译的时候,原书给出的指令是pgcpp -acc cuda-openacc.cu -o cuda-openacc -Minfo=accel -L${CUDA_HOME}/lib64 -lcurand -lcublas –lcudart,但博主在执行过程中发现根本没有pgcpp,查看了一下英伟达提供的指令:

那就尝试一下pgc++吧,执行后的结果报错:

显示找不到curand头文件,之前使用nvcc时都可以链接,怎么到这就不行了?只能google一下,有个2015的回答是这样:

ok,那就加上-Mcuda试试:

感觉可行的样子,换成-cuda结果如下:

终于成功,看下输出,有个比较有意思的点:
43, #pragma acc loop seq
Generating implicit reduction(+:sum)
如果看过代码的童鞋会发现我在第43行的for循环中并没有加上编译指令,编译器自动帮我选择了合适的编译指令,reduction什么作用可以查看文档或者原书371页
小结
这一小节也只是简单介绍了下OpenACC,总体来说整个第八章都是概述性的介绍,所以博主也只是挑了些重点写,实际需要哪个库还是需要查看文档。下一章进入多gpu编程,希望自己还能坚持下去,也请各位点个赞叭


















 3733
3733

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









