 DeepSpeed深度解析与应用指南
DeepSpeed深度解析与应用指南





DeepSpeed1是由微软研究团队开发的一个深度学习优化库,旨在提供高效、可扩展的大规模模型训练能力。它通过采用先进的并行化策略、内存优化技术(如 ZeRO 内存优化器)和混合精度训练来显著提高训练效率和减少资源需求。
1. ZeRO
ZeRO(Zero Redundancy Optimizer)是DeepSpeed中的关键技术之一,它是为了解决大规模分布式训练中的内存瓶颈问题而设计的优化器。ZeRO通过优化模型状态的存储和通信来大幅减少所需的内存占用,使得可以在有限的资源下训练更大的模型。DeepSpeed是一个由微软开发的开源深度学习优化库,它旨在提高大规模模型训练的效率和可扩展性,而ZeRO是其核心组件之一,用于优化内存使用,允许训练更大的模型。
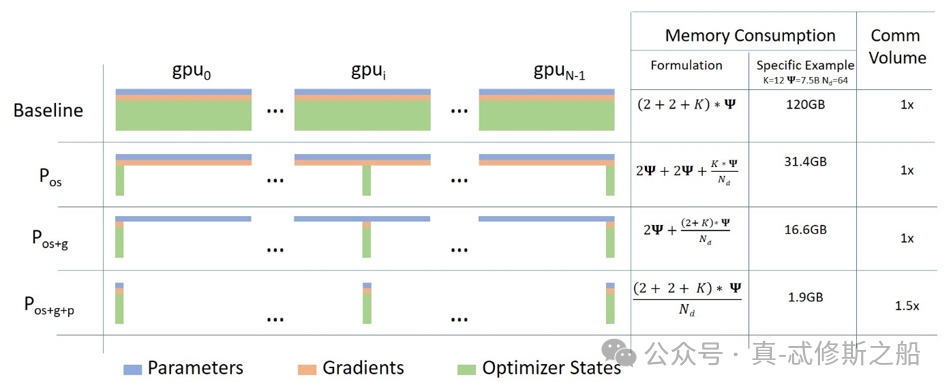
ZeRO分为三个优化级别:ZeRO-1、ZeRO-2和ZeRO-3,每个级别都在前一个级别的基础上进一步减少内存占用。
-
1. **ZeRO-1** :在这个阶段,优化器状态(例如Adam优化器的权重和梯度)被分布到多个GPU上,而不是每个GPU都存储完整的状态。这样可以节省一部分显存,但模型参数和激活仍然需要在每个GPU上完整存储。 -
2. **ZeRO-2** :在ZeRO-1的基础上,进一步对梯度进行分片处理,除了优化器状态外,梯度也被分布到多个GPU上。这进一步减少了每个GPU上的内存使用,从而提高了计算效率。 -
3. **ZeRO-3** :在这个阶段,实现了对所有模型状态的完全分片,包括模型参数。这意味着,模型的参数、优化器状态和梯度都将被分布到多个GPU上。这允许在相同的显存条件下训练更大的模型,但可能会增加通信开销。
此外,还有ZeRO-Infinity,它是ZeRO-3的扩展,可以利用CPU和NVMe内存来进一步扩展GPU的内存,支持训练更大型的模型。
FSDP 可以理解为是ZeRO-3的实现,它通过将模型的梯度、优化器状态和参数进行分片操作,使得每个 GPU 只存储部分参数信息,从而优化了资源的利用和提高了训练效率。
2. DeepSpeed: 并行化策略
DeepSpeed 支持多种并行化策略,包括数据并行、模型并行(包括流水线并行和张量并行),这些方法可以灵活组合,以适应不同规模和复杂度的深度学习模型。
数据并行 (Data Parallelism)是将模型的副本分布到多个GPU上,每个GPU处理不同的数据子集,然后在每个训练步骤结束时同步模型参数。这种方法适用于模型较大,无法完全放入单个GPU内存的情况。数据并行主要采用上述ZeRO策略。
流水线并行 (Pipeline Parallelism)是将模型的层划分为多个阶段,这些阶段可以在不同的处理器上并行处理。这种方法可以提高内存和计算效率,特别适合于深度学习训练。
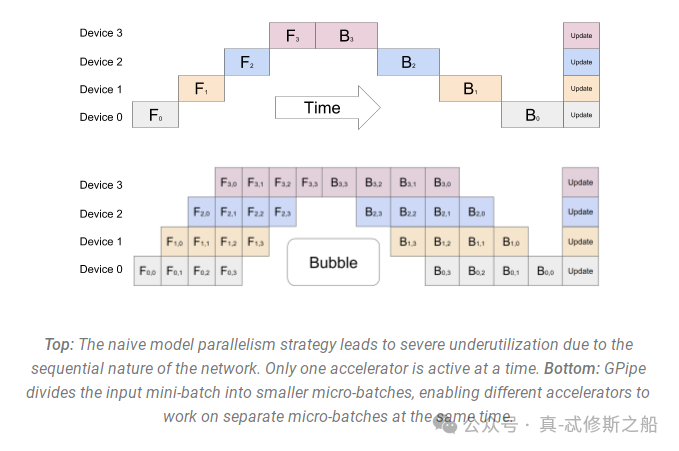
通过将每个批次的训练数据分成更小的微批次(micro-batches),这些微批次可以并行地在流水线的各个阶段中处理。一旦一个阶段完成了一个微批次的前向传递,激活内存就会传递给流水线中的下一个阶段。类似地,当下一个阶段完成了对一个微批次的后向传递,相对于激活的梯度就会通过流水线向后传递。每个后向传递都会局部累积梯度,然后所有数据并行组并行地执行梯度的归约。最后,优化器更新模型权重。
**张量并行(Tensor Parallelism)**则是将模型的参数张量分割到多个GPU
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









