




在上篇文章【AI大模型应用开发】3. RAG初探 - 动手实现一个最简单的RAG应用 中,我们动手实现了一个RAG基本流程。里面涉及到向量数据库和向量检索。对于没接触过的人可能比较懵。本文介绍下文本向量化的概念,以及向量检索的原理,只是简单介绍,不会深入,所以不用担心看不懂 ,想要详细研究的,可以去搜相关论文,涉及到机器学习和模型训练等。
0. 文本向量
0.1 什么是文本向量
文本向量(Text Vector)是一种将文本数据转换为数值向量的技术,以便于机器学习和数据分析。通过将文本数据转换为数值向量,我们可以使用机器学习算法对文本数据进行处理和分析。
0.2 文本向量是怎么得到的
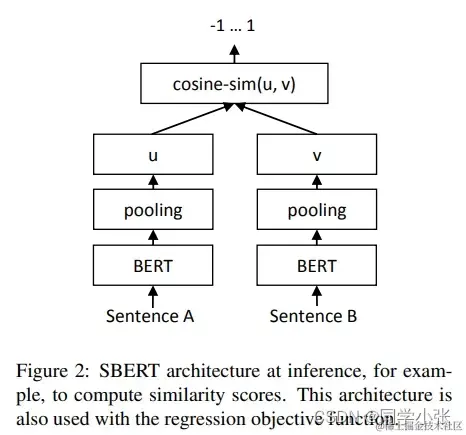
(1)构建 相关(正立)与不相关(负例)的句子对儿样本
(2)训练 双塔式模型 ,让正例间的距离小,负例间的距离大
参考:arxiv.org/pdf/1908.10…
1. 获取文本向量
前面已经说了文本向量是怎么得到的,其实也是训练了一个模型。使用这个训练的模型,给一个输入,就可以得到该输入的向量。 这里我们可以使用OpenAI开放的文本向量化接口embeddings.create来获取某个文本的向量值。
python
复制代码
from openai import OpenAI
import os
# 加载环境变量
from dotenv import load_dotenv, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 804
804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









