



 本文介绍了在FastApi中如何进行数据迁移,详细讲解了使用Alembic进行迁移的步骤,包括安装、初始化、配置、生成迁移文件和变更数据库。同时,文章提到了常见的FAQ和注意事项。
本文介绍了在FastApi中如何进行数据迁移,详细讲解了使用Alembic进行迁移的步骤,包括安装、初始化、配置、生成迁移文件和变更数据库。同时,文章提到了常见的FAQ和注意事项。
今天我们来聊一聊在FastApi里面,数据迁移工作。
啥是数据迁移
在我们平时的开发过程中,经常需要对一些数据进行调整。一般会有以下几种场景:
1.需要新的数据表
我们的接口自动化平台虽然已经较为完善了,但难免会继续迭代一些新的功能,假设我们需要做一个订阅用例的功能。
大体想一下就可以知道,订阅用例以后这个数据得持久化(即入库),这样我在查询谁订阅了这条用例的时候,就能获取到订阅人,订阅时间等数据。
这也就意味着我们需要一张订阅表,里面至少得有订阅人和订阅的id,以及订阅时间这3个要素。体现在数据库通俗点说就需要:
// 创建订阅表, 后面的省略
create table...
由于业务的变动,导致新的数据表诞生。
2.需要对现有表结构进行调整
当我们的订阅表完成以后,有的同学就发现了,这个订阅好像不能取消,所以我们此时可能需要一个新的字段: isValid,这个字段用来判断用户是否取消订阅了这个用例,如果我订阅错了,或者嫌消息太多,想取消订阅,那还是得满足需求的。
包括新增字段/修改字段/删除字段,这些都会对数据表产生影响,导致我们需要改动数据库。
回到ORM
我们目前采用sqlalchemy作为我们的orm,如果只需要修改Python的Model类(操作字段就加在Model类里面操作)该多好。这样的话,我们依然不需要去写很基础的sql语句,就能达到修改表结构的目的。而这个,就是我们今天要讲的数据迁移。因为数据需要发生变化,orm与数据库的逻辑对不上号了,所以我们需要迁移。
迁移手段
目前市面上,关于Django(自带orm)和Flask这块都很成熟,django因为有自带的orm显得更牛逼,在manage.py里面自带了migrate(迁移)的命令。
而我们今天要讲的fastapi,由于不像django那么全面,所以我们采用alembic(sqlalchemy作者编写)来帮助我们完成数据迁移操作。
如果你也用的fastapi+sqlalchemy,那我们就一起来耍耍i!
注: sqlalchemy只自带create_all(建立全部表)的功能
安装alembic
大家采用虚拟环境和全局安装都可以,我的建议是全局安装,因为我们可能会在多个项目使用它。
pip install alembic
初始化项目
我们在python项目的根目录输入以下命令:
alembic init alembic
alembic是我们刚才安装的工具,init则是初始化的意思,后面的alembic则是迁移文件夹的名字,一般我们会默认叫alembic,以便于其他人一眼就知道是干嘛的。
修改alembic.ini
执行完成之后你会发现根目录多了个ini配置文件和alembic文件夹,我们需要稍微修改下配置文件:
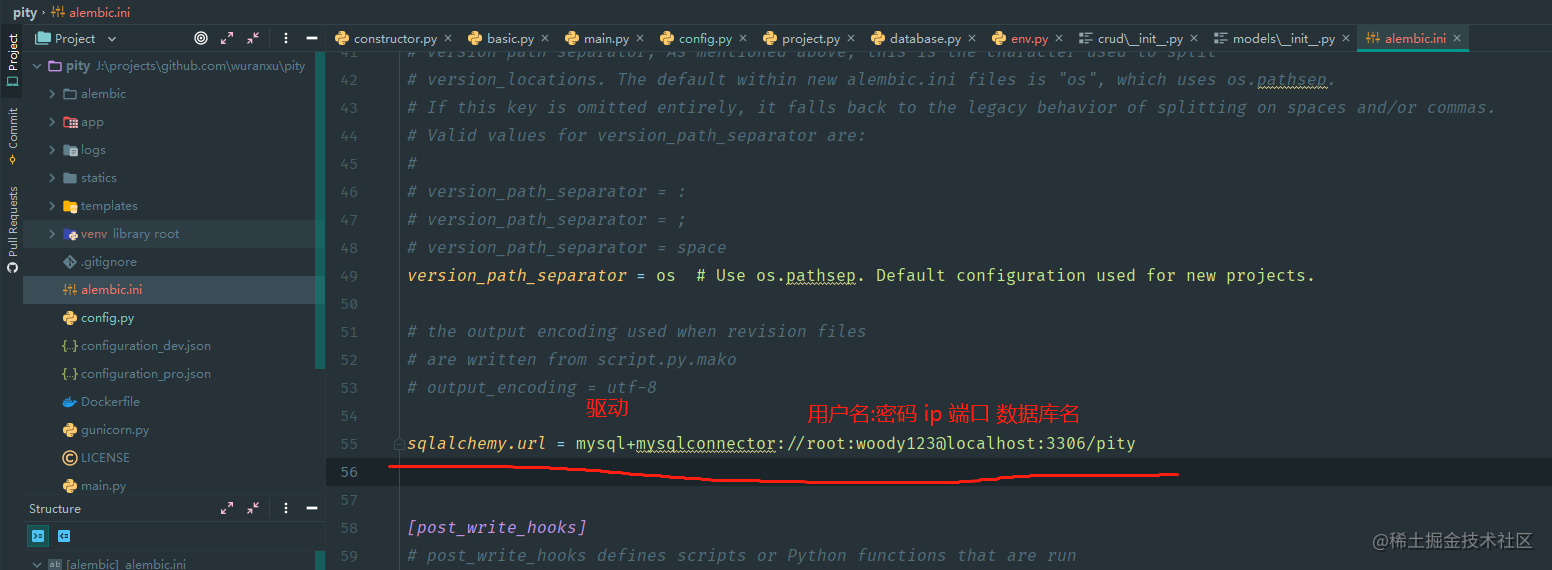
将alembic.ini中的sqlalchemy.url改为你数据库的jdbc连接地址,以我的为例:
修改alembic/env.py
首先我们找到里面的target_metadata变量,默认是None。接着在target_metadata = None上方加入如下代码:
import sys
from os.path import abspath, dirname
sys.path.append(dirname(dirname(abspath(__file__))))
然后我们需要引入我们的model目录,由于在pity里面,最后的初始化建表工作都是在curd目录进行的:
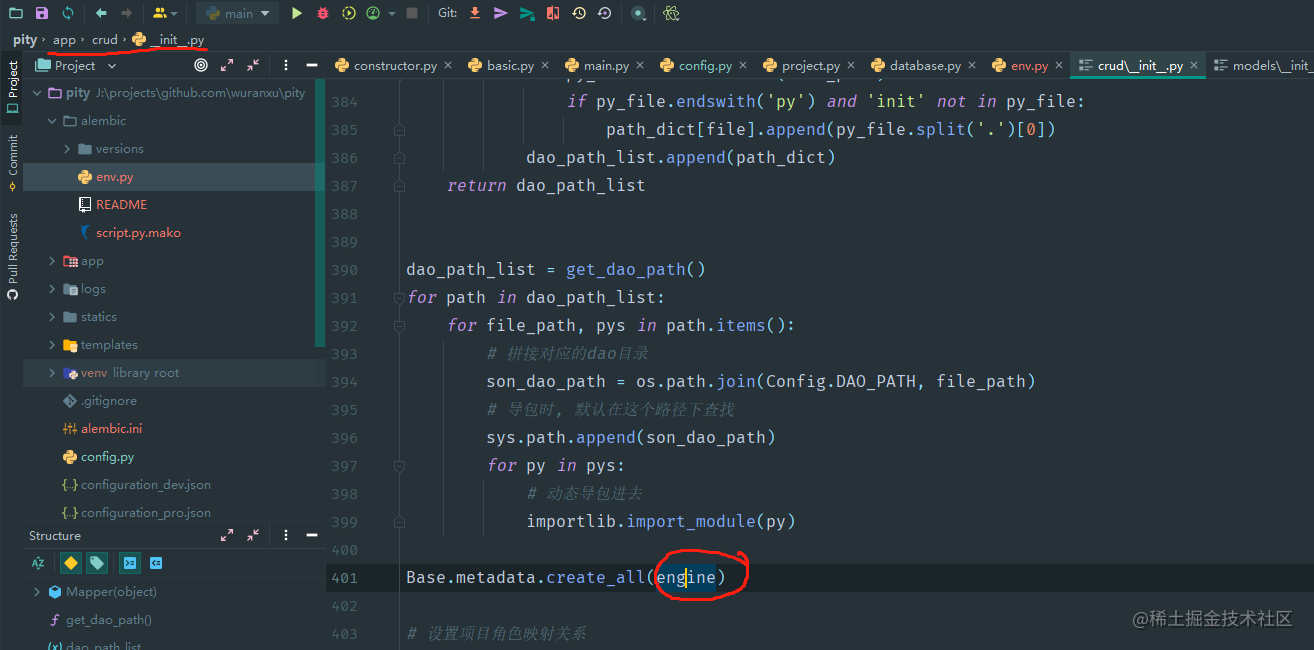
所以我这边是引入crud里面的Base。这个Base是啥玩意呢?
我们使用sqlalchemy,都需要引入各种model,这些model最终都会被加入到Base.metadata,这样sqlalchemy就知道你有哪些表需要处理了。
我们继续修改env.py,也就是告诉alembic你有哪些数据表(上文说的, 数据表都在Base.metadata)。
# 注意这个地方是要引入模型里面的Base,不是connect里面的
from app.crud import Base
# 告诉alembic 你的表数据在哪
target_metadata = Base.metadata
开始生成迁移工作
要注意,我们配置这么多东西是为了让alembic知道你的model都在哪,你的数据库怎么连,这样它才能去对比差异并生成结果。
alembic revision --autogenerate -m "test"
稍作等待,我们可以在alembic/versions目录看到对应的py文件:
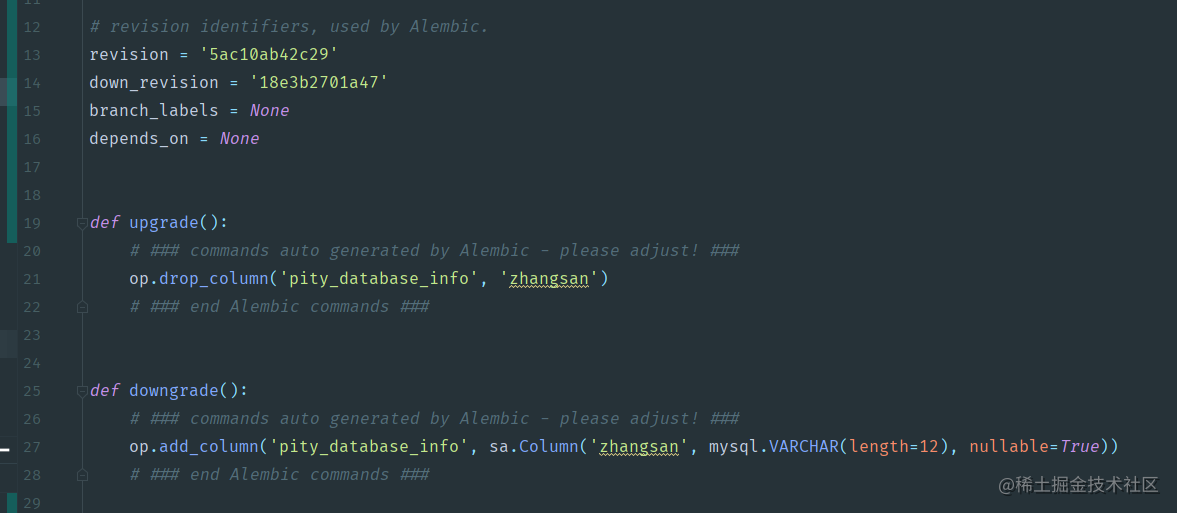
里面会有drop_column(删除字段)这样的操作信息。但要注意,这并没有真正修改数据库。
变更数据库
alembic upgrade head
执行上述命令,alembic就会根据你当前的版本(应该是你刚才生成的version的py脚本)去执行数据库变更操作。
这样,一个简单的迁移工作就完成了。接着我们聊聊注意事项。
FAQ
Q. 版本py脚本无变更信息出现
A. 请检查你的数据库是否真有变更,检查你的数据库url是否正确,检查你的model是否引入正确,如果操作都没问题,可以删除alembic目录和ini,重复上述操作(我昨晚就是这样的)
Q. 为什么字段重命名没有产生变更
A. 这玩意只校验了新增/修改/删除字段,这里的修改指的是字段的nullable这种修改,所以改字段名它不会检测。
Q. 我数据库里面有表没有定义到model,为啥变更给俺把表删除了?
A. 这个问题我也发现了,应该是有什么配置可以配置不删除未找到的表,但我目前还没有去研究,有后续会在底部留言。
最后,这个玩意相对比较鸡肋,建议不要大批量变更。可以频率高一点,比如有一点点改动就用它变更一下,而不要在史诗级改动的时候使用它。我个人的整体感受是,不太好用,但勉强能用。(因为暂时没有发现更合适的)

















 6485
6485

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









