



在数字艺术领域,AI绘画技术已经逐渐成为艺术创作的新趋势。Stable
Diffusion作为一款领先的AI绘画工具,凭借其强大的图像生成能力,备受关注。现在,我们为你带来2024年最新版的Stable Diffusion下载、安装和使用教程,让你轻松掌握这款强大的工具。

2024年最新版Stable Diffusion:功能升级,体验更佳 2024年最新版的Stable Diffusion在原有基础上进行了功能升级,提供了更加丰富的绘画选项和更高的图像生成质量。无论是创作抽象艺术、写实画作还是动漫角色,最新版的Stable Diffusion都能满足你的需求。
SD
Stable Diffusion一款2022年问世的AI生成式应用。它与Midjourney当属时下最热的两款AI绘画应用。
Stable Diffusion不同于Midjourney,它开源且免费,但操作门槛较高。其安装模式有本地和云端,这里我们着重介绍如何本地安装,以及安装时需要注意的部分!
现在,就让我们进入安装实操环节吧~
0****1
安装前置软件

这三个就是安装SD之前需要安装的前置软件,分别是Cuda、Git以及Python。其中,Python跟Git可以直接使用阿彼提供的安装包,至于Cuda,需要根据自身电脑的配置去适配下载安装。
下载Cuda
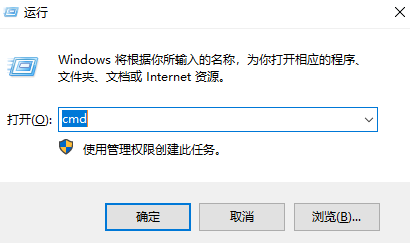
–Cuda有很多版本,不同的显卡对应不同的Cuda。按WIN+R,打开运行窗口,输入cmd,点击“确定”;

–在弹出窗口中输入“nvidia-
smi”后按下回车键“Enter”,显示的就是你电脑支持的Cuda版本(注:Cuda版本的下载链接:https://developer.nvidia.com/cuda-toolkit-archive);

–打开链接,选择对应的Cuda版本,然后根据设备选择对应选项,最后点击“Download”(注:安装过程一路默认)。
安装Python

–点击安装包中的python,在弹出的界面中先勾选“Add Python 3.10 to PATH”,再点击“Install Now,等待完成安装即可;”

–按WIN+R,打开运行窗口,输入cmd,点击“确定”,在弹出窗口中输入“Pyhton-V”后按下回车键“Enter”,看到显示的Python版本与安装版本一致即安装成功。
安装Git

–点击安装包中的Git,一路维持默认安装即可。
这样,前置软件的安装就顺利完成了。接下来,进入SD的安装环节吧!在这里,先感谢B站UP主秋葉aaaki提供的安装包。他的安装包提供了启动器,可以帮助我们方便地管理各种模型和插件。
02
本地部署SD
下载并解压压缩包

–右键单击压缩包,安装前有两点要注意:
1.安装包解压的文件夹最好放在一个内存容量大的系统盘中(建议可用容量大于300G或以上);
2.安装路径不要有出现,例如E:/Program/AI绘画,避免路径索引过程中出现错误;
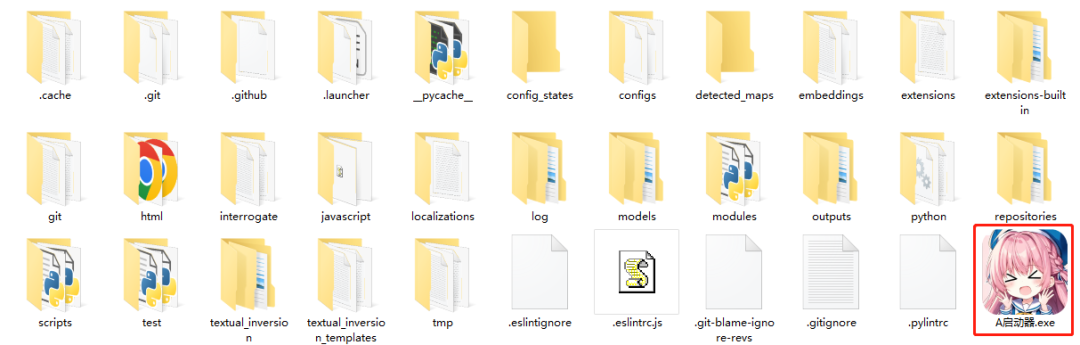
–打开解压好的文件夹,点击“启动器”;

–在启动器页面,点击“一键启动”;

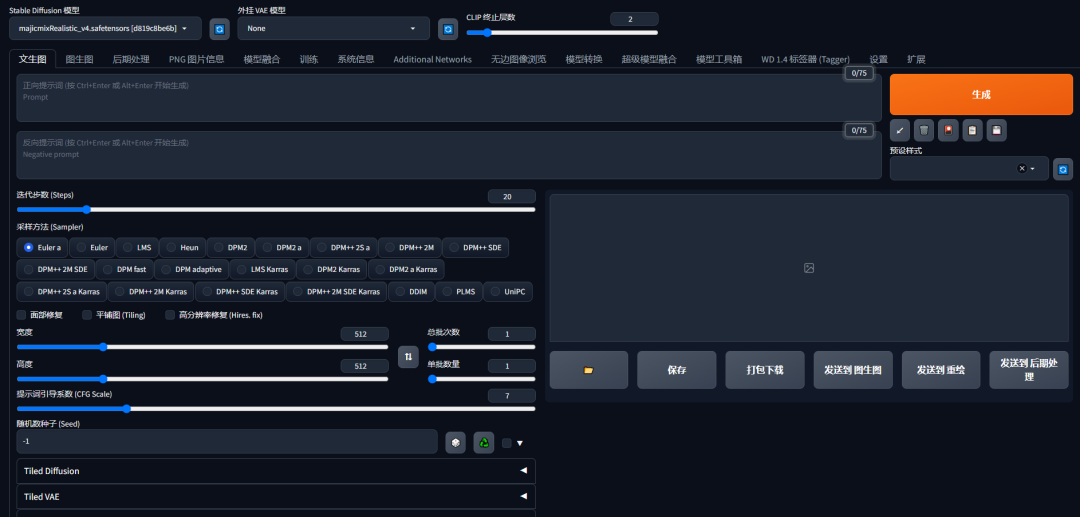
–等待命令窗口加载,完成后会出现你的SD WEB UI页面;

–如果没有出现SD WEB UI页面,可以在命令窗口中“Running on local URL”中找到对应网址。
到这里,SD安装就算完成了!往后的每一次启动都需要点击‘启动器’!需要注意的是,WEB UI是你实现SD功能的操作端,而命令窗口是运行程序的本体。WEB
UI可以关闭再开启,但命令窗口不能关闭,除非你不需要再进行作图!
基于SD在绘图过程中占用较多的性能与显存,所以建议在使用过程中尽量关闭不需要使用的软件/工具。
如果安装的过程中遇到困难,可随时联系!后续阿彼也会更新关于SD的操作指南,感兴趣的小伙伴记得MARK一下。
下面,就让我们来欣赏一下SD生成的图片吧!





资料软件免费放送
次日同一发放请耐心等待
现在AI绘画还是发展初期,大家都在摸索前进。
但新事物就意味着新机会,我们普通人要做的就是抢先进场,先学会技能,这样当真正的机会来了,你才能抓得住。
如果你对AI绘画感兴趣,我可以分享我在学习过程中收集的各种教程和资料。
学完后,可以毫无问题地应对市场上绝大部分的需求。
这份AI绘画资料包整理了Stable Diffusion入门学习思维导图、Stable Diffusion安装包、120000+提示词库,800+骨骼姿势图,Stable Diffusion学习书籍手册、AI绘画视频教程、AIGC实战等等。
完整版资料我已经打包好,点击下方卡片即可免费领取!

【Stable Diffusion学习路线思维导图】
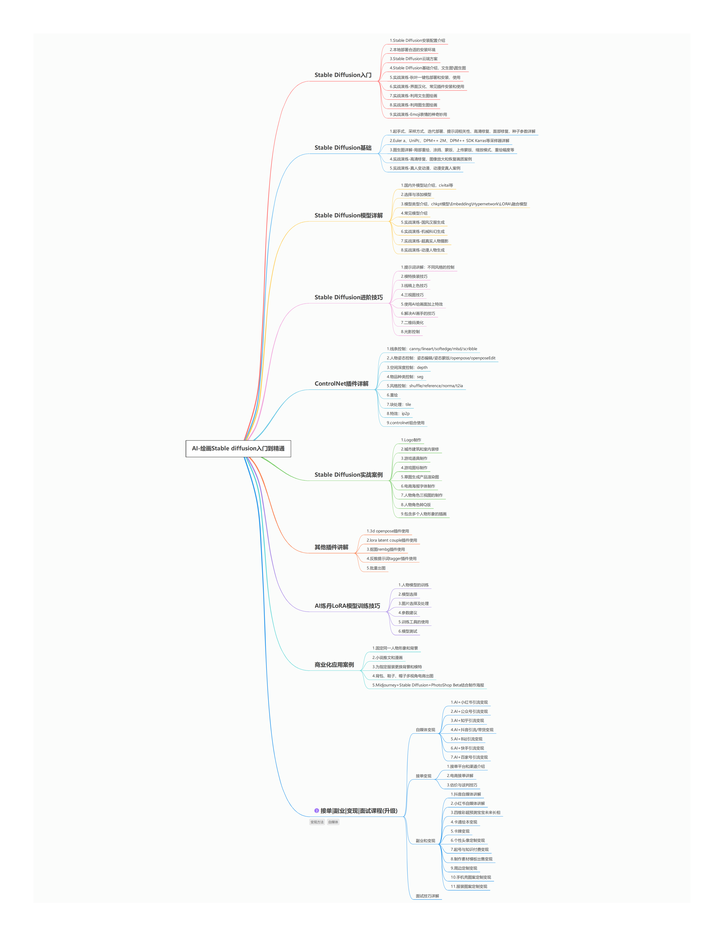
【Stable Diffusion安装包(含常用插件、模型)】
【AI绘画12000+提示词库】
【AI绘画800+骨骼姿势图】

【AI绘画视频合集】
这份完整版的stable diffusion资料我已经打包好,点击下方卡片即可免费领取!



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









