




强化学习常用算法总结
本文为2020年6月参加的百度PaddlePaddle强化学习训练营总结
1. 表格型方法:Sarsa和Q-Learning算法
State-action-reward-state’-action’, 简称Sarsa,是为了建立和优化状态-动作(state-action)的价值Q表格所建立的方法。首先初始化Q表格,根据当前的状态和动作与环境进行交互后,得到奖励reward以及下一步的状态和动作后,对Q表格进行更新;并不断重复这个过程。
Q表格更新公式为:
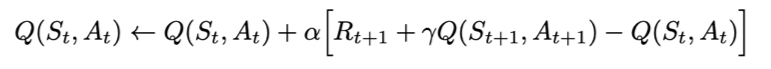
另外,为了保证每一步的探索性,Sarsa在执行下一步时采用e-greedy算法,即根据一定的概率估计来选择下一步的action。Sarsa的这种更新Q表格方式称为“on-policy”方式,即先做出下一步的动作再回头开更新Q值。
与之对应的是“off-policy”方式,即在更新Q表格时,无需知道下一步的动作,而是假设下一步的动作可以取到最大的Q值。基于这种“off-policy”的方法称为Q-Learning算法,其更新Q表格的数学表达式为:
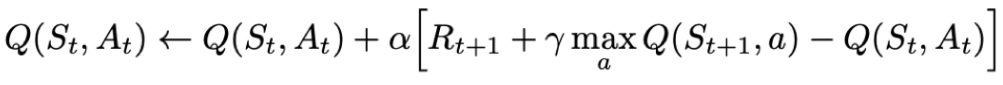
2. 基于神经网络方法:DQN算法
Deep Q-Learning,简称DQN算法是为了解决传统的表格型方法在大规模强化学习任务时遇到的执行效率低,存储量低等问题而提出的算法,它的基本思想是采用神经网络的方式来近似代替Q表格。DQN本质上还是Q-Learning算法,同样为了更好的与环境进行交互,采用e-greedy算法。
DQN的创新在于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2144
2144




 到【灌水乐园】发言
到【灌水乐园】发言







