



混元自研的OCR模型,来了。
11月25日,腾讯混元推出全新开源模型 HunyuanOCR,参数仅为1B,依托于混元原生多模态架构打造,获得多项业界OCR应用榜单SOTA(最先进水平)成绩。

HunyuanOCR 具有高度易用性,不仅体积小,便于部署,得益于混元原生多模态大模型"端到端"的理念设计,各项功能仅需单次前向推理即可直达最优结果,较业界级联方案更高效和便捷,性价比高。
混元OCR专家模型依托于混元原生多模态架构打造,主要由三大部分组建构成:原生分辨率视频编码器、自适应视觉适配器和轻量化混元语言模型。
不同于其他开源的OCR专家模型或系统,HunyuanOCR模型的训练和推理均采用全端到端范式,通过规模化的高质量应用导向数据,结合在线强化学习,模型表现出了非常稳健的端到端推理能力。

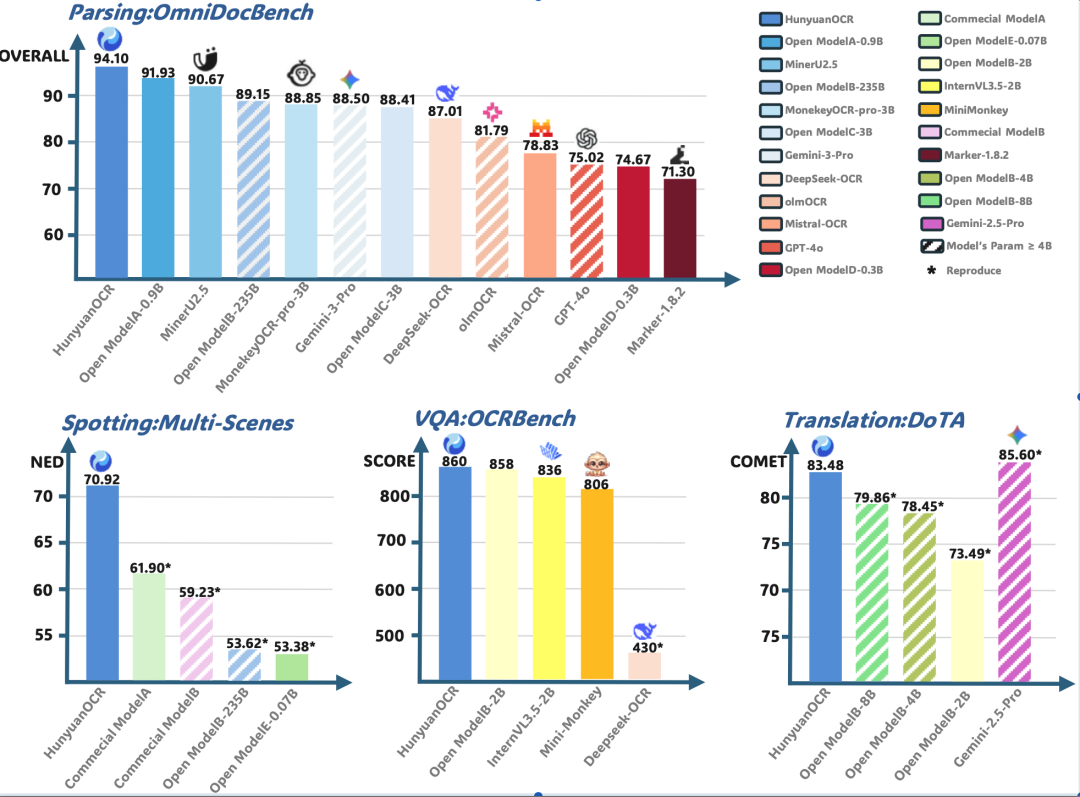
混元OCR多项核心能力达到SOTA效果,其中在复杂文档解析的OmniDocBench测评中,获得了最高的94.1分,效果超过了谷歌的Gemini3-pro等一众领先的模型;文字检测和识别能力,在自建覆盖了9大应用场景(文档、艺术字、街景、手写、广告、票据、截屏、游戏、视频)的基准上,大幅度领先同类开源模型以及商业OCR模型;在OCRBench榜单上,总得分为860分,以仅仅1B总参数的模型配置,取得了包括通用视觉理解模型在内总参数3B以下的SOTA成绩。
在小语种翻译能力,混元OCR支持14种高频小语种翻译翻译中文或英文的效果,并且取得了ICDAR2025端到端文档翻译比赛小模型赛道冠军。
应用场景方面,HunyuanOCR 精通多语种复杂文档解析,同时兼具文字检测和识别能力,在票据字段抽取、视频字幕识别、拍照翻译等场景得到广泛应用。
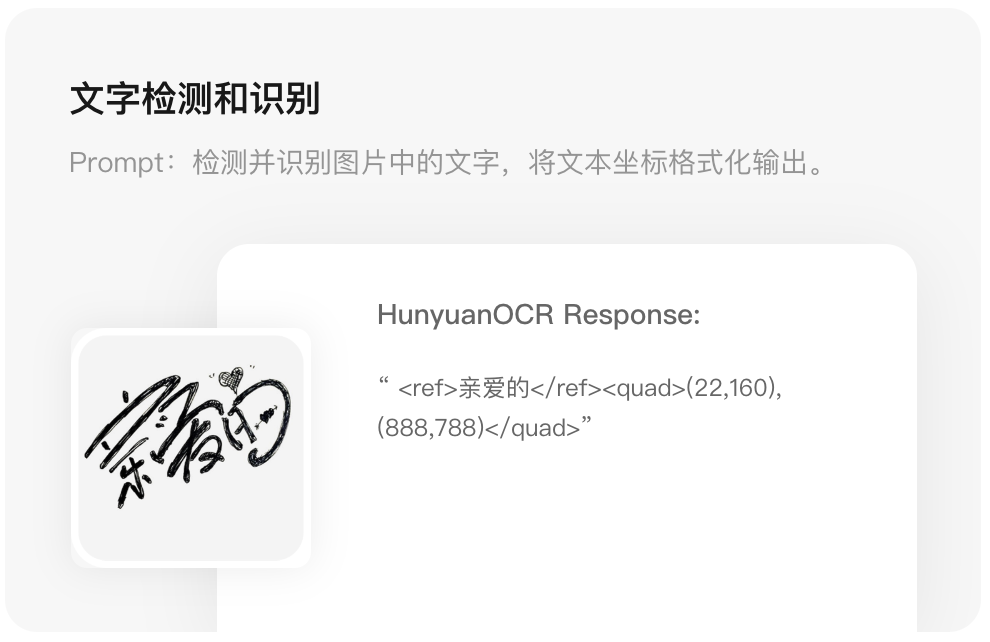
在文字检测和识别能力上,模型对文档、艺术字、街景、手写、广告、票据、截屏、游戏、视频等场景上表现卓越。
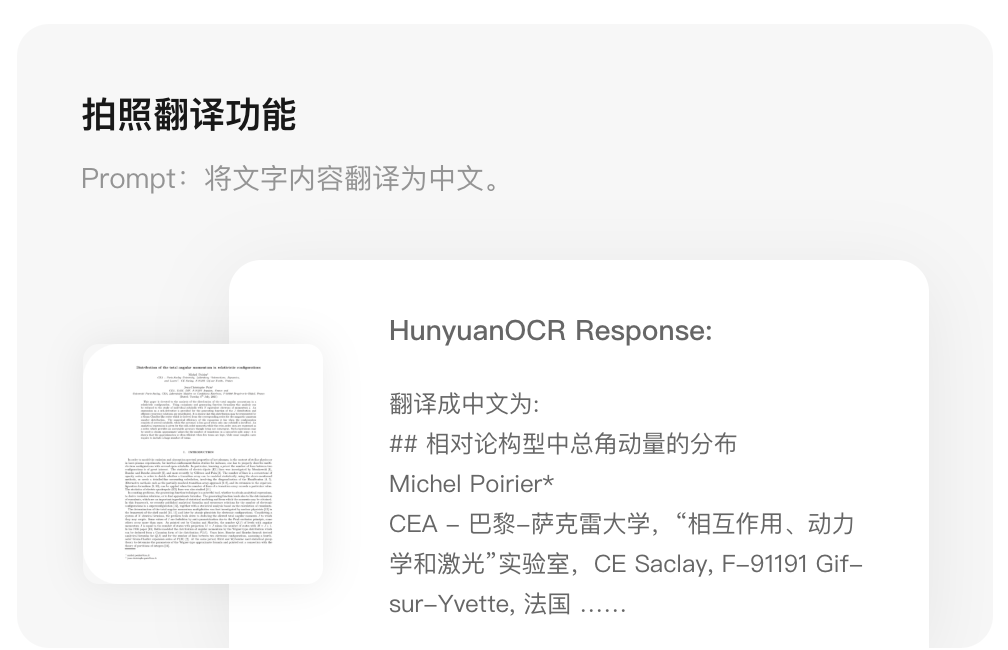
复杂文档解析指的是对多语种文档扫描件或拍摄图像进行电子化,具体地,就是将图片中出现的文本内容按照阅读顺序进行组织、公式采用Latex格式、复杂表格采用HTML格式表达。

此外常见的应用场景还要票据字段提取、视频字幕提取和拍照翻译等功能。
1、 对常见卡证和票据的感兴趣字段(如姓名/地址/单位等),采用标准的json格式解析。

2、 对视频的字幕实现自动化抽取,包括双语字幕。

3、拍照翻译功能,支持14种高频应用小语种,具体包括:德语、西班牙语、土耳其语、意大利语、俄语、法语、葡萄牙语、阿拉伯语、泰语、越南语、印尼语、马来语、日语、韩语翻译成中/英文,以及中英互译功能。
欢迎下载使用体验,发掘更多应用场景。
——项目地址——
web端:https://hunyuan.tencent.com/vision/zh?tabIndex=0
移动端:https://hunyuan.tencent.com/open_source_mobile?tab=vision&tabIndex=0
——开源地址——
https://github.com/Tencent-Hunyuan/HunyuanOCR
https://huggingface.co/tencent/HunyuanOCR
直接体验:https://huggingface.co/spaces/tencent/HunyuanOCR
点击阅读原文获取技术报告。
关注腾讯开源公众号
获取更多最新腾讯官方开源信息!

















 2284
2284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









