



 本文详细对比了ArrayList和LinkedList在不同场景下的性能表现,包括查询、插入操作的时间复杂度及空间复杂度。通过实例测试,展示了ArrayList在随机访问上的优势,而LinkedList在头部插入操作中的高效。
本文详细对比了ArrayList和LinkedList在不同场景下的性能表现,包括查询、插入操作的时间复杂度及空间复杂度。通过实例测试,展示了ArrayList在随机访问上的优势,而LinkedList在头部插入操作中的高效。
List接口下,ArrayList、vector和LinkedList区别
一 .体系结构图
在正式开始前,我们些梳理一下List接口下的结构图
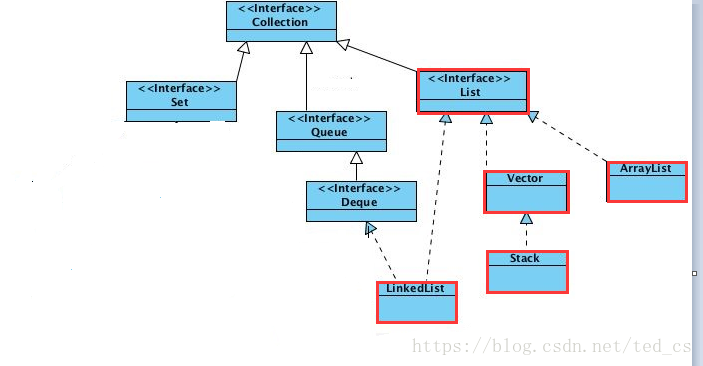
有了结构概念后,我们再来慢慢趴掉List接口的衣服,看清它的内在
二.List速记卡
福利 : List速记卡
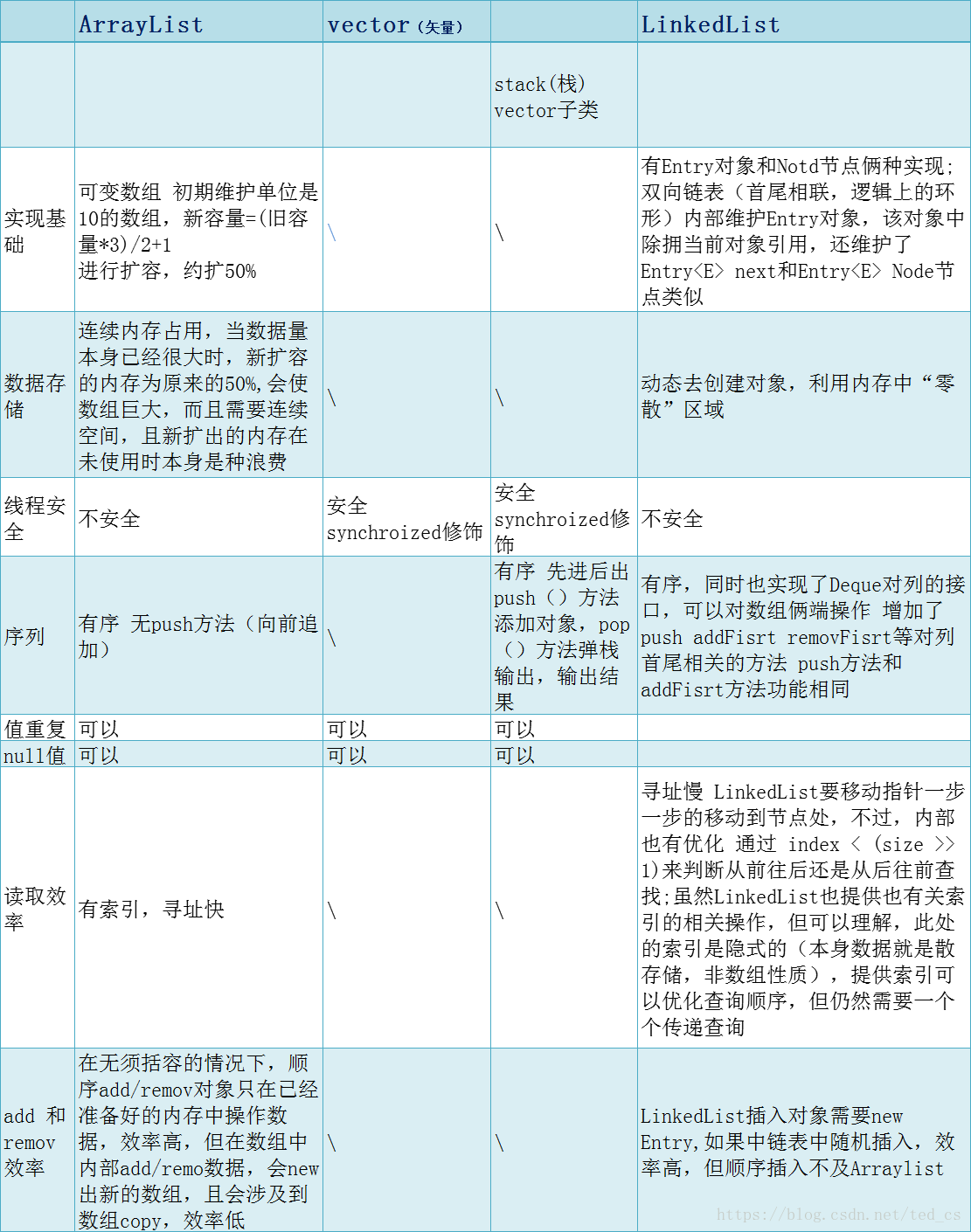
三. ArrayList和LinkedList介绍
ArrayList和LinkedList的概念性介绍,我不再赘述,上面的速记卡中其实已然很清楚,而俩者的介绍也一般是在对比中开展的;
ArrayList数据结构为数组,相对比较容易理解;LinkedList数据结构为双向链表结构,实现基础是类中维护Entry对象或Node节点来完成,值得推敲
具体可以看本人如下俩篇博文,很有必要
LinkedList源码解析 基于Node结构
LinkedList源码解析 基于Entry结构 以及链表介绍
以下主要从时间复杂度 和空间复杂度 俩方面做出剖析

情景一: 插入操作
首先一点关键的是,ArrayList的内部实现是基于基础的对象数组的,因此,它使用get方法访问列表中的任意一个元素时(random-access),它的速度要比LinkedList快。LinkedList中的get方法是按照顺序从列表的一端开始检查,直到另外一端。对LinkedList而言,访问列表中的某个指定元素没有更快的方法了。
假设我们有一个很大的列表,它里面的元素已经排好序了,这个列表可能是ArrayList类型的也可能是LinkedList类型的,现在我们对这个列表来进行二分查找(binary search),比较列表是ArrayList和LinkedList时的查询速度,看下面的程序:
package com.mangocity.test;
import java.util.LinkedList;
import java.util.List;
import java.util.Random;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
public class TestList ...{
public static final int N=50000;
public static List values;
static...{
Integer vals[]=new Integer[N];
Random r=new Random();
for(int i=0,currval=0;i<N;i++)...{
vals=new Integer(currval);
currval+=r.nextInt(100)+1;
}
values=Arrays.asList(vals);
}
static long timeList(List lst)...{
long start=System.currentTimeMillis();
for(int i=0;i<N;i++)...{
int index=Collections.binarySearch(lst, values.get(i));
if(index!=i)
System.out.println("***错误***");
}
return System.currentTimeMillis()-start;
}
public static void main(String args[])...{
System.out.println("ArrayList消耗时间:"+timeList(new ArrayList(values)));
System.out.println("LinkedList消耗时间:"+timeList(new LinkedList(values)));
}
}
ArrayList消耗时间:15
LinkedList消耗时间:2596
这个结果不是固定的,但是基本上ArrayList的时间要明显小于LinkedList的时间。因此在这种情况下不宜用LinkedList。二分查找法使用的随机访问(randomaccess)策略,而LinkedList是不支持快速的随机访问的。对一个LinkedList做随机访问所消耗的时间与这个list的大小是成比例的。而相应的,在ArrayList中进行随机访问所消耗的时间是固定的。
这是否表明ArrayList总是比LinkedList性能要好呢?这并不一定,在某些情况下LinkedList的表现要优于ArrayList,有些算法在LinkedList中实现时效率更高。比方说,利用Collections.reverse方法对列表进行反转时,其性能就要好些。
情景二: 插入操作
package com.mangocity.test;
import java.util.*;
public class ListDemo {
static final int N=50000;
static long timeList(List list){
long start=System.currentTimeMillis();
Object o = new Object();
for(int i=0;i<N;i++)
list.add(0, o);
return System.currentTimeMillis()-start;
}
public static void main(String[] args) {
System.out.println("ArrayList耗时:"+timeList(new ArrayList()));
System.out.println("LinkedList耗时:"+timeList(new LinkedList()));
}
}
ArrayList耗时:2463
LinkedList耗时:15
当一个元素被加到ArrayList的最开端时,所有已经存在的元素都会后移,内部会new出新的数组调用Copy方法来接收新的数据,这就意味着数据移动和复制上的开销。
相反的,将一个元素加到LinkedList的最开端只是简单的为这个元素分配一个记录,然后只在修改内部Entry或Node的引用便可。
在LinkedList的开端增加一个元素的开销是固定的,而在ArrayList的开端增加一个元素的开销是与ArrayList的大小成比例的。
以面这个例子比较浅显,但为什么ArrayList和LinkedList在查询过程中差距如此大,强烈建议查看本人以下博文,通过源码来探讨根本。
切勿用普通for循环遍历LinkedList

在LinkedList中有一个私有的内部类,定义如下:
private static class Entry {
Object element;
Entry next;
Entry previous;
}
(或者定义的是Node节点,和Entry相似,都是双向链表结构)
每个Entry对象reference列表中的一个元素,同时还有在LinkedList中它的上一个元素和下一个元素。一个有1000个元素的LinkedList对象将有1000个链接在一起的Entry对象,每个对象都对应于列表中的一个元素。这样的话,在一个LinkedList结构中将有一个很大的空间开销,因为它要存储这1000个Entity对象的相关信息,但因为它可以使用内存中“零散”的内存空间,而且,只有新增Entry时才会创建新的对象,相对来ArrayList有优势。
ArrayList使用一个内置的数组来存储元素(存储数据有序且占用连续内存),这个数组的起始容量是10.当数组需要增长时,新的容量按如下公式获得:新容量=(旧容量*3)/2+1,也就是说每一次容量大概会增长50%。这就意味着,如果你有一个包含大量元素的ArrayList对象,那么最终将有很大的空间会被浪费掉,这个浪费是由ArrayList的工作方式本身造成的。如果没有足够的空间来存放新的元素,数组将不得不被重新进行分配以便能够增加新的元素。对数组进行重新分配,将会导致性能急剧下降。如果我们知道一个ArrayList将会有多少个元素,我们可以通过构造方法来指定容量。我们还可以通过trimToSize方法在ArrayList分配完毕之后去掉浪费掉的空间。
三. vector和Stack介绍
在理解ArrayList的基础上,再去理解vector和stack就很容易了,因为它们的实现底层都是通过可这数组来完成的,以下整理出概要,方便速记
- vector和stack是线程安全的,因为它们的方法上有Synchrozied同步锁,ArrayList则是线程不安全的
- stack 遵守数据先进后出原则 push()方法添加对象,pop()方法弹栈输出,输出结果
具体原码可查看外部博文,讲解很到位
Java 集合系列06之 Vector详细介绍(源码解析)和使用示例
End!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









