




 这篇博客深入探讨了Linux内核中的信号处理机制,重点关注4.19版本的最新代码变化。文章通过分析`arch/arm/kernel/signal.c`和`arch/arm/kernel/entry-common.S`中的关键函数,如`ret_to_user`、`slow_work_pending`和`do_work_pending`,揭示了信号如何影响用户态到内核态的转换以及工作队列的处理流程。
这篇博客深入探讨了Linux内核中的信号处理机制,重点关注4.19版本的最新代码变化。文章通过分析`arch/arm/kernel/signal.c`和`arch/arm/kernel/entry-common.S`中的关键函数,如`ret_to_user`、`slow_work_pending`和`do_work_pending`,揭示了信号如何影响用户态到内核态的转换以及工作队列的处理流程。
normal prio static_prio 处理关系
信号处理:
1. 为当前进程,中断或系统调用时返回 用户空间
2. 如果进程在没有运行,则需要调用signal_wake_up 函数把目标进程唤醒。 对于smp ,则需要发送一个RESCHEDULE_VECTOR 中断
linux 调度类:
TIF_NEED_RESCHED , 调度器根据此标志来决定是否选择下一个进程运行。
置位地方:
resched_task set_tsk_need_resched wake_up_idle_cpu
调度器类函数: task_tick_rt 调用set_tsk_need_resched 置位
进程重要性的决定:进程权重、优先级
调度器
周期性调度器: scheduler_tick
1. 进程调度相关统计量 2. task_tick (cifs 检测线程运行时间是否过长,如是设置TIF_NEED_RESCHED)
主调度器: schedule
周期性调度器只会置需要调度标志位
如果内核抢占被关闭,则内核进程在不主动让出cpu的情况下,将不能被打断。如jffs2垃圾扫描进程。
内核空间抢占:
中断返回内核空间前
用户空间抢占:
系统调用返回用户空间前
中断返回用户空间前
TIF_NEED_RESCHED,进程表示要抢占其他进程时会置此标志位。 被置位的地方?
cond_resched () 保证某进程不会占用太多cpu时间。 在大量占用cpu多的地方可以适量加入cond_rescehd 函数
调度点:
1. 主动切换 2. 中断返回 3.系统调用返回
调度函数:
ret_from_syscall (ppc) 代码分析
| sysret_careful: bt $TIF_NEED_RESCHED,%edx jnc sysret_signal TRACE_IRQS_ON ENABLE_INTERRUPTS(CLBR_NONE) pushq %rdi CFI_ADJUST_CFA_OFFSET 8 call schedule popq %rdi CFI_ADJUST_CFA_OFFSET -8 jmp sysret_check /* Handle a signal */ |
ENDPROC(system_call)
# perform work that needs to be done immediately before resumption
ALIGN
RING0_PTREGS_FRAME# can't unwind into user space anyway
work_pending:
testb $_TIF_NEED_RESCHED, %cl
jz work_notifysig
work_resched:
call schedule
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY)# make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx
andl $_TIF_WORK_MASK, %ecx# is there any work to be done other
# than syscall tracing?
jz restore_all
testb $_TIF_NEED_RESCHED, %cl
jnz work_resched
# perform work that needs to be done immediately before resumption
ALIGN
RING0_PTREGS_FRAME# can't unwind into user space anyway
work_pending:
testb $_TIF_NEED_RESCHED, %cl
jz work_notifysig
work_resched:
call schedule
LOCKDEP_SYS_EXIT
DISABLE_INTERRUPTS(CLBR_ANY)# make sure we don't miss an interrupt
# setting need_resched or sigpending
# between sampling and the iret
TRACE_IRQS_OFF
movl TI_flags(%ebp), %ecx
andl $_TIF_WORK_MASK, %ecx# is there any work to be done other
# than syscall tracing?
jz restore_all
testb $_TIF_NEED_RESCHED, %cl
jnz work_resched
ret_from_int
打开内核抢占: 在中断返回到内核态增加抢占点,调用schedule 。preempt_enable-> preempt_schedule
| #ifdef CONFIG_PREEMPT ENTRY(resume_kernel) DISABLE_INTERRUPTS(CLBR_ANY) cmpl $0,TI_preempt_count(%ebp) # non-zero preempt_count ? jnz restore_all need_resched: movl TI_flags(%ebp), %ecx # need_resched set ? testb $_TIF_NEED_RESCHED, %cl jz restore_all testl $X86_EFLAGS_IF,PT_EFLAGS(%esp) # interrupts off (exception path) ? jz restore_all call preempt_schedule_irq jmp need_resched END(resume_kernel) #endif asmlinkage void __sched preempt_schedule_irq(void) { struct thread_info *ti = current_thread_info(); /* Catch callers which need to be fixed */ BUG_ON(ti->preempt_count || !irqs_disabled()); do { add_preempt_count(PREEMPT_ACTIVE); local_irq_enable(); schedule(); local_irq_disable(); sub_preempt_count(PREEMPT_ACTIVE); /* * Check again in case we missed a preemption opportunity * between schedule and now. */ barrier(); } while (need_resched()); } |
preempt_disable 只对开了抢占的内核有用。 因为如果没开抢占,内核态不可能被切换出去,在内核态运行时不会发生切换的。
spin_lock 在单核里面是空函数,开了抢占是preempt_disable函数
使用
struct thread_info *ti = current_thread_info(); ti->preempt_count
调度函数理解:
等待时间最长的会放到红黑树的最左边。
调度器考虑的优先级保存在prio 里面。
sched_rt.c static const struct sched_class rt_sched_class 定义调度类的实现函数
调度实体记录进程的统计信息。
进程优先级理解:
动态优先级:prio (effective_prio 函数计算) 静态优先级:static_prio 普通优先级:normal_prio
rt_priority 越高代表优先级越高。 内核内部优先级数字越小,优先级越高。
普通进程: prio 即为 static_prio
实时优先级: prio为MAX_RT_PRIO -1- P->rt_priority
nice改变进程静态优先级
#define NICE_TO_PRIO(nice) (MAX_RT_PRIO + (nice) + 20)
p->static_prio = NICE_TO_PRIO(nice);
技巧:
搜索调度相关函数,搜索关键字 __sched
疑问:
调度抢占 标志位 TIF_NEED_RESCHED PREMPT_ACTIVE
开抢占后相关代码研究 ,内核抢占代码研究
中断和系统调用切换点过程函数了解 , 调度点研究
1. 调度时机,调度器被调用的地方?
2. 实际始终和 虚拟时钟关系
3. nice 的设置地方 用户态线程
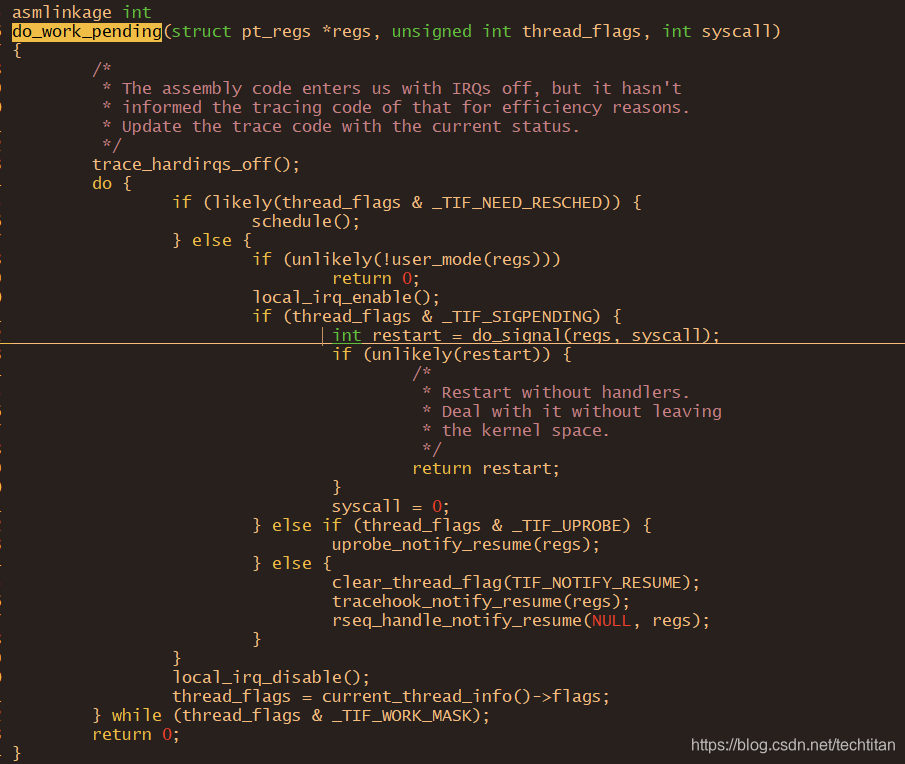
- 4.19 内核最新代码分析
arch/arm/kernel/signal.c
arch/arm/kernel/entry-common.S
ret_to_user -》 slow_work_pending -》 do_work_pending

















 3943
3943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









