




 本文主要介绍Python中pandas库在电影数据集上的join操作。先给出电影评分数据集,包含用户评分、用户信息和电影本身数据。接着展示读取数据及表内连接示例,还阐述merge时一对一、一对多、多对多关系的数量对齐,最后说明left join、right join、inner join、outer join的区别。
本文主要介绍Python中pandas库在电影数据集上的join操作。先给出电影评分数据集,包含用户评分、用户信息和电影本身数据。接着展示读取数据及表内连接示例,还阐述merge时一对一、一对多、多对多关系的数量对齐,最后说明left join、right join、inner join、outer join的区别。
语法介绍

电影数据集的join示例
电影评分数据集:是推荐系统研究的很好的数据集,本次用到的是
1.用户对电影的评分数据 ratings.csv
2.用户本身的信息数据 users.csv
3.电影本身数据movies.csv
数据集官方地址
读取数据
读取评分表
df_ratings = pd.read_csv(
"../data/ml-25m/ratings.csv",
# sep=",",
# engine='python',
# names="userId,movieId,rating,timestamp".split(",")
low_memory=False
)
print(df_ratings.head())
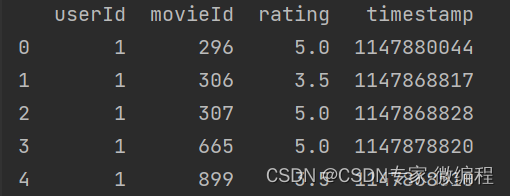
读取用户表和电影表
df_users = pd.read_csv( "../data/ml-25m/users.csv")
df_movies = pd.read_csv( "../data/ml-25m/movies.csv")
用户和评分表内连接
df_ratings_users = pd.merge(
df_ratings, df_users, left_on='userId', right_on='userId', how='inner'
)
print(df_ratings_users)
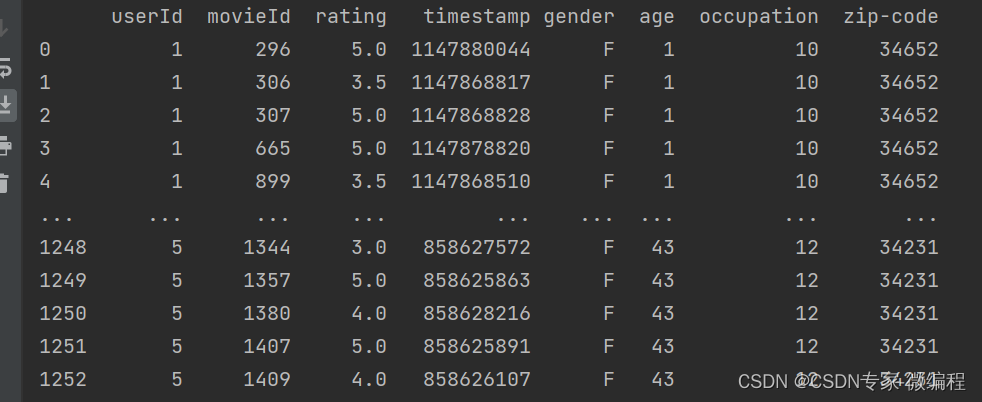
用户和评分表,电影表内连接
df_ratings_users_movies = pd.merge(
df_ratings_users, df_movies, left_on="movieId", right_on="movieId", how="inner"
)
print(df_ratings_users_movies.head(6))
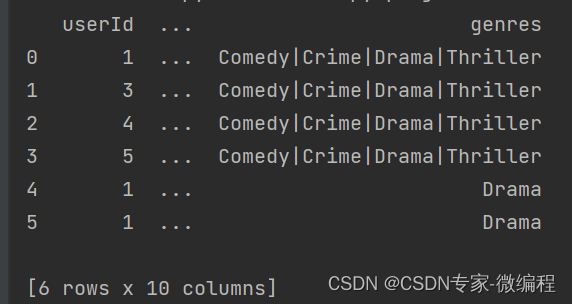
merge时数量的对齐关系
-
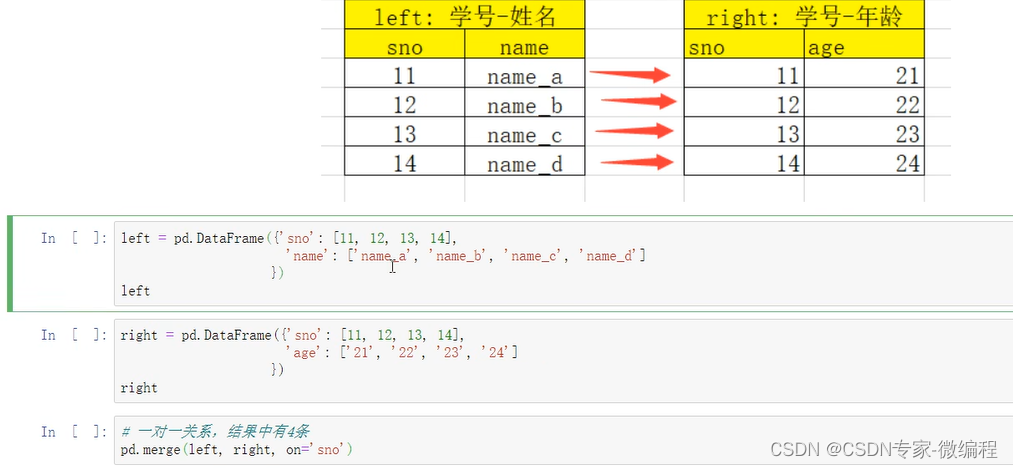
one-to-one:一对一关系,关联的key都是唯一的
比如(学号,姓名)merge(学号,年龄)
结果条数为:1*1 -
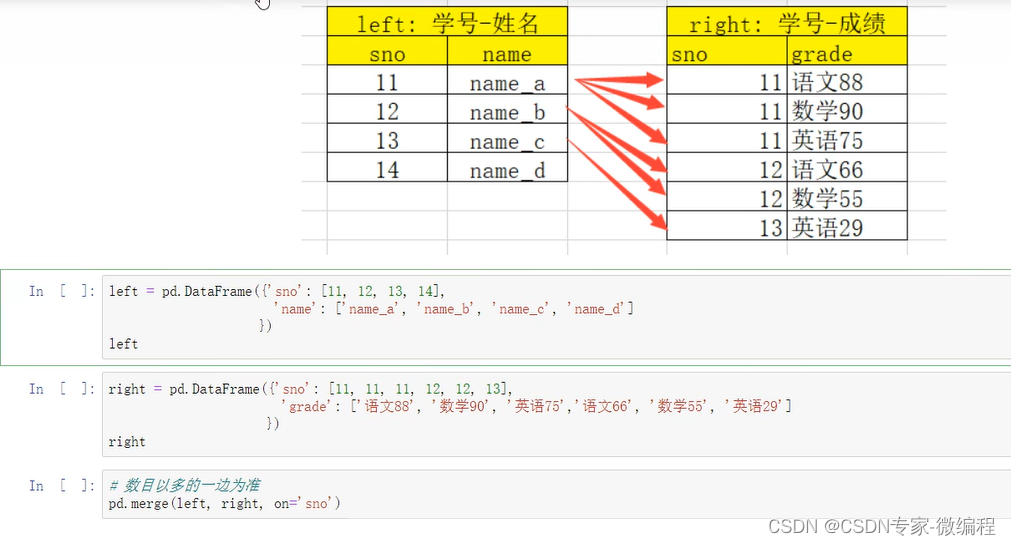
one-to-many:一对多关系,左边唯一key,右边不唯一key
比如(学号,姓名)merge(学号,[语文成绩、数学成绩、英语成绩])
结果条数为:1*N -
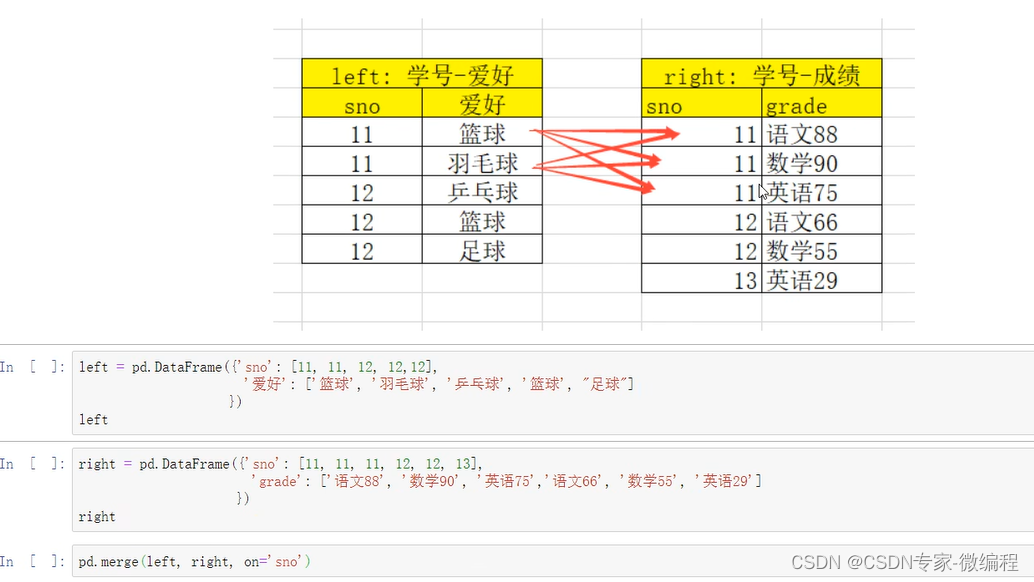
many-to-many:多对多关系,左边右边都不是唯一的
-比如(学号,[语文成绩、数学成绩、英语成绩]) merge(学号,[篮球、足球])
结果条数:M*N
one-to-one 一对一的merge
one-to-many 一对多关系的merge
注意:数据会被复制
many-to-many 多对多关系的merge
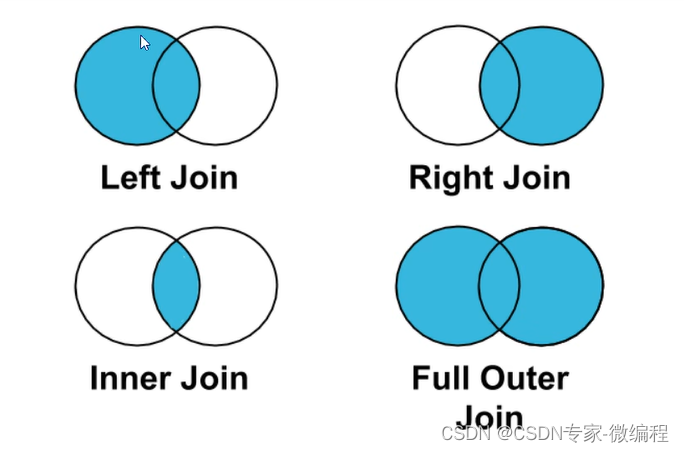
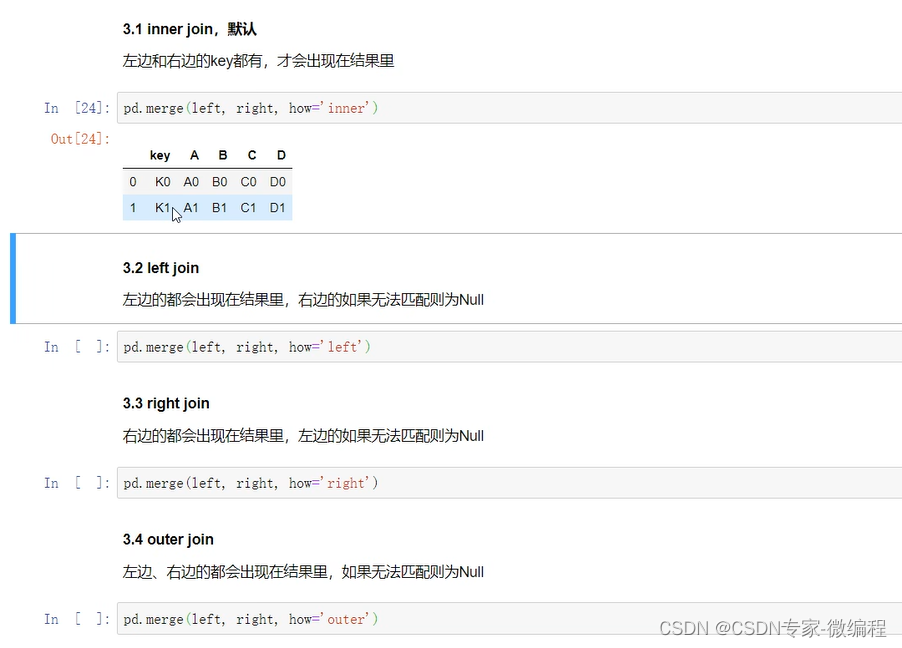
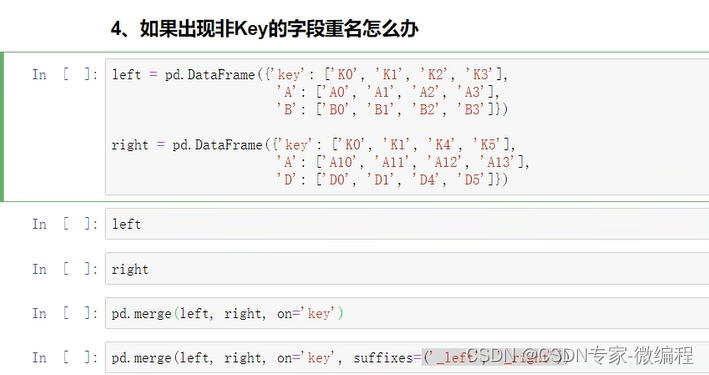
lef join、right join、inner join、outer join的区别
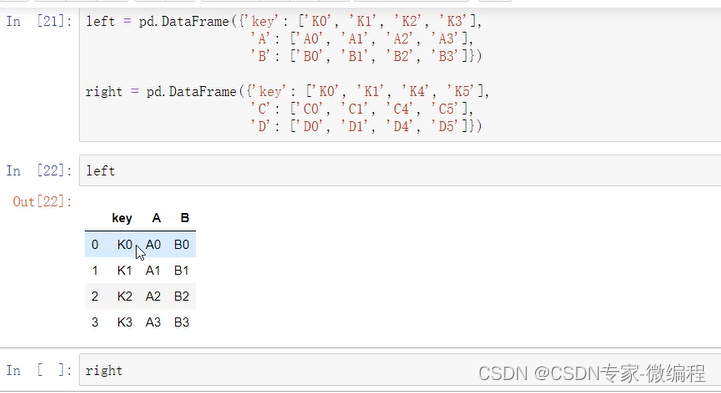


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









