




 本文介绍了一种天气数据预处理的方法,包括读取CSV文件、设置日期为索引、清洗温度数据等步骤,并概述了几种数据查询方式:单个label查询、列表批量查询、数值区间查询、条件表达式查询及函数查询。
本文介绍了一种天气数据预处理的方法,包括读取CSV文件、设置日期为索引、清洗温度数据等步骤,并概述了几种数据查询方式:单个label查询、列表批量查询、数值区间查询、条件表达式查询及函数查询。

数据预处理
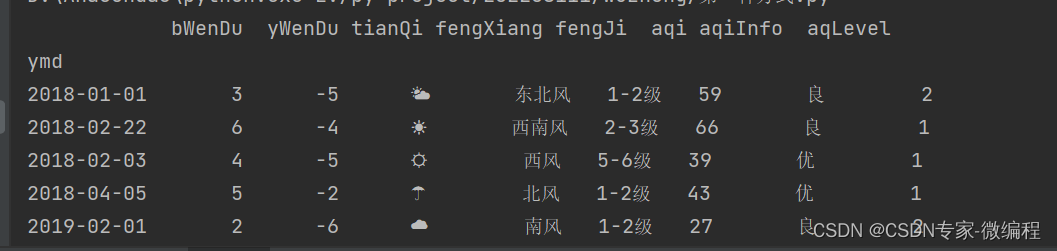
tianqi数据如下
ymd,bWenDu,yWenDu,tianQi,fengXiang,fengJi,aqi,aqiInfo,aqLevel
2018-01-01,3°C,-5°C,🌤,东北风,1-2级,59,良,2
2018-02-22,6°C,-4°C,☀,西南风,2-3级,66,良,1
2018-02-03,4°C,-5°C,☼,西风,5-6级,39,优,1
2018-04-05,5°C,-2°C,☂,北风,1-2级,43,优,1
2019-02-01,2°C,-6°C,☁,南风,1-2级,27,良,2
2019-10-23,3°C,-1°C,🌤,东风,1-2级,18,良,2
import pandas as pd
df = pd.read_csv("../data/tianqi.csv")
# print(df.head())
# 设置以索引为日期,方便筛选
df.set_index('ymd', inplace=True)
# 替换掉温度的后缀
df.loc[:, "bWenDu"] = df["bWenDu"].str.replace("°C", "").astype('int32')
df.loc[:, "yWenDu"] = df["yWenDu"].str.replace("°C", "").astype('int32')
1.使用单个label值查询
行或者列,都可以只传入单个值,实现匹配

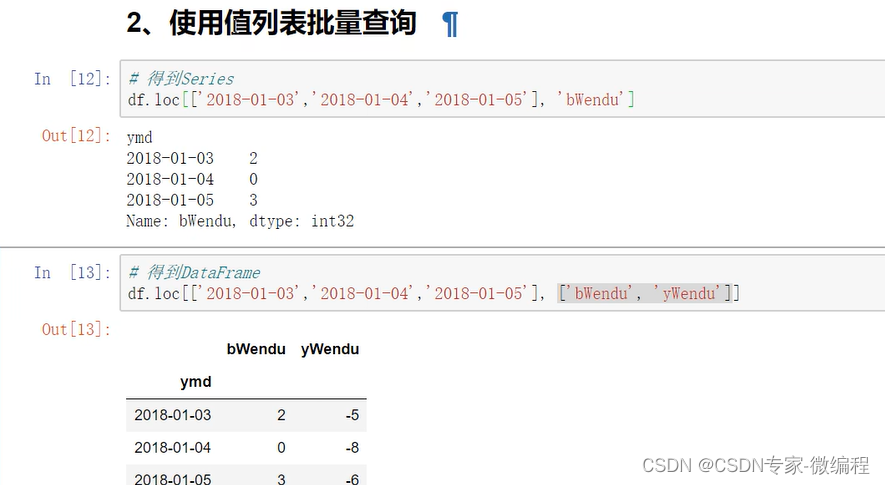
2.使用值列表批量查询
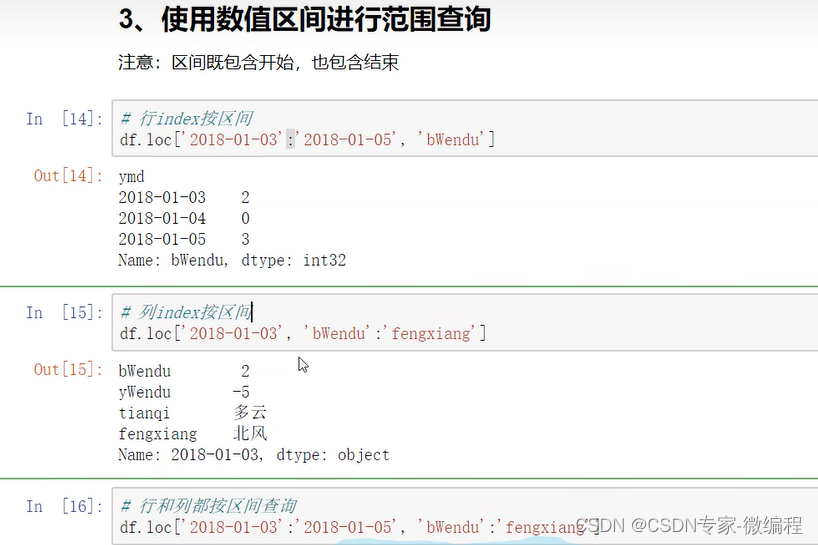
3.使用数值区间进行范围查询
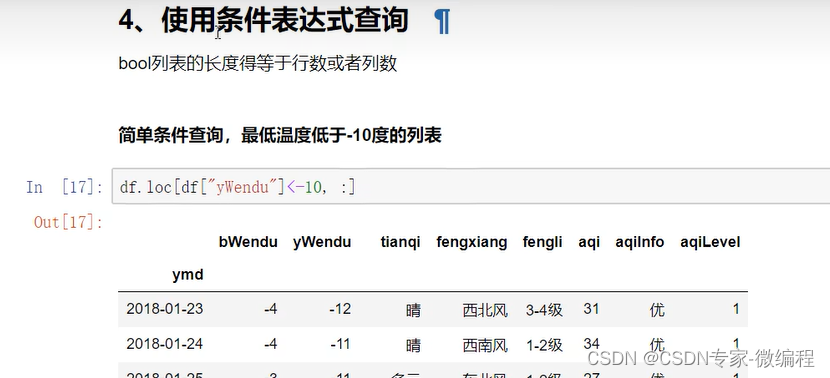
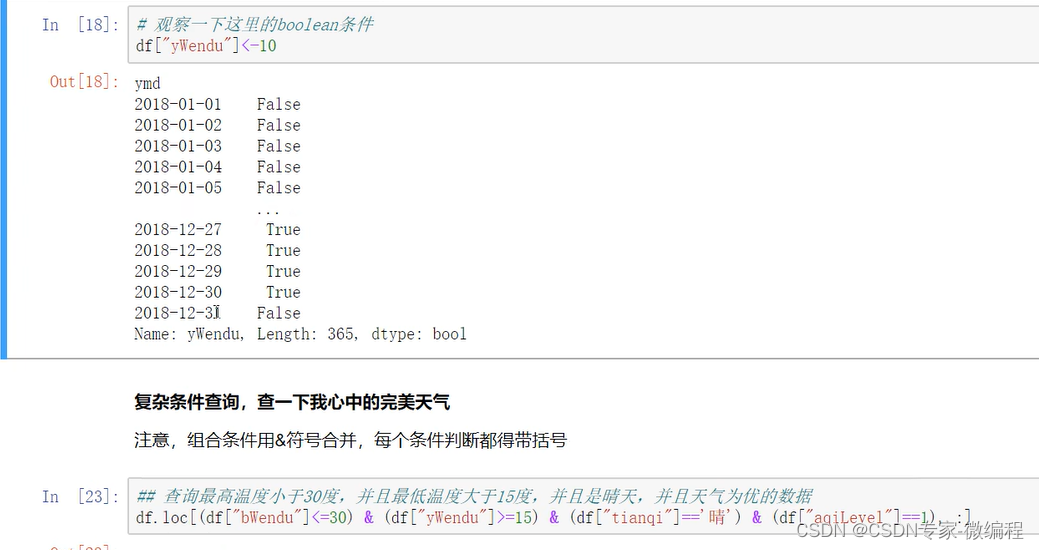
4.使用条件表达式查询
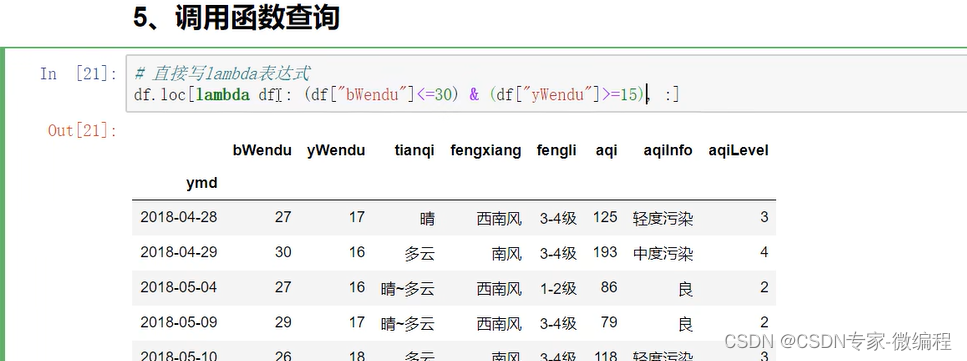
5.调用函数查询
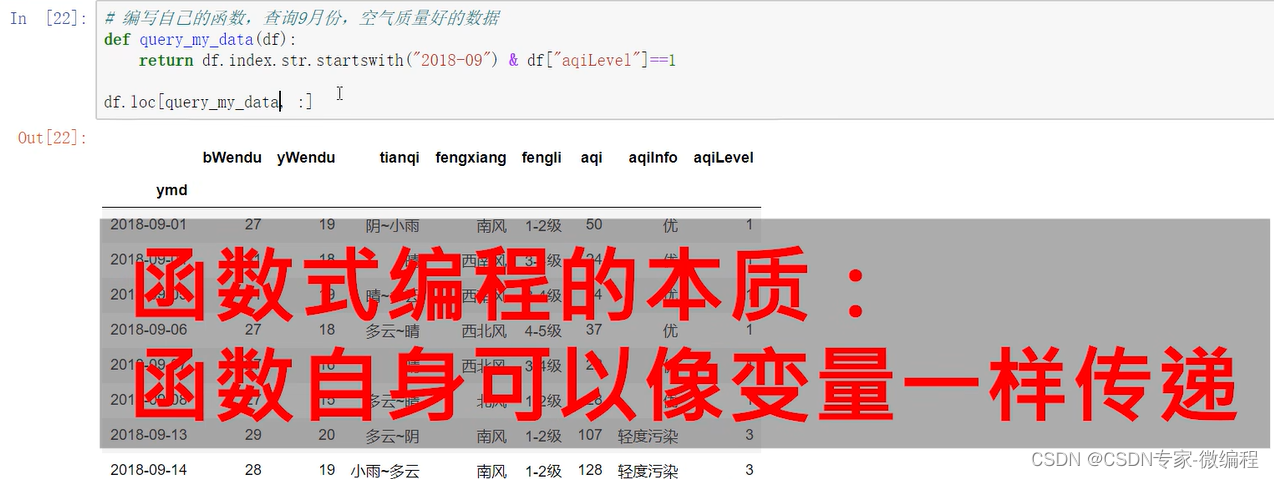

















 1457
1457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









