代码
import requests
import re
import os
baiduurl = r'https://image.baidu.com/search/fileindex?ct=201326592&cl=2&st=-1&lm=-1&nc=1&ie=utf-8&tn=baiduimage&ipn=r&rps=1&pv=&fm=rs1&word=%E5%B0%8F%E7%8C%AA%E8%93%9D%E8%80%B3%E7%97%85%E7%9A%84%E7%97%87%E7%8A%B6%E5%9B%BE%E7%89%87&oriquery=%E8%93%9D%E8%80%B3%E7%97%85%20%E7%94%9F%E7%8C%AA&ofr=%E8%93%9D%E8%80%B3%E7%97%85%20%E7%94%9F%E7%8C%AA&sensitive=0'
dirpath = r'C:\Users\teavamc\Desktop\pigpick'
html = requests.get(baiduurl).text
picsourceurl = re.findall(r'"objURL":"(.*?)"', html)
if not os.path.isdir(dirpath):
os.mkdir(dirpath)
fileindex = 1
for baiduurl in picsourceurl:
print("Downloading:", baiduurl)
try:
res = requests.get(baiduurl)
if str(res.status_code)[0] == "4":
print("未下载成功:", baiduurl)
continue
except Exception as e:
print("未下载成功:", baiduurl)
filename = os.path.join(dirpath, str(fileindex) + ".jpg")
with open(filename, 'wb') as f:
f.write(res.content)
fileindex += 1
print("下载结束,一共 %s 张图片" % fileindex)
运行结果
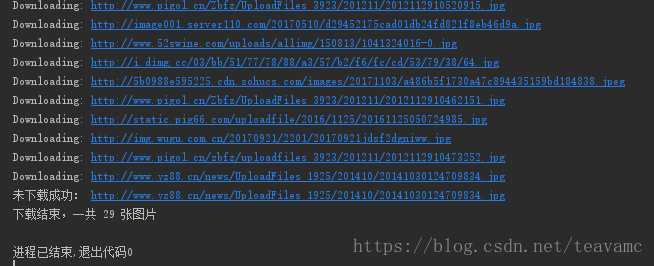
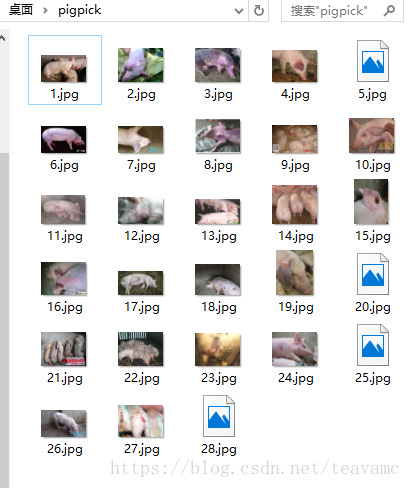
效果





 本文介绍了一种使用Python爬取百度图片的方法。通过发送GET请求获取图片链接,并利用正则表达式解析图片源地址,最后批量下载图片至指定目录。文章详细展示了从请求构造到图片下载的全过程。
本文介绍了一种使用Python爬取百度图片的方法。通过发送GET请求获取图片链接,并利用正则表达式解析图片源地址,最后批量下载图片至指定目录。文章详细展示了从请求构造到图片下载的全过程。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









