






 这篇博客详细介绍了RPN(Region Proposal Network)的训练过程,包括使用反向传播和SGD优化,以及采样策略。在训练中,通过随机采样平衡正负样本,采用特定的超参数设置,如学习率和权重衰减。此外,讨论了两种训练策略:交替训练和近似联合训练。交替训练在精度和效率之间取得了平衡,而近似联合训练则减少了训练时间。在实现细节上,博客提到了单尺度训练、锚框设置以及NMS后的处理步骤,展示了如何在实际应用中提高效率和性能。
这篇博客详细介绍了RPN(Region Proposal Network)的训练过程,包括使用反向传播和SGD优化,以及采样策略。在训练中,通过随机采样平衡正负样本,采用特定的超参数设置,如学习率和权重衰减。此外,讨论了两种训练策略:交替训练和近似联合训练。交替训练在精度和效率之间取得了平衡,而近似联合训练则减少了训练时间。在实现细节上,博客提到了单尺度训练、锚框设置以及NMS后的处理步骤,展示了如何在实际应用中提高效率和性能。
训练RPN网络
RPN可以通过反向传播和随机梯度下降(SGD)进行端到端的训练
采样策略:以图像为中心
考虑到单个图像会产生很多的负样本,对所有锚框的损失函数进行优化会导致网络偏向负样本。我们在一幅图像中随机采样256个锚框来计算一个小批量的损失函数,其中采样的正负锚框的锚框比高达1:1。 如果一幅图像中的正样本少于128个,我们就用负样本填充。
超参数设置:
- 随机初始化所有的新层。随机值满足均值为0,方差为0.01的正态分布
- 所有其他层使用ImageNet分类模型的预训练权重
- 在VOC数据集上,对于前60K小批量,使用
1e-3的学习率,对于接下来的20K小批量,使用1e-4的学习率 - 动量为0.9,权重衰减
5e-4
Fast R-CNN和RPN的共享特征
接下来描述由 RPN 和 Fast R-CNN 组成的统一网络的算法,该网络具有共享的卷积层
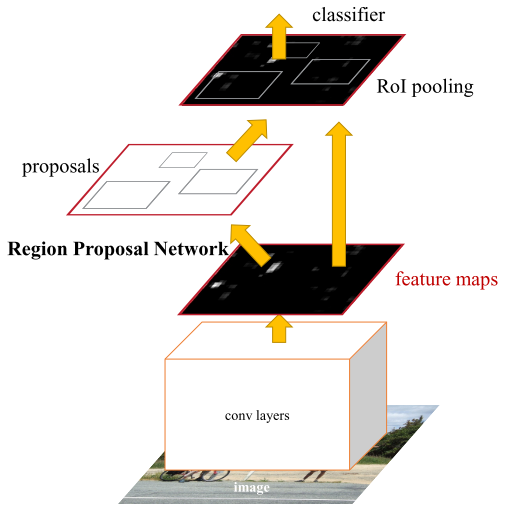
独立训练的 RPN 和 Fast R-CNN 都会以不同的方式修改它们的卷积层。 因此需要开发一种技术,允许在两个网络之间共享卷积层,而不是学习两个单独的网络。
论文使用交替训练的方法。
在这个方案中,我们首先训练 RPN,然后使用生成的候选区域来训练 Fast R-CNN。 然后用 Fast R-CNN 调优的网络来初始化 RPN,这个过程是迭代的。
其他的训练方法:
近似联合训练。 在此解决方案中,RPN 和 Fast R-CNN 网络在训练期间合并为一个网络。在每次 SGD 迭代中,前向传递生成候选区域(这些区域在训练Fast R-CNN检测器时被视为固定的、预先计算的区域)。反向传播像往常一样发生,对于共享层,来自 RPN 的损失和 Fast R-CNN 损失的反向传播信号被组合在一起。
该解决方案易于实施。 但是这个解决方案忽略了候选框坐标的导数,所以是近似的。 在实验中,我们凭经验发现该方案产生了接近的结果,但与交替训练相比,训练时间减少了约 25-50%。
感觉这个好一点,虽然损失了部分精度,但是训练时间大幅减少
4步交替训练。
- 训练RPN。该网络使用ImageNet预训练模型进行初始化,并针对区域建议任务进行端到端微调。
- 使用step-1 RPN生成的候选区域,通过Fast R-CNN训练一个单独的检测网络。该检测网络也由ImageNet预训练模型初始化。此时,两个网络不共享卷积层。
- 使用检测器网络初始化RPN训练,但我们固定共享卷积层,只微调RPN特有的层。
- 保持共享卷积层固定,对Fast R-CNN的唯一层进行微调。因此,两个网络共享相同的卷积层并形成统一的网络。
类似的交替训练可以运行更多的迭代,但论文观察到改进几乎是忽略不计的。
实现细节
- 单尺度训练加推理
- 把图像的最短边缩放到600像素
- 锚框使用三个尺度(128x128,256x256,512x512),每个尺度长宽比三个比例(1:1,1:2,2:1)
- 不使用图像金字塔或者滤波器金字塔来预测区域的多个尺度(节省时间)
- 训练期间忽略跨越边界的锚框,不然在训练期间不收敛(对于1000x600的图片,这样处理之后大约剩余6k个锚框)
- 测试期间的跨边界的锚框,把超过边界的部分裁掉
- 使用
NMS在过滤部分锚框,阈值0.7(这样的话训练的时候还能剩下大约2k个候选框) - 在NMS之后,再挑选top-k个框(k=2k)。也就是说,训练的时候有2k个候选框,测试的时候不一定
算法使用的锚框允许大于基础感受野。这样的预测并非不可能——如果只有物体的中间可见,人们仍然可以粗略地推断出物体的范围。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









