 MCIS弱监督分割
MCIS弱监督分割





 MCIS是一种创新的弱监督语义分割方法,采用co-attention机制挖掘不同图像间的信息关联,提升分割精度。该方法引入对比注意力机制,有效增强目标类别特征的同时抑制背景干扰。
MCIS是一种创新的弱监督语义分割方法,采用co-attention机制挖掘不同图像间的信息关联,提升分割精度。该方法引入对比注意力机制,有效增强目标类别特征的同时抑制背景干扰。
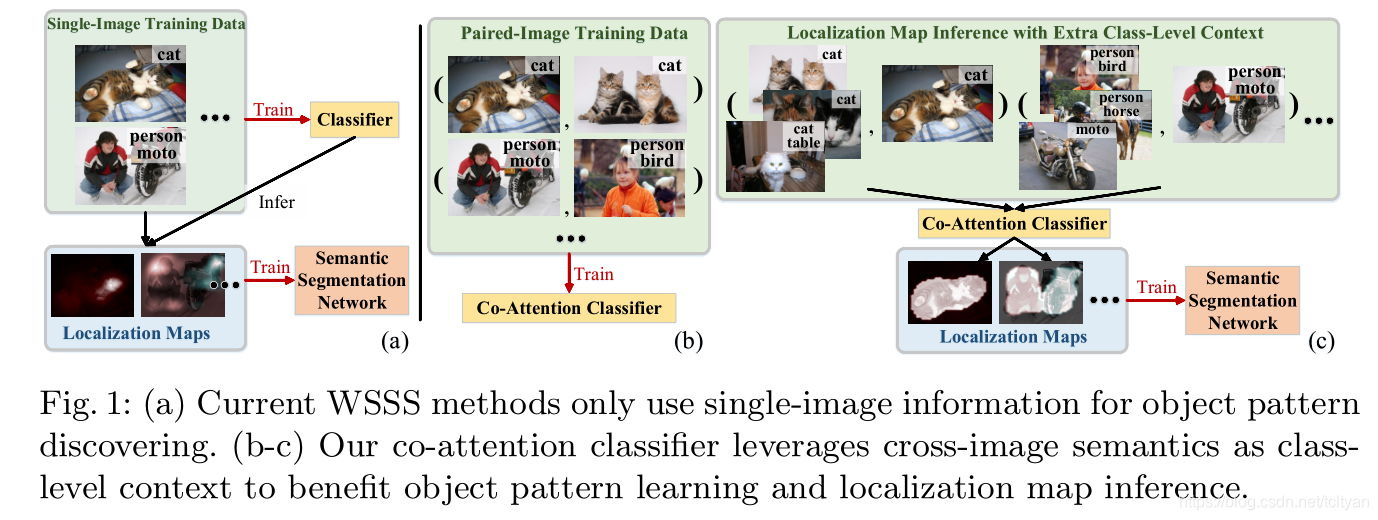
MCIS是ECCV2020的一篇文章,它比较少见地讨论了利用inter-image information去做弱监督语义分割。文章在工作的motivation处指出,当前图像级标签监督下的语义分割大多数都在挖掘intra-image information上面下功夫,主要的研究思路集中在怎样用图像级标签和分类网络去找更多、更好的上下文信息,但却完全忽略了不同照片之间的的信息关联。
如原文图1所示,(a)部分展示了传统分类网络的训练以及产生目标定位图的简单框架,即训练时完全按照标准的分类网络训练方式,推理产生目标定位图时也仅仅根据当前输入的单张图像直接输出。(b)部分展示了MCIS提出的co-attention训练架构,即在训练时成对输入图像,且保证图像对内存在至少一个共同类别;而对某一张图像进行推理产生分割伪标签时,也去随机采出若干张其他的相关图片,以实现协同分割。
原文的图2则展示了MCIS分类网络的详细结构。网络每次接收一对拥有共同类别的图像A和B,co-attention机制通过一种广义的可微分attention机制(普通的spatial-attention加上一个可以学习的权重矩阵)计算A与B的相似度矩阵(注意力加权图),然后以特征聚合的方式用A的特征组合出B的新特征,用B的特征组合出A的新特征,再用新特征去进一步计算CAM和分类向量。从直观上看,通过co-attention计算得到的新特征能够更好地学习并表示出某个类别的共性,因此在训练和推理阶段都能更好地促进分割任务的完成。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1175
1175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









