



 这篇博客介绍了XPath定位的基本方法,包括绝对定位与相对定位,详细讲解了以节点文本值和节点属性作为定位基准的各种函数,如text()、contains()、@属性名=’属性值’等。还探讨了多条件选取、多路径选择、not()函数的用法以及以轴为基准的相对定位策略。
这篇博客介绍了XPath定位的基本方法,包括绝对定位与相对定位,详细讲解了以节点文本值和节点属性作为定位基准的各种函数,如text()、contains()、@属性名=’属性值’等。还探讨了多条件选取、多路径选择、not()函数的用法以及以轴为基准的相对定位策略。
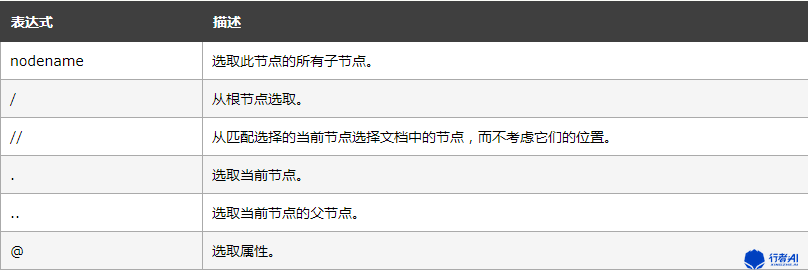
一、Xpath定位表达式的二种写法:
绝对定位:以“/”开头,相对的是Dom文档的根节点。如,“/html/body/div[2]/div/…”,由于绝对路径不可靠,在页面改动的时候很容易使定位信息失效,所以不建议使用。在定位信息不好选,而需要做调试的时候可以作为临时定位方式
相对定位:以“//”开头,相对的是当前的Dom文档,也可以是相对于当前所选取的节点对象。如,//*[@class=’hello’], 表示匹配当前Dom文档对象中所有class=’hello’的节点对象,或“//div[@class=’hello’]//*[contains(text(),’hi’)] 表示查找的节点在//div[@class=’hello’]下,没有层级关系,只要先定位//div[@class=’hello’]节点,在此节点之下所有包含文本为“hi”的节点都可以匹配到;
二、Xpath常用的定位方法:
以节点文本值作为定位基准:
1、text()函数 – 文本完全匹配(精确匹配)
写法://span[text()=’我是一个兵’]:匹配文本为“我是一个兵”的节点
该函数要求要查找的元素的文本内容与页面中元素实际的文本内容完全匹配,如,要匹配text()=’hello’, 则页面中节点的文本值必须是’hello’,且页面元素的文本内容不能有空格之类的
2、contains()函数 – 文本包含(模糊匹配)
写法: //a[contains(text(), ‘新建应用’)]:匹配文本包含“新建应用”的节点
该函数要求要查找的元素的文本值只要连续地完全包含在页面元素实际的文本中即可匹配,包含的位置不限。
排除包含指定文本值的节点:not(contains()):
//a[not(contains(text(),'创建您的产品')) and not(contains(text(),'立即注册使用'))]
文本定位用这二个基本就可以了
以节点属性作为定位基准:
1、属性值完全匹配(精确匹配) - //元素名[@属性名=’属性值’]:
2、属性值包含(模糊匹配) - //元素名[contains(@属性名, ‘属性值’)]:
starts-with(): 指定以什么开头,常用的可以是节点的文本值以什么开头,也可以是节点的属性值以什么开头
多条件选取定位 - and 、 or:
当用一个条件无法准确定位节点时,如有多个条件可选择,则可选择多条件:
and 、 or(不常用) 关键字
多路径选择:
多路径用“ | ”表示,可用于利用不同的条件选取同一个节点的选取,也可用于选择不同的节点
not()函数的简单用法:
用于排除包含指定文本的节点, not也可用于排除指定的节点本身
相对当前所选节点定位:
以轴为基准定位:
Xpath中一个很重要的东东,叫“轴”,所谓“轴”就是在我们不能直接定位到一个想要的元素时,可以选取一个好定位的元素作为“中心点”,再围绕这个中心点去定位我们的目标元素,这个“中心点”就是轴。
在轴定位中,我们不可避免地要用到的如下几个东东:
兄弟节点定位写法:
//div/following-sibling::span - 后兄弟节点
//span/preceding-sibling::div - 前兄弟节点
/ - 子节点
/../div - 父节点下的子节点
.. - 父节点


















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









