




 这篇博客介绍了如何利用Java字节流实现论文查重功能。通过读取GBK编码的TXT文件,比较论文与论文库的内容,当论文中含有论文库中的句子时,程序会输出匹配情况。注意文件的正确编码,避免出现乱码问题。
这篇博客介绍了如何利用Java字节流实现论文查重功能。通过读取GBK编码的TXT文件,比较论文与论文库的内容,当论文中含有论文库中的句子时,程序会输出匹配情况。注意文件的正确编码,避免出现乱码问题。
首先可以在目录下创建几个txt文件,如图,一个作为论文,几个作为论文库:

其中论文中包含论文库中的内容,现在在论文里放一句论文库中的句子
package com.oracle.core;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
public class Check
{
public static void main(String[] args) throws IOException
{
int count=0;
//获取到论文的信息
File file=new File("D:\\JAVA\\论文\\论文.txt");
InputStream in=new FileInputStream(file);
byte[] b=new byte[in.available()];
in.read(b);
String paper=new String(b,"GBK");
//获取论文库的信息
File dir=new File("D:\\JAVA\\论文\\论文");
File[] listFiles = dir.listFiles();
for(int i=0;i<listFiles.length;i++)
{
File f=listFiles[i];
InputStream in1=new FileInputStream(f);
byte[] b1=new byte[in1.available()];
in1.read(b1);
String papers=new String(b1,"GBK");
if(papers.contains(paper))
{
System.out.println(f.getName()+"存在重复内容");
count++;
}
}
System.out.println(count);
}
}
运行结果:
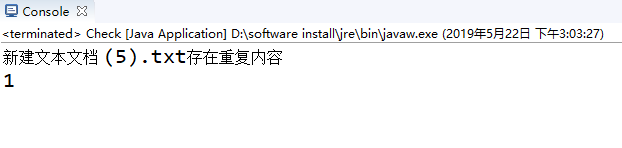
其中所有的文件保存编码为ANSI,代码中读取编码为GBK,否则会出现乱码的情况,程序会输出为0。

每一个汉字 都有对应的一个编码
GBK 常用汉字编码
GB2312 所有汉字编码 是GBK的扩充
UTF-8 万国码 默认的编码格式
不同的文字要用不同的编码去解析它


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









