 目标检测中的mAP指标详解
目标检测中的mAP指标详解





 本文介绍了目标检测模型评估的重要指标mAP,包括mAP的含义、为什么在目标检测中使用mAP、如何计算mAP,以及AP与IOU的概念。通过理解mAP和IOU,可以更好地评估模型在分类和定位任务上的性能。文中还提到了PASCAL VOC和COCO挑战赛中mAP的计算方式。
本文介绍了目标检测模型评估的重要指标mAP,包括mAP的含义、为什么在目标检测中使用mAP、如何计算mAP,以及AP与IOU的概念。通过理解mAP和IOU,可以更好地评估模型在分类和定位任务上的性能。文中还提到了PASCAL VOC和COCO挑战赛中mAP的计算方式。
如果你已经评估过目标检测模型或者读过这个领域的相关论文,那你一定碰到“平均均值精确率”或者“mAP”这个概念。mAP被目标检测竞赛(比如PASCAL VOC,ImageNet以及COCO )当做模型性能评估的一种方式。在这篇文章中,我将介绍:
- mAp是什么?
- 为什么mAP在目标检测中是一种有用的度量方式
- 对于特定的类别如何计算mAP
另外,我将提供计算mAP的代码方便读者可以在自己的项目中使用
检测模型的评估
在物体检测领域,模型评估是非常重要的,因为存在两个不同的任务需要度量:
- 决定一个物体是否存在一副图片中(分类)
- 决定物体在图片中的位置(定位,回归任务)
还有,在这些经典的数据集往往拥有多个类别并且类别的分布不是均匀的(比如含狗的图片比冰淇淋更多)。因此基于准确率的度量会带来偏差。同时,对错分类的风险评估也是很重要的。因此需要将一个自信度分数或者模型的分数与检测框联系在一起,在各种不同的标准的自信度下对模型的评估。
为了满足这些需求,AP(Average Precision)这个概念被引入。为了理解AP需要理解分类器的精确率与召回率。关于这些术语的的全面解释,可以查看wikipedia article。简洁的的说,精确率衡量分类器预测的所有物体中是真正物体的概率。如果模型的精准率接近1.0,表示预测到的物体有很高的可能是真实的物体。召回率衡量的是在数据集所有物体中分类器能够预测到的物体的概率。如果模型的召回率接近1.0,表示数据集中的所有物体有几乎都可以预测到。注意,精准率与召回率存在负相关,并且这两个衡量指标依赖于给定模型的分数阈值。举例来说,这张图片来自与TensorFlow物体检测API,如果我们对kite类别设置模型的分数阈值为50%,就可以获得7个正样本类别,但是如果我们设置我们的模型分数阈值为90%,就只存在4个正样本类别。
为了计算AP,对给定类别(比如人)精确率-召回率(PR)曲线可以通过调整模型的分数阈值计算模型的检测输出计算得到。PR曲线看起来是这样的:
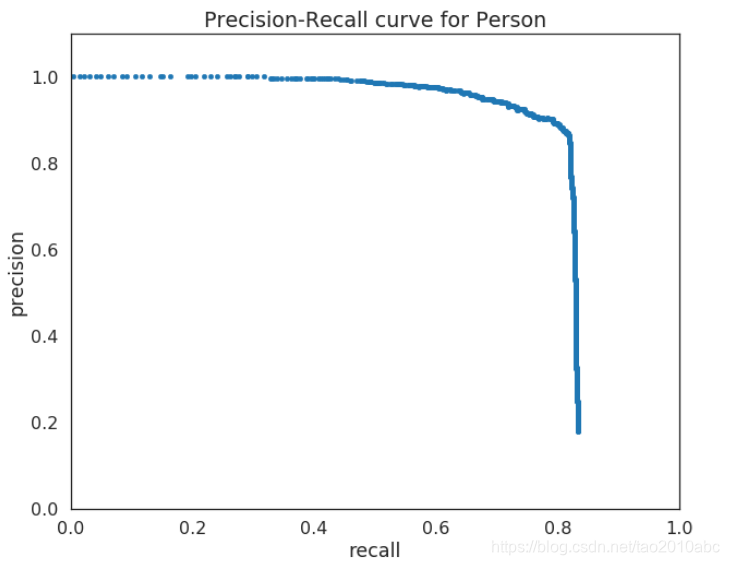
计算AP的最后一个步骤取所有召回率下的精准率的平均值(说明请查看Pascal Challenge paper4.2节),AP是对PR曲线的求和,更具体来说,AP曲线可以定义为在11个等距的召回率,
R
e
c
a
l
l
i
=
[
0
,
0.1
,
0.2
,
.
.
.
,
1.0
]
Recall_i=[0,0.1,0.2,...,1.0]
Recalli=[0,0.1,0.2,...,1.0],上精准率的平均值,如下公式:
A
P
=
1
11
∑
R
e
c
a
l
l
i
P
r
e
c
i
s
i
o
n
(
R
e
c
a
l
l
i
)
{AP}=\frac {1} {11}\sum_{Recall_i}{Precision(Recall_i)}
AP=111Recalli∑Precision(Recalli)
注意,召回率i时的精准率取超过召回率i时的最大精准率值,用公式表示如下:
P
r
e
c
i
s
i
o
n
(
R
e
c
a
l
l
i
)
=
max
i
<
r
R
e
c
a
l
l
r
Precision(Recall_i)=\max_{i<r} {Recall_r}
Precision(Recalli)=i<rmaxRecallr
到这里,我们已经仅仅讨论了分类任务。对于定位部分(预测的物体位置是否正确)我们需要考虑物体位置与模型预测的位置的重叠度。
定位与交并比(IOU)
为了评估模型的物体定位,我们首先需要决定模型预测物体位置好坏程度。通常可以通过在感兴趣的物体周围画检测框来决定,但是在一下情况下可以是多边形,甚至像素级别的分割。对于大部分情况,定位任务通常通过交并比来评估。
模型检测到物体是通过IOU阈值来决定是true还是false。每个目标检测竞赛采用的iou阈值都有所变化,比如在COCO挑战赛采用10不同的iou阈值,从0.5到0.95间隔是0.05。COCO数据集中人类别的在不同IOU阈值下的PR曲线如下图所示:
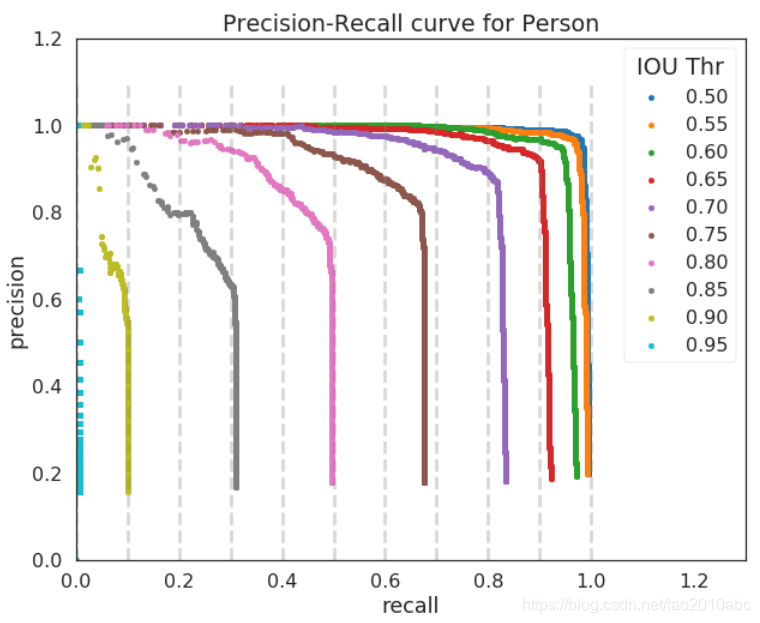
整合在一起
现在我们已经定义了AP并且已经看到IOU如何影响AP,mAP是通过计算所有类别的均值AP或者在不同IOU阈值下的所有类别的均值AP,计算的方式取决于竞赛,比如:
- PASCAL VOC2007 挑战赛仅仅使用iou为0.5的阈值,因此它的mAP是在iou为0.5时20类的均值AP
- COCO 2017挑战赛的mAP是在10个iou阈值下80类的均值AP
在10个iou阈值上进行平均而不是单单考虑iou大于0.5的情况,这有助于奖励在精确定位表现较好的模型



















 2122
2122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









