




 本文探讨了云边协同在分布式深度学习中的应用,包括DDNN网络架构、模型分割策略、资源优化及网络分区。文中提出了IONN和PerDNN结构以减少云端压力和边缘侧启动时间,以及DeepThings方法优化边缘侧计算和存储资源。此外,还讨论了数据协同、网络分区协同和业务功能分区面临的挑战,强调了数据安全、性能优化和多领域应用的重要性。
本文探讨了云边协同在分布式深度学习中的应用,包括DDNN网络架构、模型分割策略、资源优化及网络分区。文中提出了IONN和PerDNN结构以减少云端压力和边缘侧启动时间,以及DeepThings方法优化边缘侧计算和存储资源。此外,还讨论了数据协同、网络分区协同和业务功能分区面临的挑战,强调了数据安全、性能优化和多领域应用的重要性。
1云侧对边缘侧进行补充和验证
Suart等人 [30]提出分布式深度神经网络DDNN,该分布式神经网络可以根据云侧、边缘侧和终端侧不同节点的地理层级进行扩展与缩放。同时文中提出了六种不同的分布式深度网络如图。
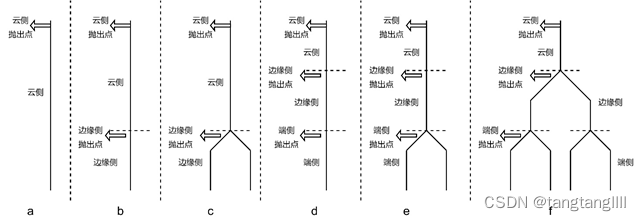
图1 云边协同分布式网络形式[34]
对云侧网络和边缘侧网络使用联合训练同时进行权重训练,分别得到各自权重并进行部署。边缘侧网络使用判定器判断特征信息是否足以进行准确的推理,当判定为错误推理时,边缘侧抛出数据至云侧,由云侧更复杂的网络进行推理,得到更准确的推理结果。边缘侧判定器使用正规化熵值确定,定义为: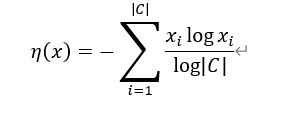
其中C为标注值,x为预测值,最终η值分布在[0,1]。设定抛出阈值T,边缘抛出的分类结果越多,系统准确性越低,但边缘侧算力资源利用率也就越高。为了使系统推理性能和准确性达到平衡,文中设置T=0.8,此时边缘抛出率为60%准确率为97%,系统达到最优的效率和准确性。对于多个边缘侧情况(如图(c)(e)(f)),文中还提出三种本地聚合器(local aggregation)以聚合不同来源数据,分别是最大池化(MP),平均池化(AP)和串联(CC)。其中边缘侧使用MP聚合云端使用CC聚合得到最佳分类准确率。该文虽然提出了一种提高边缘侧模型准确率的方案,但是并未对模型进行优化,同时边缘侧需要进行全部推理计算,某些不通过的结果需要在云侧进行重新计算,增加了整体计算量。
.2 基于模型分割的分布式云边协同
根据不同的场景需求,边缘侧往往使用查询的方法从云侧下载与场景相对应的完整网络模型自动部署,然后进行边缘推理(如fog nods [31]、cloudlet [32])。此种方式耗费大量网络带宽,更长的模型载入时间导致边缘侧的启动效率更慢。因此提出将模型进行分割,部分模型部署在边缘侧,另一部分部署在云侧的分布式协同网络。
其中一种是以网络层为单位的分割,确定网络分割点的过程一般可以分为三个步骤 [33]:
1)测量和建模不同DNN层的资源消耗成本以及中间DNN层之间的传输数据;
2)通过特定的层配置和网络带宽预测总成本;
3)根据延迟,能量需求等从候选划分点中选择最优的划分区域。
Jeong等人 [34]提出IONN结构,不同于传统的边缘服务器查询云端算法将网络模型从云侧发送至边缘节点的部署方式,IONN将网络划分为多个分区逐个发送至边缘侧。在执行推理需求时,优先选取边缘侧原有的模型分区进行复用。为了最优化网络分区上传顺序,提出使用图结构的启发式算法,如图2,以获得最佳的分区网络查询和边缘加载性能。具体做法是分别预测每层网络分区在云侧的执行时间,和边缘侧执行时间与云边数据传输的网络延迟时间总和,两者对比得到每层网络分区执行的最优策略。如果云侧网络层运行时间短,则数据直接在云侧运行。如果边缘侧复用或加载并运行网络层时间短,则网络层在边缘侧执行。文中也提出了网络分层策略。作者首先确定边缘侧网络层的最优加载偏好,即网络分区效率高但开销小的期望。通过迭代网络分区,分别计算网络在云侧和边侧的运行效率,提取在运行效率高的网络分区部署在边缘侧。文中使用Alexnet、Resnet、googleNet和MobileNet分别进行测试。最终效果显示在刚开始执行IONN时,边缘侧加载全部网络,整体运行速率较慢,但在经过几次加载后,由于复用边缘侧原有网络结构,上述模型加载时间全部下降至0.2秒内,加速效果较好。但是由于移动端侧可能在短时间内穿越不同网络网关,系统会经常遇到运行时长峰值,不利于系统稳定运行。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 504
504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









